BERT - (4) BERT 이해하기
BERT는 뛰어난 성능을 보이지만 아이러니하게도 어떤 요소로 인해 그러한 성능이 발휘되는지에 대해서는 정확히 판별할 수 없는 상황이다. 모델이 문맥을 이해하는 듯 하여 언어적인 지식을 습득하는 것 같은데, 파라미터 수와 모델의 depth로 인해 워낙 큰 모델이다보니 어떤 특성을 갖는지 분석하기가 어렵다.
따라서 BERT와 관련하여 연구된 논문 150가지 이상을 리뷰한 또 다른 논문이 등장하게 된다. 그 논문이 BERTology인데, 이 논문은 아래와 같은 내용을 중점적으로 다룬다.
- BERT 연구가 어떻게 진행되었고, 진행되고 있는지
- BERT가 어떻게 동작하는지, 어떤 정보를 학습하는지, input이 어떻게 represent되는지, 파라미터 거대화(overparameterization issue)와 그를 해결하기 위한 compression 방법으로 어떤 연구들이 진행되었는지
이 논문은 대부분의 섹션을 BERT가 어떤 지식을 보유하고 있는지 분석/정리한 내용으로 채웠다. 그 내용을 간략하게 요약하자면 아래와 같다.
Sytactic knowledge (언어 구조적인 이해)
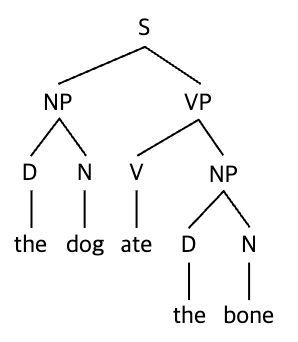
BERT의 Representation의 형태는 선형적이기 보다는 위계적(hierarchical)이라고 한다. 영어의 syntax를 도식화하면 주로 트리 형태로 표현하는데 주로 아래와 같은 위계적인 형태로 나타낸다. 문장 > 구/절 > 단어 단위로 하나의 문장의 구조를 나누어 표현한다. 이렇게 BERT가 학습한 syntactic structure은 self-attention weight에는 표현되지 않는다고 한다. 하지만 거꾸로 BERT의 token representation (= 단어 임베딩 결과)으로부터 복구할수 있다.
뿐만 아니라 BERT의 임베딩은 문장 내 단어의 위치에 대한 정보도 학습한다고 한다. 이는 Position embedding으로부터 기인한 특성일 것이다.
더 나아가 subject-predicate 관계도 MLM 과정에서 학습하게 된다고 하는데, subject는 주부, predicate는 술부로 주부가 어떤 행동/어떤 것인지를 서술하는 구절을 의미한다.
BERT는 syntactic structure을 이해하는 것처럼 보여지지만, BERT의 성능자체는 단어 순서를 바꾸거나, 문장을 자르거나, 주어나 목적어를 없애더라도 크게 변동하지 않는다고 한다. 이를 기반으로 논문에서는 BERT의 syntactic knowledge가 불완전(incomplete)하거나 문제를 해결함에 있어서 이 지식에 크게 의존하지 않는다는 결론을 내렸다.
Semantic knowledge (언어 의미적인 이해)
대부분의 BERT 연구는 semantic보다는 syntactic한 지식을 파악하는데에 초점이 맞춰져있다. 그 이유는 syntactic structure를 이해하고 있는지에 대해 파악하는 것보다 semantic knowledge를 보유하고 있는지 파악하는 것이 훨씬 어렵기 때문이다.
연구들의 결론은 BERT가 semantic role에 대한 지식이 있다는 것이다. 예를 들어 아래와 같은 세가지 유형의 문장이 있다고 한다면, BERT가 각 문장에 대한 선호를 다르게 표현한다는 것이다. (1 > 2 > 3 순)
(1) to tip a waiter
(2) to tip a chief
(3) to tip a robin
즉 tip이라는 동사가 어떤 대상(3가지 문장은 모두 명사로 동일)에 좀 더 적절한지에 대해 이해하고 있는 것이다.
