
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 메타버스
- 머신러닝 파이프라인
- docker
- BANDiT
- RecSys
- 자연어처리
- 클라우드자격증
- 네트워크
- llm
- BERT이해
- HTTP
- 클라우드
- MLOps
- MSCS
- COFIBA
- chatGPT
- 플랫폼
- 추천시스템
- BERT
- TFX
- MAB
- aws자격증
- transformer
- 머신러닝
- 언어모델
- AWS
- Collaborative Filtering Bandit
- nlp
- 미국석사
- 중국플랫폼
- Today
- Total
Julie의 Tech 블로그
MAB기반 추천시스템 : Stochastic Bandits, MCRS 본문
지난번 논문 리뷰에 이어 stochastic bandit 모델을 한 번 더 살펴볼 것이다. 이번 논문은 좀 더 간단하다.
A contextual-bandit Algorithm for Mobile Context-Aware Recommender System
Introduction
본 논문은 moblie context-aware recommender system, 줄여서 CARS 추천시스템 모델이다.
요즈음 사람들은 휴대폰에 많은 콘텐츠를 저장하고 사용하는데, 그 저장소에는 빈번히 새로운 콘텐츠가 추가되고, 기존 콘텐츠가 삭제된다.
따라서 추천시스템은 신규 문서의 중요성을 빠르게 잡아내고, 오래된 문서의 가치를 낮추는 것에 쉬이 적응해야한다.
지금껏 많은 논문들은 환경과 유저의 행동을 연산하는 데에 집중했지만, 정작 유저의 콘텐츠 선호 변화는 신경쓰지 않았다고 한다.
따라서 이러한 환경에 걸맞는 Bandit 기반 추천 시스템을 고안하게 되었다고 한다.
논문은 Bandit 알고리즘의 가장 기본적인 𝜀-greedy알고리즘에 context를 추가한 Contextual 𝜀-greedy 알고리즘을 소개한다.
𝜀-greedy 알고리즘의 가장 큰 단점은 적절한 𝜀 값을 정하는 것이 어렵다는 것인데, 이 값을 Context에 대한 정보를 추가하여 부여하는 방식이다.
제목에도 쓰여있듯이, 모델의 이름은 Mobile Context-Aware Recommender System으로 MCRS로 줄여 부른다.
Key Notions
논문 알고리즘을 본격적으로 들여다보기 전에, 주요 용어의 정의와 예시에 대해 살펴보자.
- User model :
상황 S와 각 상황 S에서의 유저 선호 UP 정보로 구성된 셋(set)
- User preference(UP) :
유저의 선호는 유저의 행동에 의해 추론될 수 있는 정보이다.
UP는 유저 선호를 특정하는 구성요소 c로 구성된 단일 벡터로 표현한다.
- Context :
장소, 시간, 사회라는 세 가지의 ontology로 구성된 context를 의미한다.
- Situation :
유저의 Context의 인스턴스이다. xi, xj, xk 각각 인스턴스처럼 여겨진다.
예시를 들면, 2021년 1월 1일, 위도와 경도가 (48.89, 2.23)인 위치에서 A친구를 만나기로 했다면, 해당 상황의 데이터는 ("48.89,2.23", "Jan_1_2021", "A")라는 형식으로 표현될 수 있다는 것이다.
- High-Level Critical Situations (HCLS) :
유저가 알고리즘이 추천할 수 있는 가장 최선의 정보를 필요로하는 상황이다.
처한 상황에 따라 exploration, exploitation 전략을 고정하는 것인데, 위에서 정의한 Situation 중에서 특별한 몇 가지 경우는 이 집합에 속하게 된다.예를 들어 업무공간과 같은 공적인 환경에서는 유저의 선호에 따른 가장 좋은 추천인 exploitation, 친구들과 함께 정보를 공유하는 공간에서는 유저 선호와 무관해도 좋은 exploration 전략을 취한다.
논문은 HCLS 특성만 알고리즘에 잘 반영하더라도 성능이 무척 개선될 수 있음을 강조하고 있다.

MCRS Model
논문이 제안하는 MCRS모델은 유저의 상황(Situation) 정보를 녹여낸 Contextual bandit 알고리즘이다.
Iteration, 즉 trial 이 총 T회까지 있을 때, 알고리즘은 각 t마다 아래와 같은 단계를 거친다.
1단계 : St는 유저의 현재 상황이라고 했을 때, PS는 과거 상황의 집합이다. PS에서 St와 가장 유사한 Sp를 선정하게 된다.

* similarity metric은 dimension j에 대한 상황 t의 인스턴스와 상황 c의 인스턴스간의 Ontology 유사도를 계산하는 것이다.
** 알파값은 실험단계에서는 모든 dimension에 대해 상수 1로 지정되었다.
*** LCS는 인스턴스 c와 t간의 Least Common Subsumer이고, deph는 ontology root까지 연결된 노드 수이다.

