
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 머신러닝 파이프라인
- 언어모델
- 메타버스
- 머신러닝
- AWS
- MLOps
- COFIBA
- transformer
- 네트워크
- docker
- 중국플랫폼
- BANDiT
- 자연어처리
- Collaborative Filtering Bandit
- chatGPT
- 클라우드
- 미국석사
- BERT이해
- MAB
- HTTP
- 클라우드자격증
- RecSys
- BERT
- 플랫폼
- nlp
- TFX
- llm
- aws자격증
- MSCS
- 추천시스템
- Today
- Total
Julie의 Tech 블로그
데이터 경진대회에서 유용하게 써먹을 수 있는 EDA 방법들 본문
이번 글에는 지금까지 경진대회에 참가해보면서 이리저리 리서치하고 써봤던 EDA 테크닉을 몇 개 정리하려고 한다.
EDA의 결과에 따라 어떤 feature를 사용할 것인지, 어떤 종류의 모델이 적합한지에 대해 파악할 수 있기 때문에 EDA는 무척 중요한 프로세스다.
필자는 대부분 예측(Prediction) 문제를 다루는 대회를 경험해봐서, 예측 모델을 빌딩하는 것을 베이스에 두고 글을 써내려갈 것이다.
여느 대회에 참여하게 되면 가장 먼저 학습데이터를 다운받는 것부터 시작한다.
데이터 명세서까지 제공해주는 친절한 대회라면, 그 명세서를 옆에 두고 데이터를 개괄적으로 둘러보기 시작할 것이다.
이를 바탕으로 가장 먼저 시도해보는 것들은 기본적인 EDA이다.
1. 데이터 이해 - 데이터 사이즈, 스키마 이해
가장 먼저 학습데이터를 다운받아 작업환경(주피터랩 등)에 풀어두고, 기본적인 데이터 분포와 크기를 확인한다.
이와 관련된 가장 대표적인 코드들을 몇 개 작성해보면 아래와 같다.
// 데이터에 대한 전반적인 정보를 표시 : 행과 열의 크기, 컬럼명, 컬럼을 구성하는 값의 자료형 등을 출력
df.info()
// 데이터를 무작위로 n개만큼 뽑아 보여줌
df.sample(5)
// 각 컬럼별 기본적인 통계치를 보여줌. parameter로 별도의 옵션을 지정하지 않으면 numeric 컬럼만 조회됨
df.describe()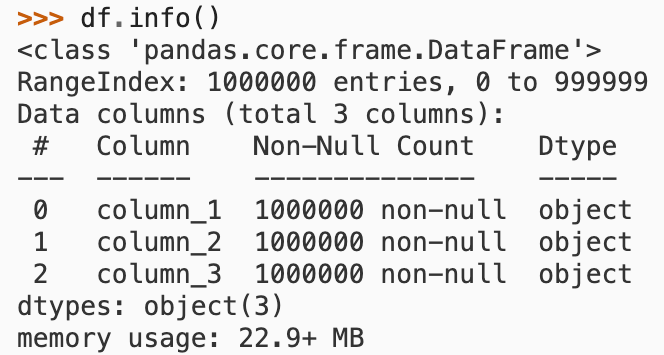

가장 처음 데이터를 보게 되면, 우선 데이터의 사이즈와 스키마를 파악해야할 것이다.
우리는 제공된 데이터를 기반으로 최대한 모델을 개발해야되기 때문에 얼마나 다양한 정보(=컬럼, feature)이 있고,
그 데이터 샘플 크기(=컬럼별 수집된 자료 수)는 얼마만큼 있는지에 대한 파악이 필요하다.
더 나아가 각 컬럼에 데이터가 얼마나 담겨있고(null값은 얼마나 있는지, 동일한 데이터는 얼마나 있는지),
어떤 자료형(문자형인지, array타입인지 등)인지, 수치형일 경우 분포가 어떻게 구성되는지 파악해야할 필요가 있다.
위 코드는 간단하게 확인하기 위한 용도이며, 컬럼별 분포와 같은 경우 좀 더 상세하게 살펴보기 위해 차트를 그려 살펴보기도 한다.
예를 들어 Nueral Network와 같은 모델을 빌딩하게 되면, 결측치(null값)를 제거하고 정규화를 거쳐야하기 때문에 사전에 좀 더 살펴보기도 한다.