하지만 숫자를 표현하는 데에는 능력이 조금 떨어진다고 한다. 예를 들어 소숫점은 거의 표현 성능이 좋지 못하다고 한다. 그에 따라 비슷한 값이더라도 (1.06, 1.08) 굉장히 다른 word chunk로 나뉘어지게 됨에 따라 숫자를 이해하는 데는 어려움이 있다고 한다.
World Knowledge (일반적인 지식)
BERT는 MLM학습으로 인해(=빈칸 채우기) 귀납적인 사고(Knowledge Induction)가 어느정도 가능하다고 한다. 그럼에도 불구하고 특정 개체(Object)의 추상적인 특성에 대해서 파악하거나 문장의 발화 의도(pragmatic inference)는 잘 파악하지 못한다.
특정 개체가 어떤 기능(affordance)을 하는지와 그 특성에 대해서는 추측하는 것 처럼 보이지만 그들간의 관계(relationship)에 대해서는 사고할 수 없다고 한다. (ex) 사람들이 집에 걸어들어가고, 집이 크다는 특성이 있다는건 알지만, 집이 사람보다 크다는 것은 알지 못한다.)
정리하자면 BERT는 syntactic, semantic, world knowledge를 어느정도 보유하고 있다고 정리할 수 있다. 하지만 콕 집어서 어떤 특성에 굉장히 발달되어있고 취약한지에 대해서는 아직까지 명확하지 않다.
논문에서는 추가로 BERT를 학습하는 데에 있어 몇 가지 팁을 제공한다.
- 모델 아키텍쳐를 선택할 땐 레이어의 수가 head의 수 보다 성능에서 중요한 역할을 한다. 이 둘은 각기 조정하면 다른 결과를 보여준다.
- NLP의 모델들이 늘 그렇듯, 깊은 모델일수록 다양한 task에서의 적용성이 떨어진다.
- self-attention heads를 늘리는 것은 성능에 별반 차이가 없어 이 수를 줄이는(pruning) 연구도 진행되고 있다.
그리고 BERT의 규모가 얼마나 커야하는지에 대해서도 간략하게 다룬다. 최근 Transformer 기반의 모델들이 파라미터 수가 꽤 거대하기 때문에 학습에 사용되는 비용이나 시간이 이슈로 떠오르고 있다.
The 110M parameters of base BERT are now dwarfed by 17B parameters of Turing-NLG (Microsoft, 2020), which is dwarfed by 175B of GPT-3 (Brown et al., 2020).
물론 인간 언어란 꽤 복잡해서 수많은 파라미터가 필요하다는 것이 당연한 생각일지도 모르겠지만, 현재의 모델들 중 대부분의 파라미터들은 중요한 역할을 하지 않고 있기 때문에 줄이는 방향이 적절하다는 것이 논문의 의견이다.
BERTology 외에 Attention Heads에 대해 깊이 있게 연구한 논문(What does BERT look at? An Analysis of BERT's Attention)도 BERT를 더 이해하는데 꽤 도움이 된다. 다른 연구들은 model output이나 vector representation(=probing classifier)에 초점이 맞춰져있지만, 이 논문은 Attention Head가 어떠한 언어적 지식을 캐치하는지에 대해 시각화하여 연구하였다. 시각화 코드도 GitHub에 올라가있어 내가 설계한 BERT의 Attention Heads에 대해 이해하고자 할 때도 유용하다.
Attention Head들의 행동(Behavior)
굉장히 많은 수의 BERT Attention들은 구분자(Deliminator)인 [SEP] 토큰에 높은 attention weight를 보인다. 그 이유에 대해서 논문은 의미 없는 attention이라고 말한다. 그 이유는 [SEP], [CLS] 은 masking되지 않고 늘 존재하기 때문이다. 따라서 반점(,), 온점(.), the와 같이 일반적인(common) token인 것처럼 이러한 토큰을 대하기 때문이다. 아래 그림에서와 같이 특정 head에서 간접목적어는 해당되는 동사에 attend하는 경향이 관찰되면서 동시에 그 외 다른 단어들(non-noun)은 모두 [SEP] 토큰에 attend하는 것을 볼 수 있다. 즉 [sep]토큰에 attend한다는 것은 별 다른 의미를 지니지 않는 것이다.

