Quantization
Quantization은 LLM이 화제가 되기 전에도 이미 모델의 complexity 나 cost를 줄이고자 하는 노력의 일환으로 연구가 되어왔던 분야이다. 물론 더 가벼운/저렴한 모델을 만들 때 quantization만이 유일한 대응책은 아니다. 모델 아키텍쳐 경량화 등의 방법도 있겠지만 quantization이 그 중에서도 가장 전후차이가 크다고 한다. LLM 모델들의 성능이 상승함에 따라 점차 일반화/서비스화 고민들이 많아지는 가운데, 갖춰지지 않은 대중적인 환경에서도 모델을 활용할 수 있는 방법에 대한 고민이 많아지는 듯 하다. 과거엔 IoT의 성장과 edge computing에 대한 관심도 한 몫했던 것 같다. 그럼 이번 글은 LLM에서 뜨거운 감자가 되고 있는 Quantization에 대해 간략히 살펴보자.
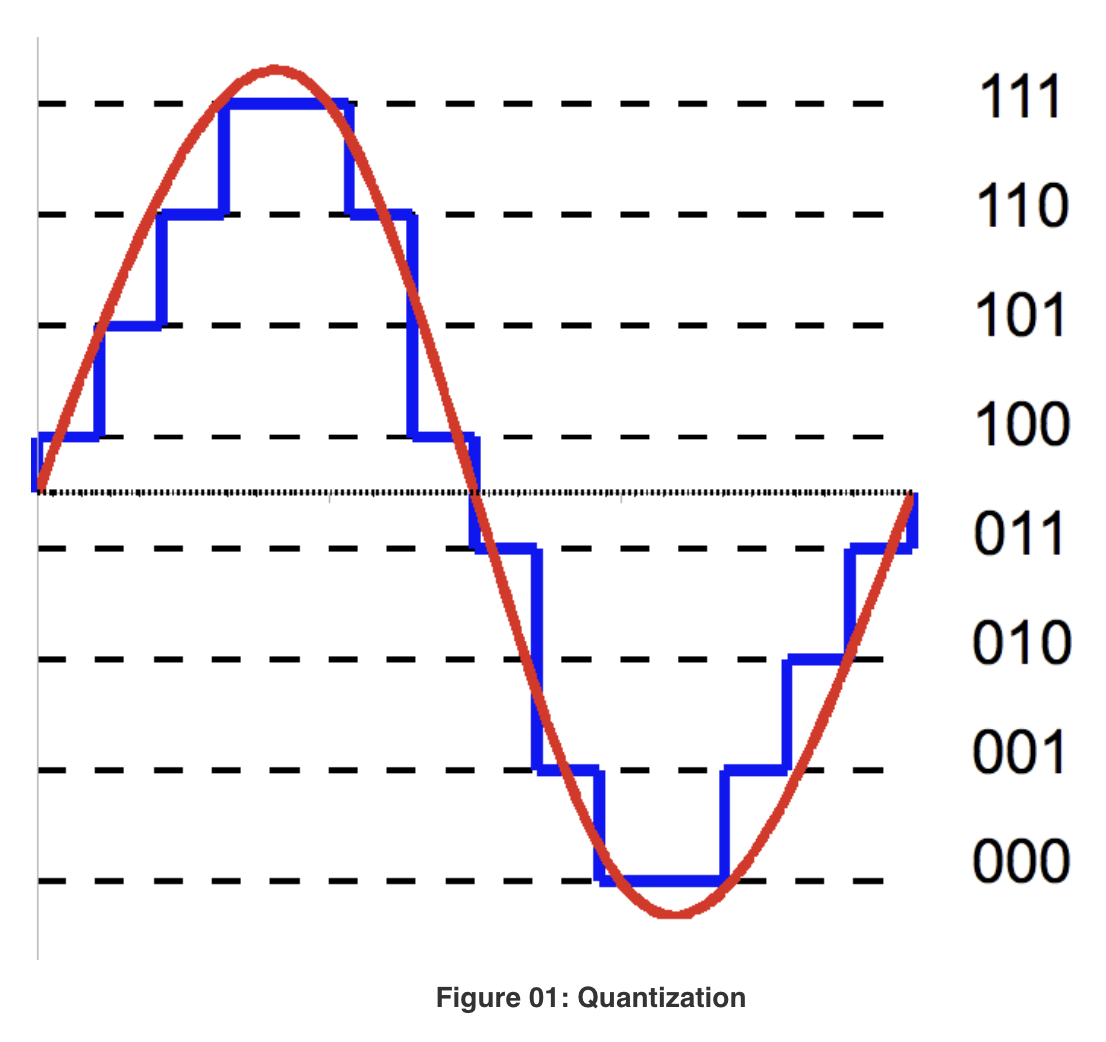
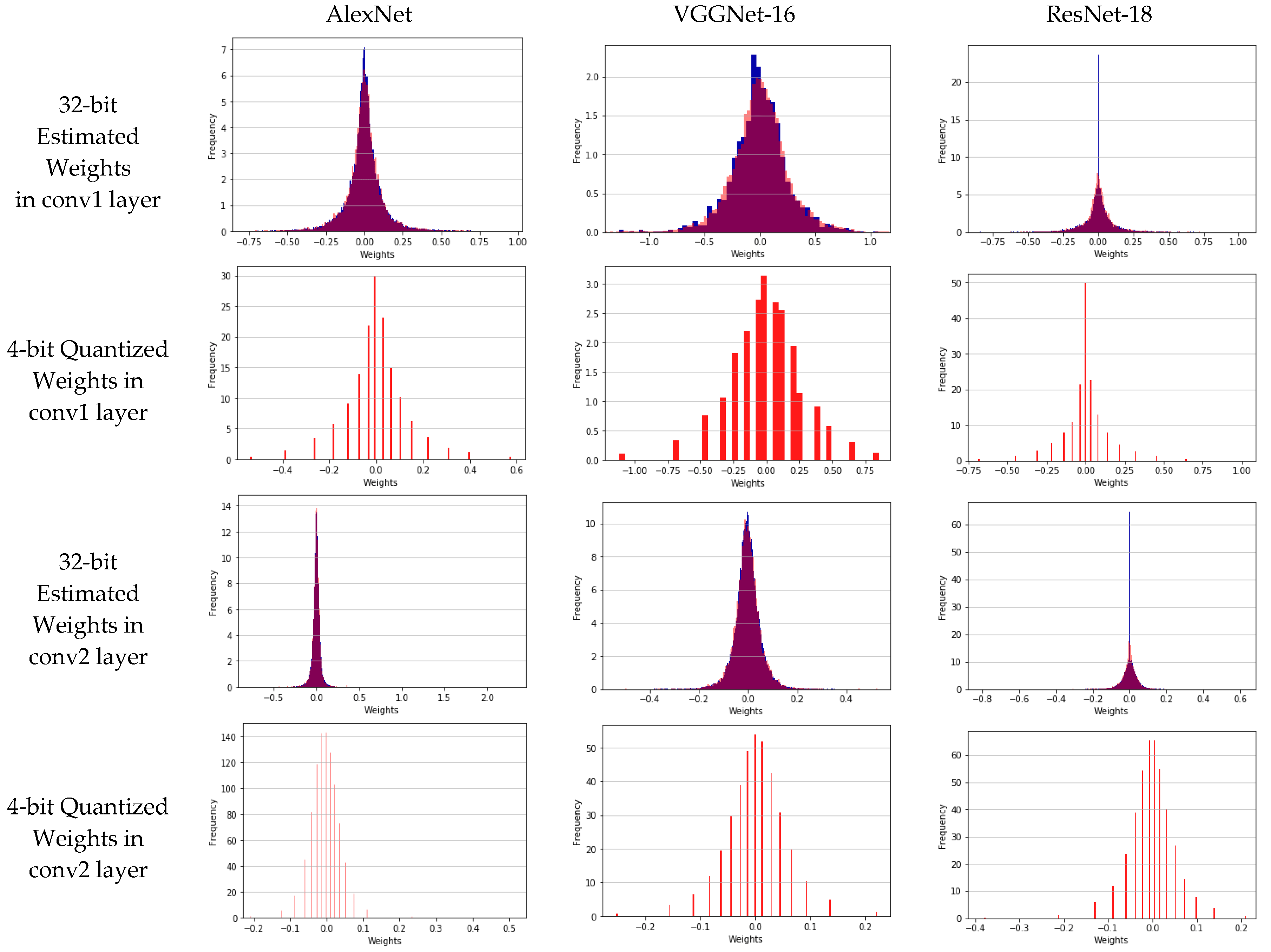
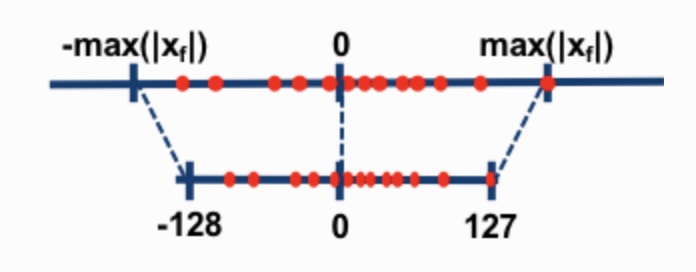
Quantization이란 일반적으로 lower precision bits로 매핑하는 것을 의미한다. 우리가 소숫점을 표현하는 Float32의 경우 부호(1bit), 지수부(8bit), 가수부(23bit)로 총 32bit를 사용하고 이를 higher precision bits라고 부른다. 반면 정수형인 int4는 4bit로 숫자를 표현하는 만큼 표현할 수 있는 숫자의 범위가 상대적으로 제한적이게 된다. 아래 왼쪽 그림을 보면 빨간 선(higher bits) 가 파란 선(lower bits)으로 값이 매핑되고 있는 것을 확인할 수 있다. 오른쪽 그림은 AlexNet, VGGNet과 같은 대중적인 모델들의 특정 layer 상의 가중치들을 quantization하여 전/후 분포를 시각화하였다. 