아래 코드는 컬럼별 히스토그램 차트를 그리는 코드인데, 이외에 컬럼별 박스 차트를 그려 확인하는 방법도 있다.
// 각 컬럼별 분포 확인 - histogram
train_df.hist(figsize=(20,16))
plt.show()
// 각 컬럼별 분포 확인 - boxplot
train_df.boxplot()

2. 결측치 및 상관관계 확인
다음은 결측치와 변수간 상관관계를 확인하는 단계이다.
어느 정도 데이터에 대해 기본적인 이해가 되었고, 모델링 전 전처리 때 필요한 처리가 어떤 것들이 있을지 파악하기 위해 진행한다.
일부 Tree형 모델의 경우 결측치 제거를 해주지 않아도 되지만, NN과 같은 모델을 빌딩하게 되면 결측치 처리가 필요할 것이다.
성능 개선을 위해 결측치를 최빈값 혹은 중앙값으로 대체해주는 경우도 있다.
# 결과 중 결측치 비율을 보고 어느 컬럼을 삭제하고 어느 컬럼을 대체할지를 판단
df_missing = train_df.copy()
np.sum(df_missing.isnull())
missing_number = df_missing.isnull().sum().sort_values(ascending=False)
missing_percentage = missing_number/len(df_missing)
missing_info = pd.concat([missing_number,missing_percentage], axis=1, keys=['missing number','missing percentage'])
missing_info.head(10)위 코드는 학습 데이터의 각 컬럼별 결측치 비율이 어느정도 되는지 dataframe으로 output을 담아 보여주는 코드이다.
위 코드를 통해 결측치가 많은 컬럼의 경우 삭제를 하거나 특정 값으로 대체하는 전처리를 할 판단을 할 수 있다.
다음은 상관관계이다. 상관관계가 높은 변수의 경우 (일반적으로 0.7 이상으로 보는 듯 하다) 한 쪽 변수를 drop하거나, 전체 변수를 PCA하여 전혀 새로운 변수로 가공하여 사용하기도 한다.
# heatmap으로 각 변수별 상관관계도를 표현
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.figure(figsize=(18,10))
sns.heatmap(train_df.corr(), annot=True)위 코드는 시각적으로 히트맵을 통해 변수의 상관관계를 보는 것이고, 컬럼 수가 많은 큰 데이터일 경우 한 눈에 파악하기가 어렵다.
따라서 아래 코드를 통해 상관관계가 높은 순으로 dataframe 형태로 output을 만들어 손쉽게 볼 수 있도록 추출할 수 있다.
// 상관관계 데이터 추출
df_train_corr = train_df.corr().abs().unstack().sort_values(kind="quicksort").reset_index()
df_train_corr.rename(columns={"level_0": "Feature 1", "level_1": "Feature 2", 0: 'Correlation Coefficient'}, inplace=True)
df_train_corr.drop(df_train_corr.iloc[1::2].index, inplace=True)
df_train_corr_nd = df_train_corr.drop(df_train_corr[df_train_corr['Correlation Coefficient'] == 1.0].index)
// 상관관계가 높은 순서대로 추출
corr_na = df_train_corr_nd[~df_train_corr_nd['Correlation Coefficient'].isna()]
// Target 변수와의 상관관계는 drop
corr_na[np.logical_and(corr_na['Feature 1'] != 'Target Column name', corr_na['Feature 2'] != 'Target Column name')].tail(20)
3. 변수 중요도 파악 - Target 변수와 feature 변수 간 연관관계 분석
나머지 단계들의 경우 일반적인 다른 대회에도 해당되지만, 이 단계는 특히나 예측 모델을 세우기 전 가장 중요한 EDA라고 할 수 있다.
내가 예측하고자 하는 변수인 Target과 그에 관한 정보인 feature 변수간의 연관도를 살펴보는 것인데, 여러가지 방법이 있을 수 있다.
필자가 시도해봤던 방법들은
1) 각 컬럼의 사분위수 구간별 Target이 1인 데이터 수 파악 (Kaggle 우승자 코드를 참고하였음)
2) 각 컬럼별 구간을 임의로 나누어 Target이 1인 데이터 수를 파악
인데, 1이 좀 더 통계학적으로 접근하여 파악할 수 있다.