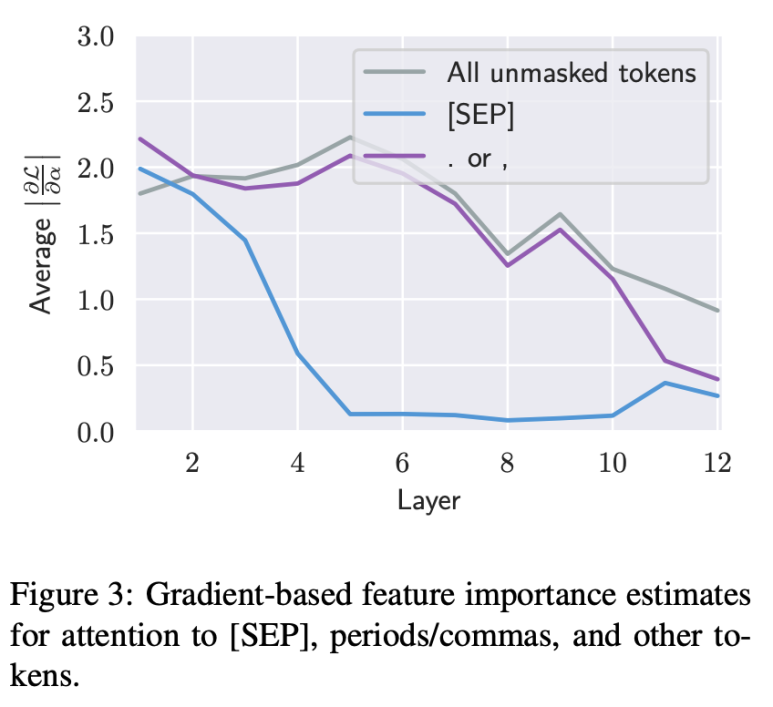
이를 증명하기 위해 피쳐 중요도(feature importance)를 파악하고자 attention의 gradient가 얼마나 변화하는지를 모니터링하였다. 즉 token의 attention weight를 바꾸는 것이 BERT의 성능을 바꾸는데 얼마나 영향이 있을지를 파악하였는데, 아래와 같이 layer 5 이후부터 gradient of attention이 낮아지기 시작하는 것으로 보아 [SEP] 토큰에 대해 attention weight가 높고 낮아지는 것이 BERT의 성능을 크게 변화시키지 않는다는 것을 발견하였다.
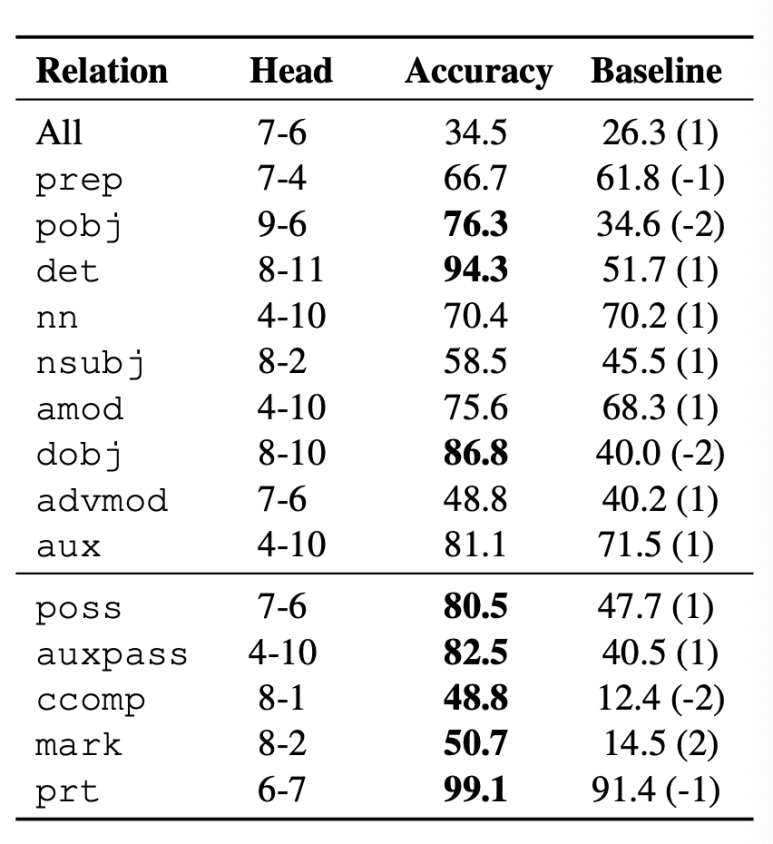
더 나아가 하나의 Head가 여러 관계(relationship)을 파악하는 데에 전반적으로 우수한 성능을 보이기보다는 특정 관계에 굉장히 맞춤화되어있다고 말한다. 예를 들어 동사의 간접목적어에 높은 attention을 보이는 head, 소유대명사의 객체에 대한 높은 attention을 보이는 head가 있는데 이들은 75% 이상의 정확도를 보인다고 한다. 이렇듯 유사한 패턴을 보이는 Head들이 하나 이상이기 때문에 클러스터링해볼 수도 있다.