이처럼 Quantization 과정으로 인해 데이터의 정확도는 낮아지게 되겠지만, 값을 표현하는 데에 사용하는 bit 수가 적어지는 만큼 메모리 사용량을 절감시킴으로써 모델의 학습/추론의 소요시간을 줄일 수 있게 되는 것이다. 이러한 trade-off 밸런스가 LLM과 같이 정말 방대하고 큰 모델인 경우 정확도 감소로 인한 피해가 상대적으로 크리티컬하지 않다고 한다. 따라서 정확도는 조금 떨어지더라도 모델의 활용도를 높이기 위해 quantization을 통해 모델의 추론 시간을 획기적으로 낮추는 것이다. * 하나 주의해야할 사항은 quantization은 forward pass만을 지원한다. 그래서 학습시간을 줄이는 것이 아니라 추론시간을 줄이는 것이 목표이다. inference 과정만 quantization 대상이 된다.
좀 더 풀어보자면, Neural net의 경우 모두가 알다시피 matrix multiplication이 많다. 매번 데이터를 Load → Multiply → Store 하는 일련의 프로세스에서 값에 대한 evaluation 과정이 꼭 발생한다. 이 때 load 단계에서의 quantize된 값을 사용하면 memory bandwidth를 낮춤으로써 load cost 확보할 수 있고, multiply시 quantized된 숫자들로 곱셈을 수행하면 complexity를 낮춤으로써 operation cost 확보할 수 있다.
이에 따라 Neural Net Quantization 방법들은 weight, activation function, intermediate value에서 값들을 low precision bits로 표현하여 전체 학습 및 추론 비용 절감하고자 한다. 실제로 Python에서 int형 숫자와 float형 숫자간 덧셈뺄셈을 수행할 때 time 라이브러리로 소요시간을 측정하게되면 확연하게 차이가 나는 것을 알 수 있다.