아래는 Kaggle의 대표적인 대회 중 하나인 "Santander Customer Transaction" 우승자 코드 중 일부를 변형하여 가져왔다.
플랏팅할 데이터의 모든 변수가 수치형이라는 가정 하에 코드가 정상적으로 작동한다.
변형된 구간은 사분위수 구간 사이에 값이 없을 경우, 즉 예를 들어 1사분위수와 2사분위 수 값이 동일하여 1사분위수와 2사분위 수 사이의 값이 없을 때에는 둘 중 하나의 분포로 대체하는 코드를 삽입해두었다.
해당 코드를 사용한 대회의 데이터는 컬럼별로 데이터 분포가 쏠린 경우가 많았기 때문에 추가적인 예외처리가 필요했었다.
// 사분위 구간별 Target 분포 (Target Distribution in Quartiles)
// np.zeros((컬럼수, 9)) << 로 변경하여 사용하면 된다.
df_qdist = pd.DataFrame(np.zeros((5, 9)), columns=['Quartile 1 Positives', 'Quartile 2 Positives', 'Quartile 3 Positives', 'Quartile 4 Positives',
'Quartile 1 Positive Percentage', 'Quartile 2 Positive Percentage', 'Quartile 3 Positive Percentage', 'Quartile 4 Positive Percentage',
'Quartile Order'])
// feature 변수 중 결과를 뽑을 컬럼명을 넣어준다. 이 컬럼 수는 위에서 지정한 np.zeros((컬럼수,))와 동일해야한다.
features = [col for col in df_T.columns.values.tolist() if col in ['col1', 'col2', 'col3', 'col4', 'col5']]
quartiles = np.arange(0, 1, 0.25)
df_qdist.index = features
for i, feature in enumerate(features):
for j, quartile in enumerate(quartiles):
target_counts = df_T[np.logical_and(df_T[feature] >= df_T[feature].quantile(q=quartile),
df_T[feature] < df_T[feature].quantile(q=quartile + 0.25))].CHURN.value_counts()
#print("feature: ", feature, " quartile (", quartile, "~", (quartile+0.25), ") has target as below : ")
if len(target_counts) != 0: // 만약 사분위수 구간 사이에 값이 없을 경우 (이전 사분위수와 다음 사분위수 값이 동일할 경우)
ones_per = target_counts[1] / (target_counts[0] + target_counts[1]) * 100
#print(ones_per)
df_qdist.iloc[i, j] = target_counts[1]
df_qdist.iloc[i, j + 4] = ones_per
else :
target_count = df_T[df_T[feature] == df_T[feature].quantile(q=quartile)].CHURN.value_counts()
ones_per = target_count[1] / (target_count[0] + target_count[1]) * 100
df_qdist.iloc[i, j] = target_count[1]
df_qdist.iloc[i, j + 4] = ones_per
pers = df_qdist.columns.tolist()[4:-1]
for i, index in enumerate(df_qdist.index):
order = df_qdist[pers].iloc[[i]].sort_values(by=index, ascending=False, axis=1).columns
order_str = ''.join([col[9] for col in order])
df_qdist.iloc[i, 8] = order_str
df_qdist = df_qdist.round(2)
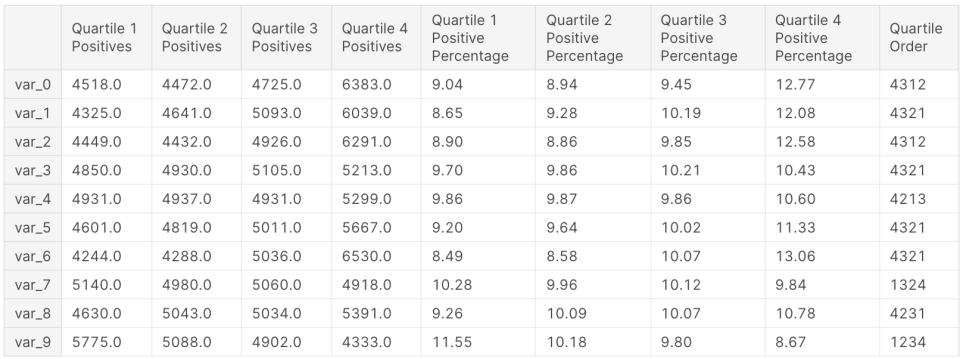
df_qdist[10:]위 코드를 돌리면 아래와 같은 형태로 데이터를 추출할 수 있는데, 표를 해석하는 방법에 대해 조금 설명해두겠다.
