
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 메타버스
- aws자격증
- BERT이해
- 클라우드자격증
- transformer
- AWS
- Collaborative Filtering Bandit
- BANDiT
- 미국석사
- 플랫폼
- chatGPT
- HTTP
- 네트워크
- MLOps
- 머신러닝 파이프라인
- 중국플랫폼
- llm
- COFIBA
- 머신러닝
- nlp
- docker
- 자연어처리
- MAB
- 클라우드
- 언어모델
- BERT
- TFX
- RecSys
- 추천시스템
- MSCS
- Today
- Total
Julie의 Tech 블로그
MAB기반 추천시스템 : Collaborative Filtering Bandits - (2) 본문
지난번에는 CF와 stochastic MAB를 합친 COFIBA모델을 간단히 소개했다.
이번에는 그 모델의 pseudo code를 보면서 로직을 정확히 이해해보고자 한다.
우선 간략히 모델의 알고리즘 로직 순서를 요약하면 아래와 같다.
1. t번째 라운드에서 모델은 특정 유저에게 추천 가능한 아이템 리스트 중 가장 기대보상이 큰 아이템을 선택
2. 선택 결과에 따라 유저로부터 실제 보상 결과를 받음
3. 실제 보상 결과에 따라 모델이 업데이트됨
3-1. 모델 파라미터 업데이트
3-2. 유저 클러스터, 아이템 클러스터 순으로 업데이트
4. 1-3 반복
좀 더 자세하게 알아보자.
Intial Setting : input, output
각 용어별 정의는 아래와 같다.
U는 유저 그룹, I는 콘텐츠 그룹이라고 한다.
유저 그룹 내에는 n명의 유저가 존재하며, 전체 유저 집합은 U로 정의된다.
콘텐츠 그룹 내에는 아이템 x들이 존재한다. (x는 content vector / feature vector라고도 불린다.)

출처 : https://arxiv.org/pdf/1502.03473.pdf
COFIBA 모델은 매 라운드에서 추천 결과를 결정해야하는 유저 i와 추천 가능한 아이템 리스트를 input받는다.
COFIBA모델은 최종적으로 유저 i에게 아이템 리스트 중 하나의 아이템을 선택하여 추천(output)해야한다.
How to recommend
알고리즘은 k번째 라운드가 시작되었을 때, 우선 input으로 전달받은 추천 가능한 아이템 리스트 내에 존재하는 아이템 개별로 유저 클러스터(neighbor set, Nk)을 구성한다.
이 유저 클러스터를 기반으로 Ui의 추정치 벡터인 w를 계산하게 되는데, 이때 행렬 M과 벡터 b가 사용된다.
M과 b는 모두 동일 클러스터 내 유저별 M, b의 합산값이다.
이렇게 계산된 복합(compound) weight 벡터 w와 이 w 값에 대한 신뢰도 구간인 CB를 계산한다.
(w는 unknown 벡터인 Ui에 대한 추정치이며, 이 추정치에 대한 오차를 CB로 계산한다.)
* CB는 Ui에 대한 LLS(linear least square) approximation 값이다

weight 벡터를 아이템 벡터 x와 내적하고, CB값을 더한 최종 값 중 가장 큰 값을 지닌 아이템을 선택한다.
즉 이 값은 보상에 대한 예측치인 것이다.
앞서 우리는 Ui와 x를 내적하고, noise e를 더하면 보상의 예측치로 정의했다.

하지만 Ui는 우리가 모르는 벡터이므로, w라는 추정 벡터를 대신 사용하는 것이다.
모델은 예측된 보상값이 가장 큰 아이템을 유저에게 추천하고, 유저의 반응에 따라 payoff를 받게 된다.
Updates - Parameter
보상을 받은 알고리즘은 그 보상을 바탕으로 기존의 파라미터들을 업데이트한다.

M과 b는 각각 선택된 아이템과 선택된 아이템 x 보상값으로 업데이트된다.
파라미터를 업데이트한 뒤에는 유저와 아이템 클러스터를 업데이트해주어야한다.
유저와 아이템 클러스터의 업데이트는 그래프의 edge를 삭제해주는 방향으로 진행된다.
Updates - User Clusters
유저 클러스터에서의 업데이트는 선택된 아이템과 연관된 부분만 업데이트된다.

유저 클러스터에서 edge를 삭제해야한다고 판단할 때는 두 보상 예측치의 간차가 각 CB값 합보다 클 때이다.
동일한 아이템에 대한 두 유저의 기대 보상치의 차이가 수용 가능한 오차의 범위보다 더 크게 발생하기 때문이다.
앞서 동일한 클러스터 내에 속한 유저는 아래와 같이 정의하였었던 것을 회고해보자.

위 정의에 따르면 두 유저의 특정 아이템 선호가 유사하다고 판단할 수 없는 것이다.
따라서 두 유저간 edge를 삭제하는 것이다.
Updates - Item Clusters
아이템 클러스터의 업데이트는 유저 클러스터의 업데이트에 따른 변화를 바탕으로 진행된다.
유저 클러스터 업데이트가 이루어진 후, 일전에 서로 유사하다고 여겨진 두 아이템에 따른 유저 클러스터가 서로 상당히 다르게 변했을때만 이루어진다.