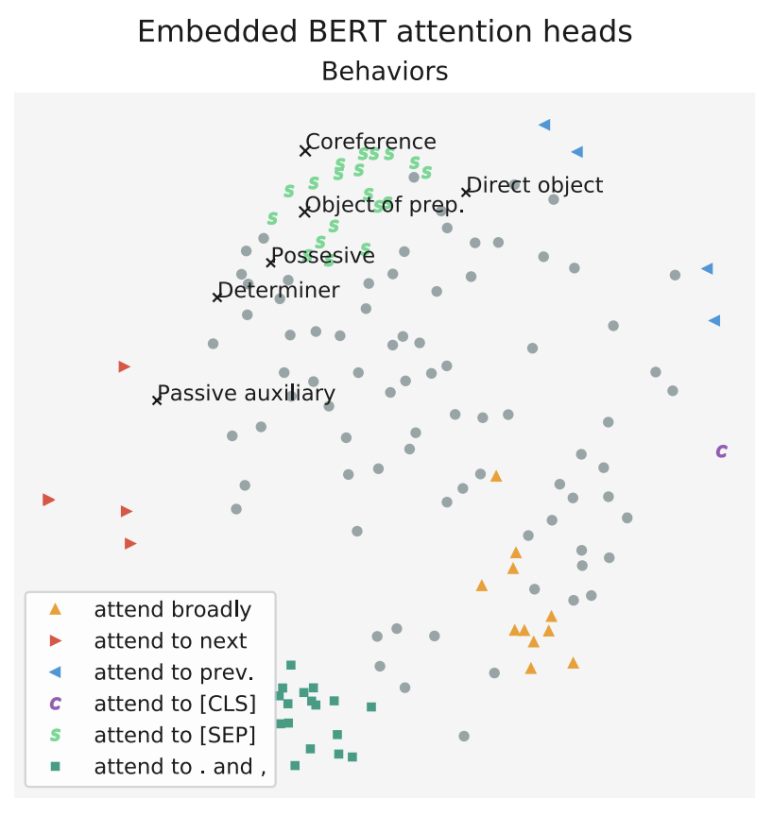
또한 같은 레이어에 있는 Attention head들은 유사하게 행동한다고 말한다.