하물며 LLM은 resource-intensive하기 때문에 quantization이 더 중요해졌다. (LLM은 NLP, Vision 모델들과는 다르게 좀 더 일반적으로 사람들이 (실생활에서도) 활용도가 높은 모델이 되었기 때문에 on-device 즉 내 손안의 작은 컴퓨터에서도 모델을 활용할 수 있도록 경량화하고자 하는 움직임이 있다. 그리고 On-device에서는 Floating piont가 fixed-point보다 연산이 어렵다고 한다.)
특히 LLM은 computational latency보다는 runtime memory overhead가 크다고 한다. GPU hierarchy를 RAM → GPU VRAM → GPU Cache → GPU 순으로 보면, RAM에 거대한 weight 수를 지닌 모델을 로드하는게 더 오래 걸린다고 한다. 즉 memory bandwidth가 병목현상이 발생하는 지점인데, 이 때 32bit float에서 → 4bit int로 줄이면 8배 많은 weight를 GPU cache에 올릴 수 있어 속도가 최대 8배까지 증가될 수 있고, 1/8배 만큼의 VRAM 만을 사용하고도 추론할 수 있게 된다.
하지만 앞서 말했듯 quantization은 trade-off가 있다. 정확도가 줄어들기 때문에 모든 Layer마다 quantization을 적용하면 에러도 함께 누적되는거라 전체 레이어를 다 quantize하진 않고 특정 레이어만을 줄이게 된다. 그리고 quatization의 대상은 weight, activation이다.
그럼 Quantization은 어떻게 하는걸까? Quantization의 유형은 크게 아래와 같이 둘로 나뉜다.