각 변수별로 4사분위수 구간별 Target이 1인 데이터 수와, 그 비율이 표기되어있다. 마지막 컬럼인 Quartile Order은 비율이 높은 순으로 사분위수 넘버링이 적혀있다. 아래 데이터에서 볼 수 있듯이 대부분의 컬럼은 4사분위수부터 1사분위수 순으로 Target이 1일 확률이 높다고 볼 수 있다.
따라서 변수별 값이 높을 수록 Target이 1일 확률이 높다는 것이다.
필자는 이러한 데이터를 어떤 모델을 쓸 것인지를 결정할 수 있는 단서로 사용하기도 했다.
예를 들어 사분위수별로 비율 차이가 클 경우 Target이 1일 확률이 높은 데이터 구간이 있다고 해석했다.
비율이 높은 구간은 일종의 linear한 구분선을 줄 수 있다는 의미이기도 해서, Tree형 모델이나 SVM과 같은 모델을 후보로 두었다.
Neural Network와 같이 복잡도가 높은 모델을 구성하지 않더라도, feature별 특정 구간을 잘 구분하기만 하면 Target을 예측할 확률이 높다고 생각했기 때문이다.
4. 데이터 불균형 확인 - Train set vs Test set 분포 차이 확인, Target 변수 분포 확인
본 단계는 모델의 성능을 개선하기 위해 필요하다.
머신러닝 모델은 학습데이터에 의존하기 때문에 학습데이터의 분포와 예측할 테스트 데이터의 분포가 다를 경우 모델 성능이 기대만큼 나오기 어려울 수 있다.
Kaggle 대회에서도 이 부분이 가장 중요한 이슈라고 한다. 일부 대회의 경우 추론 데이터를 랜덤으로 샘플링하여 모델을 채점하기도 한다.
이 때 학습 데이터에 맞추어 모델이 학습된 경우 overfitting이 되어 추론 데이터를 올바르게 예측하지 못할 수 있기 때문이다.
아래는 마찬가지로 Kaggle의 대표적인 대회 중 하나인 "Santander Customer Transaction" 우승자 코드를 그대로 가져왔다.
플랏팅할 데이터의 모든 변수가 수치형이라는 가정 하에 코드가 정상적으로 작동한다.
// 학습데이터와 테스트데이터 간의 변수 분포 (Feature Distributions in Training and Test Set)
features = [col for col in train_df.columns.tolist() if col in ['col1', 'col2', 'col3', 'col4', 'col5']]
// 컬럼수에 맞게 nrows, ncols 조정
fig, axs = plt.subplots(nrows=2, ncols=4, figsize=(25, 25))
for i, feature in enumerate(features, 1):
plt.subplot(2, 4, i)
sns.kdeplot(train_df[feature], bw_method='silverman', label='Training Set', shade=True)
sns.kdeplot(test_df[feature], bw_method='silverman', label='Test Set', shade=True)
plt.tick_params(axis='x', which='major', labelsize=8)
plt.tick_params(axis='y', which='major', labelsize=8)
plt.legend(loc='upper right')
plt.title('Distribution of {} in Training and Test Set'.format(feature))
plt.show()위 코드를 실행하게 되면 각 컬럼별 Train, test 데이터셋에서의 분포를 표현해준다. 이 분포를 통해 차이가 큰 변수가 있을 경우 불균형에 따른 데이터 조정이 필요하다.

다음으로는 Target 변수의 불균형에 대해 살펴볼 필요가 있다.
일반적으로 예측하고자 하는 정답지가 훨씬 적게 분포해있다. 보통 5% 미만으로 존재한다.