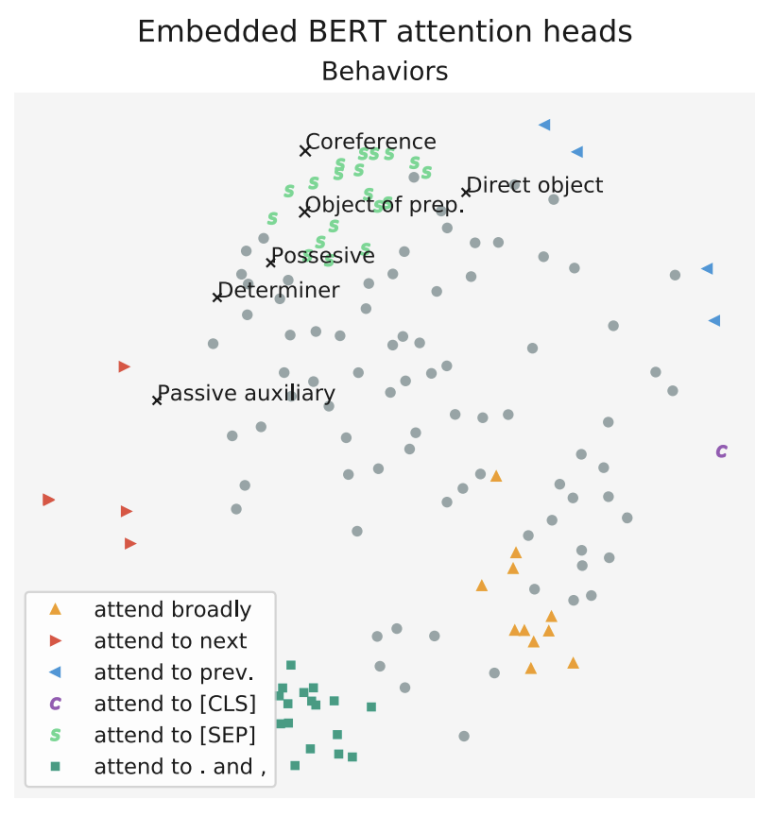
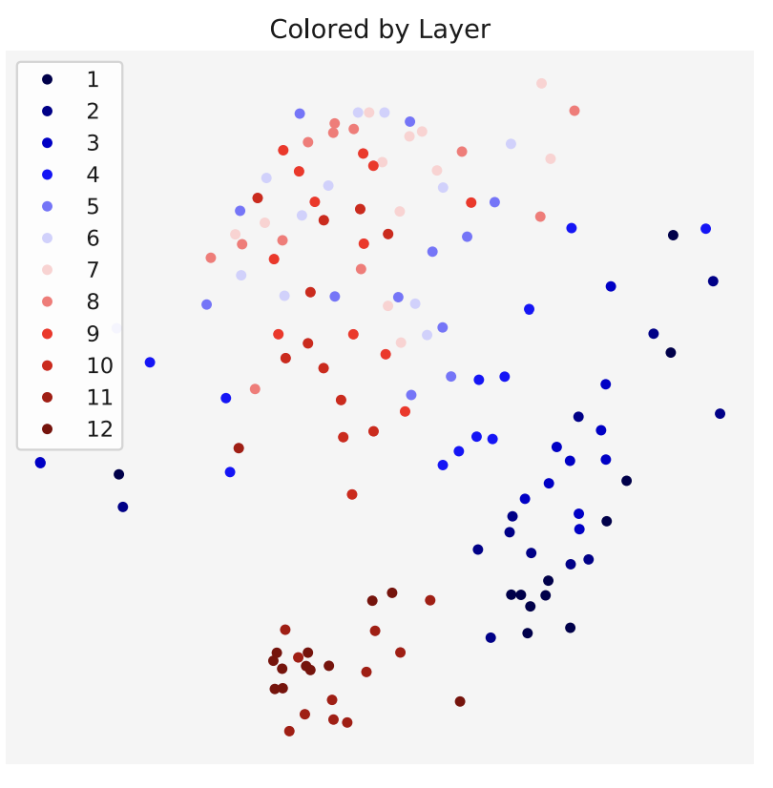
위와 같이 같은 레이어를 공유하는 Head들은 비슷한 패턴을 보이는 것으로 클러스터링 되는 것을 확인할 수 있다.
이렇게 BERT를 열심히 이해해보고자 노력함에도 명확하게 요인을 파악하기 어려운 것은 이 글에서 알아본 BERT가 학습하는 지식들이 collaborative하게 동작해서 성능을 완성하기 때문이다. 따라서 BERT가 어떤 지식들을 보유하고 있는지에 대해 간접적으로 파악할 수는 있지만, 우수한 성능이 단일 그 지식에서 기인했다고 보긴 어렵기 때문에 겉핡기 식으로 BERT에 대해 알아보는 연구가 진행되고 있다. 그럼에도 불구하고 BERT가 학습하는 언어적인 지식을 분류하고, 핵심 구성요소인 Attention Head들이 공통적인 weight pattern을 보이는지를 간단하게 살펴봄으로써 BERT에 한발짝 더 다가갈 수 있다.