- Uniform vs non-uniform
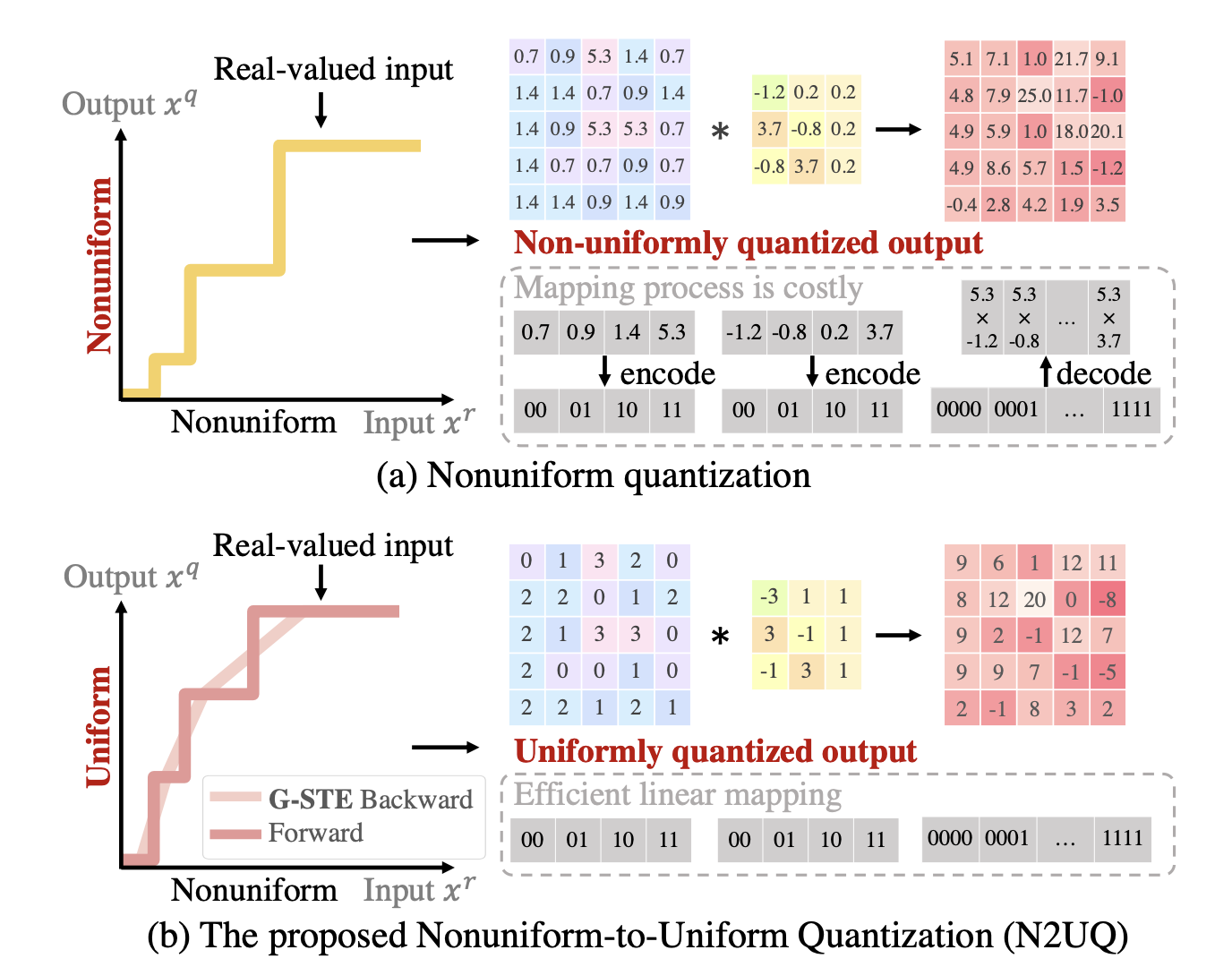
uniform quantization은 말 그대로 quantization level이 uniformly spaced 즉 stepsize가 동일하다. 위 그림에서 보면 input에 대해 output으로 변환 시 output의 값들의 차이가 uniform한 것이 uniform quantization이다. 윗 행이 non-uniform이라서 output 값이 소숫점으로 서로 scale 차이가 일정하지 않지만 아래 행을 보면 uniform하게 1씩 차이가 나는 값으로 quantize된 것을 볼 수 있다. 일반적으로 non-uniform이 좀 더 quantization error가 적은 편이라고 한다.