아래는 Target 변수의 분포에 대해 추출하는 코드이다.
import matplotlib.pyplot as plt
import seaborn as sns
ones = train_df['target'].value_counts()['O']
zeros = train_df['target'].value_counts()['X']
ones_per = ones / train_df.shape[0] * 100
zeros_per = zeros / train_df.shape[0] * 100
print('{} out of {} rows are Class 1 and it is the {:.2f}% of the dataset.'.format(ones, train_df.shape[0], ones_per))
print('{} out of {} rows are Class 0 and it is the {:.2f}% of the dataset.'.format(zeros, train_df.shape[0], zeros_per))
plt.figure(figsize=(8, 6))
sns.countplot(train_df['target'])
plt.xlabel('Target')
plt.xticks((0, 1), ['Class 0 ({0:.2f}%)'.format(ones_per), 'Class 1 ({0:.2f}%)'.format(zeros_per)])
plt.ylabel('Count')
plt.title('Training Set Target Distribution')
plt.show()위 코드를 통해 0인 정답지와 1인 정답지 간의 불균형이 어느 정도 존재하는지를 파악한 뒤, 그 차이가 클 경우 데이터 보정이 필요하다.
일반적으로 데이터 수가 충분히 커서 줄여도 될 경우 0인 정답지 수를 undersampling하거나,
데이터 수가 크지 않은 경우 1인 정답지를 특정 알고리즘을 통해 임의로 oversampling하는 방법이 있다.
Oversampling이든, Undersampling이든 무작위로 데이터를 조정하기 때문에 분포가 틀어질 수 있다는 것을 감안해야한다.
일반적으로 데이터 수가 많으면 많을 수록 모델의 예측 성능이 높아지기 때문에 데이터 수가 적을 경우 oversampling을 해보는 것이 좋다.
참고로 필자는 특정 대회에서 Oversampling을 데이터 전체에 대해 진행할 경우 모델 성능이 상당히 어그러졌던 적이 있었다.
따라서 모델에 input으로 줄 학습데이터에 대해서만 oversampling을 진행하여 그 문제를 해소했던 경험이 있다.
모델링은 결국 경험의 싸움이다. 그 과정에서 어느 정도 운도 뒷받침되는 것 같다. 특히 파라미터 최적화(Optimization)하는 과정은 더욱 그렇다.
경험상 대회에서 아래와 같은 단계로 진행할 경우 체계적으로 진행할 수 있는 듯 하여 정리해보았다.
1. 데이터를 기본적으로 이해하는 과정을 거친다. EDA를 통해 몇 가지 insight를 뽑는다.
2. 대회에서 수상 기준으로 잡는 Metric에 대한 공부를 한다.
예를 들어 F1 스코어를 metric으로 삼을 경우 AUC혹은 정확도가 더 낮더라도 F1스코어가 높게나올 수도 있다.
3. baseline 모델을 잡는다. 데이터 전처리부터 추론 결과를 바탕으로 제출까지 1-cycle을 돌릴 수 있는 baseline 코드를 만든다.
4. 3 에서 만든 baseline 모델의 성능을 최적화해나간다.
변수를 달리 넣어보고, 파라미터를 바꿔보고, 전처리 테크닉을 변경해보면서 성능을 최대한으로 높여본다.
5. 다른 모델을 시도해본다. 전혀 다른 종류의 모델을 시도해봐도 되고, 동일한 계열의 좀 더 고급화된 알고리즘을 사용해보기도 한다.
6. 앙상블을 시도해본다.
대회 경험을 쌓는 것이 꼭 대회에 참가하여야만 가능한 것은 아니다. 간접적으로 Kaggle 필사를 통해 그 경험을 확대해나가는 것도 좋은 방안인 듯 하다.
개인적으로는 Kaggle 대회 중에서도 규모가 크고, 역사가 있는 몇 가지 대표적인 대회들 중 우승자들의 코드를 살펴보며 이해해나가는 것도 좋은 경험을 쌓는 과정이 되었다.
참고자료
* https://www.kaggle.com/gunesevitan/santander-customer-transaction-eda-fe-lgb
Santander Customer Transaction - EDA / FE / LGB
* 그 외 기타 구글링 자료 (pandas docs등)
'Tech > ML, DL' 카테고리의 다른 글
| Data Sampling에 관하여 - (2) Bootstrap, 부트스트랩 (0) | 2022.04.02 |
|---|---|
| Data Sampling에 관하여 - (1) Bias & Random Selection (0) | 2022.03.28 |
| 강화학습(RL, Reinforcement Learning)이란 (0) | 2021.07.04 |
| Bandit 알고리즘과 추천시스템 (0) | 2021.05.14 |
| Tensorflow에 대해 (0) | 2021.05.14 |