유저 클러스터 업데이트 전에는 Xh와 Xt(선택된 아이템) 간 직접적인(direct) 연결이 있었다고 했을 때,
유저쪽에서 업데이트(edge deletion)이 발생한 뒤 Xh에 따른 유저 셋과 Xt간의 유저 셋이 더 이상 유사하지 않게 되었다. 이 때 아이템 그래프에서 Xh와 Xt간의 연결고리도 삭제하는 것이다.
앞선 글에서 '두 아이템 각각에 속한 유저 그룹이 서로 동일하다면, 두 아이템이 유사하다'는 가정에 따른 결과이다.
유사선호 유저 그룹이 더 이상 동일하지 않으니, 두 아이템도 유사하지 않다고 보는 것이다.
하지만 이 결과로 반드시 두 아이템이 다른 클러스터 내에 속한다고 판단할 순 없다.
두 아이템이 동일 클러스터 내 비간접적(indirectly)으로 연결되어있을 수도 있기 때문이다.
User, Item clusters updates in Figure

가장 처음에 위와 같이 유저 클러스터와 아이템 클러스터가 구성되어있다고 해보자.
유저는 총 6명이며 아이템은 총 8개인 환경이다.
시간이 흘러 t번째 라운드에서는 아래와 같이 각 클러스터가 구성되었다.
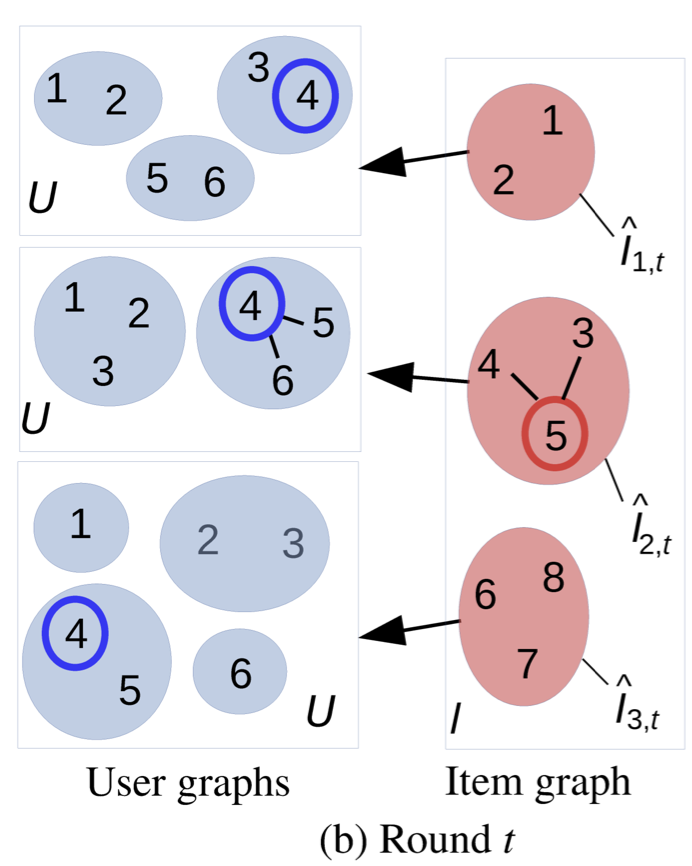
이번에는 유저 클러스터가 총 3개 구성되었고, 아이템 클러스터도 총 3개 구성되었다.
앞서 살펴보았던 유저 클러스터의 정의가 다시 상기되는 그림이다.
각 유저 클러스터는 특정 아이템에 의해 도출된(induced) 클러스터이며, 단일 아이템 클러스터와 연결되어있다.
이 라운드에서 모델은 유저 4번에 대해 아이템 5번을 추천하는 것으로 결론을 내렸다고 해보자.
그럼 유저 클러스터와 아이템 클러스터에 대한 업데이트를 진행해야하는데,
아이템 5번이 존재하는 클러스터와 유저 4번이 존재하는 클러스터 중 아이템 5번을 선호하는 클러스터를 업데이트해야한다.
바로 2번째 유저 클러스터와 2번째 아이템 클러스터이다.
우선 유저 클러스터부터 업데이트해보자.
유저 4번에 대해 유저 5, 6이 동일 클러스터로 연결되어있다. 이 두 edge 각각에 대해 삭제해야하는지 여부를 판단해야한다.
이 때 (4, 6)이 연결된 edge를 삭제해야된다고 해보자. (4, 6번의 2번째 아이템 클러스터에 대한 선호가 더 이상 유사하지 않게 되었을 때)
이 결과에 따라 아이템 클러스터도 업데이트해야한다.
아이템 클러스터는 아이템 5번에 대해 3, 4번이 동일 클러스터 내에 존재한다.
이 3, 4번에 대해 각각 삭제해야하는지 여부를 판단하게 된다.
만약 유저 4에 대한 업데이트로 아이템 3번에 의한 선호 유저 그룹이 더 이상 아이템 5번과 동일하지 않을 때, (3,5) edge를 삭제한다.
이에 따라 아래와 같이 3번과 4,5번 아이템 클러스터가 각각 나뉘게 되고, 3번 클러스터에 대해서는 초기(degenerate) 유저그룹을 지정한다.

다음 글에서는 모델의 성능을 평가하기 위한 테스트 데이터와 그에 따른 실험 결과를 간단하게 리뷰할 것이다.
'Tech > RecSys' 카테고리의 다른 글
| MAB기반 추천시스템 : Stochastic Bandits, CFB (0) | 2021.07.04 |
|---|---|
| MAB기반 추천시스템 : Collaborative Filtering Bandits - (3) (0) | 2021.07.04 |
| MAB기반 추천시스템 : Collaborative Filtering Bandits - (1) (0) | 2021.07.04 |
| MAB 문제란? - Multi-Armed Bandit (2) (0) | 2021.06.18 |
| MAB - 넷플릭스 artwork personalization 사례 (0) | 2021.06.03 |