- Symmetric vs asymmetric
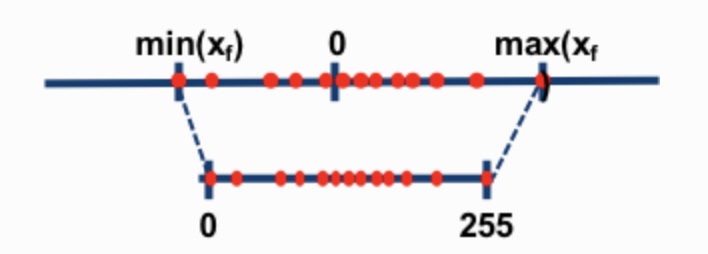
둘 간의 차이는 fixed offset의 유무 뿐이다. asymmetric인 경우 offset이 있지만 symmetric 은 없다. 즉 output value의 range를 정하는 min, max값이 절댓값은 동일하되 부호만 다를 경우 symmetric이라고 부른다. 위에서 보면 첫 번째는 asymmetric인데 오른쪽으로 좀 더 치우쳐져서 mapping되고 있지만 아래쪽은 output value가 음의 영역과 양의 영역이 밸런스가 맞춰져있다.
그리고 Quantization을 모델 전체 프로세스 중에서 어떤 단계에 적용하느냐에 따라 아래와 같이 구분된다.
- Post-training quantization (PTQ)
network가 학습된 이후에 scaling해주는 방식이다. weight, activation의 scale은 원래 데이터셋의 activation distribution, weight distribution을 기반으로 디자인된다.

- Quantization-aware training (QAT)
아래 flow를 보면 network를 완전히 학습시킨 뒤, Quantize(Q), Dequantize(DQ) 노드를 추가해서 학습이 완료된 모델에 epoch를 추가하는 방식처럼 추가학습(further training)시킨다. 이 때 Q/DQ 노드들은 input으로 들어온 x에 대해 양자화된 x로 바꾸었을 때의 quantization loss를 계산하고, back propagation하여 loss를 줄이는 방식으로 모델을 튜닝한다. 아래에 표기된 것처럼 어떻게 보면 fine-tuning이라고도 볼 수 있다. 당연하게도 이 방법이 학습 단계에서 미리 inference 시에 양자화했을 때의 loss를 simulation해볼 수 있기 때문에 PTQ보다는 정확도가 좋은 편이다.

일반적인 경우 LLM을 직접 학습하고 튜닝하기엔 쉽지 않기(접근권한도 없을 뿐더러..) 때문에 오픈소스형 LLM들을 PTQ 방식으로 양자화하여 상황에 맞게 사용하게 된다. QAT는 LLM을 개발하는 쪽에서 더 많이 사용하는 방식일 것이다.
PTQ를 구현하는 가장 간단한 방법은 Round-to-nearest(RTN)으로 각 weight를 가장 가까운 quantization grid로 매핑시켜주는 것이다. 맨 처음에 봤던 그림이 RTN 방식이 아닐까 싶다. CNN과 같이 상대적으로 규모가 작은 모델에서는 잘 동작하지 않지만 LLM과 같이 파라미터의 수가 과하게 많은 경우 잘 맞다고 한다.
물론 RTN은 너무 간단한 방식이라 양자화해서 얻는 이득보다 감퇴하는 성능에서 오는 피해가 더 클 수 있다. 이 방식 외에 greedy하게 optimal한 quantized weight를 구하는 방식도 있다고 한다. 이 알고리즘은 (여느 greedy한 알고리즘이 그렇듯) time complexity가 각 layer의 데이터 size의 4제곱(row=col일 경우) 수준이기 때문에 LLM에는 적합하지 않다.
이보다 더 좋은 결과를 낼 수 있는 quantization 방법들이 계속 연구되고 있다. 그 중에는 LoRA를 활용한 Quantization 방법인 QLoRA가 있다. LoRA 방식에서 NF4(4-bit NormalFloat Quantization), Double Quantization, Paged Optimizer를 추가하여 본디 Float32 형식의 65B 모델이 VRAM 260GB가 필요하지만 이를 4bits단위의 VRAM 48GB까지 획기적으로 메모리 필요량을 줄였다. NF4와 double quantization만을 간단히 살펴보자면, NF4는 정규분포처럼 생긴 데이터에 최적인 방법인데 quantile quantization 방법의 일종으로서 quantile로 bin을 나누어 그 bin의 midpoint를 quantized value로 매핑하게 된다. Double quantization이란 원래 weight만을 quantization했다면 여기에 더 나아가 scale 파라미터들(양자화 상수)도 양자화를 한 것이다. 이로인해 모델의 block size를 더 급격하게 줄일 수 있었다.
시간 들여 읽을만한 좋은 자료 하나를 마지막으로 남기고 Quantization에 관한 글을 이만 갈무리한다!
https://towardsdatascience.com/introduction-to-weight-quantization-2494701b9c0c?gi=8bcabfede56b