예를 들어 위 상황에서 "boat"와 "car"의 LCS는 Vehicle이다. 가장 가까운 조상을 구하는 것이기 때문이다. (Object는 최고조상)
2단계 : document의 집합 D에서 Situation Sp에 따른 추천 결과가 Dp라고 했을 때, 유저의 feedback에 따라 document Dp의 reward값을 조정한다.
3단계 : 유저의 feedback(클릭시 1, 미클릭시 0)에 따라 알고리즘이 업데이트가 되고, 여기서 reward는 타 논문과 동일하게 CTR이 사용된다.
Contextual-𝜀-greedy 알고리즘
𝜀확률만큼 exploration, 1-𝜀만큼 exploitation 을 결정하는 알고리즘은 동일하다.
논문에서 중요하게 여기는 HCLS의 집합 원소 중 하나인 Sm과 현재 상황 St의 유사도를 계산한다.
1) St와 Sm의 유사도가 threshold B보다 클 경우, 현재 상황은 중요한 것으로 판단할 수 있다.
따라서 수확하는 전략을 취한다(𝜀 = 0). HCLS집합에 St가 새로운 원소로 추가된다.
2) threshold B보다 작을 경우, 현재 상황은 중요하다고 볼 수 없기 때문에, exploration 전략을 취한다.
이 때 𝜀 값은 두 상황의 유사도를 threshold로 나눈, 즉 상대적 중요도 값으로 매겨진다.
즉 이 알고리즘은 St와 Sm의 유사도가 높아질수록 보수적으로 exploration을 하게 되는 것이다.
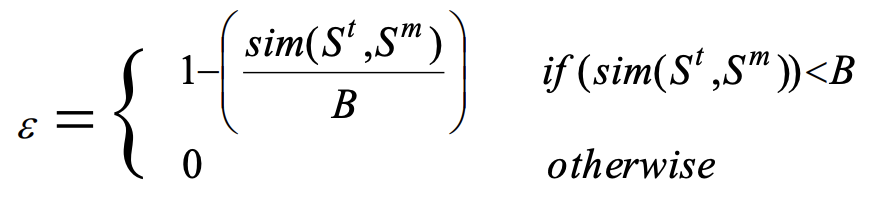
논문의 실험 섹션을 살펴보면 threshold B값은 데이터에 따라 최적 값을 찾아내어 지정하는 듯 하다.
Experiment
논문은 diary study, 즉 일기 연구 데이터를 사용한다. 각 일기에는 상황, 날짜, 사회에 대한 정보가 담겨 있어 ontology 분석이 가능하다.
유사도 측정 기준인 B 값을 구하고자 데이터에서 직접 수기로 유사한 상황끼리 그룹핑했다고 한다.
그 결과에 따라 아래와 같은 도표를 plotting하였고, [0, 3]구간의 B 값이 0.849 정확도를 보였다고 한다.

이번에는 Contextual-𝜀-greedy 알고리즘의 성능을 보기 위해 HCLS 상황을 정의했다고 한다.
100회 이상 발생했던 상황들은 중요하다고 정의하였고, 이 상황들을 묶어 HCLS 집합으로 정의했다. 또한 이 상황에서 조회되었던 10,000건 document를 수집하였다.
이렇게 실험 환경을 구성해둔 뒤, 𝜀-greedy, 𝜀-beginning, 𝜀-decreasing 알고리즘과 각각 CTR 성능을 비교하였다.

당연한 결과겠지만, contextual-𝜀-greedy알고리즘은 빠르게 최적의 𝜀값을 알아내어 최고의 수렴속도를 보여준다.
𝜀-beginning알고리즘이 가장 최악의 성능을 보여주고 있는데, 그 이유는 exploration을 초기에만 허용하기 때문이다.
결론
논문은 Mobile환경에서의 유저 상황에 따른 Document추천을 최적화할 수 있는 추천 시스템 알고리즘을 제안한다.
조금 오래된 논문이라, 𝜀-greedy알고리즘을 조금 더 개선한 버전을 담고 있는데, 유저의 상황으로 정의된 Context 정보를 추가하였다.
𝜀-greedy알고리즘의 가장 큰 결점인 𝜀를 선제적으로 지정하는 특성을 개선하는 모델이었는데,
유저에게 exploitation이 반드시 필요한 상황일 경우 exploitation을 수행할 수 있게끔 하여 보상의 총합을 최적화한다.
'exploitation이 필요한 상황(HCLS)'은 사전에 정의된 정보이고, 이 상황과 현재 상황이 유사한 것인지를 연산하는 Similarity metric이 도입된다.
location, time, social 세 가지로 구성된 유저의 상황 정보는 Ontology로 분석되어 상호간 연산도를 계산하게 된다.
정확한 알고리즘 로직이 공개되진 않았지만, 유추하기로는 위 정보가 graph형태로 담겨 각 노드간의 연결 길이 등으로 두 상황의 유사도를 연산하게 된다.
이러한 모델은 현재 상황이 중요한 상황일수록 exploration을 자제하는 방향으로 학습되고, 최대한 exploitation을 취해 보상 최적화를 한다.
그 결과로 기존 모델인 𝜀-greedy알고리즘이나, 그 변형인 𝜀-beginning, 𝜀-decreasing 알고리즘보다 높은 성능을 보여준다.
'Tech > RecSys' 카테고리의 다른 글
| 추천시스템 - (1) 개요 (0) | 2021.09.13 |
|---|---|
| Contextual Bandit - 이커머스몰 최적 추천시스템, CAMARS (0) | 2021.07.30 |
| Neural Collaborative Filtering, NCF - 코드리뷰, python3.x 버전 (0) | 2021.07.05 |
| MAB기반 추천시스템 : Stochastic Bandits, CFB (0) | 2021.07.04 |
| MAB기반 추천시스템 : Collaborative Filtering Bandits - (3) (0) | 2021.07.04 |


