
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- chatGPT
- 메타버스
- RecSys
- nlp
- MSCS
- 미국 개발자 취업
- 클라우드자격증
- 추천시스템
- 미국석사
- MAB
- transformer
- 네트워크
- 머신러닝
- docker
- BANDiT
- HTTP
- MLOps
- swe취업
- 클라우드
- 자연어처리
- 언어모델
- 플랫폼
- maang
- BERT
- BERT이해
- AWS
- 중국플랫폼
- TFX
- 합격후기
- llm
- Today
- Total
SWE Julie's life
GPT Tokenizer에 대해 알아보자 본문
GPT에 대해 더 깊이 있게 이해하려면 Tokenizer에 대해서도 심도있게 살펴볼 필요가 있다.
ChatGPT를 써본 경험이 있는 사람이라면 아래 의문들 중 하나 이상을 마주해본 적이 있을 것이다.
왜 스펠링이 안될까?
왜 문장을 거꾸로 말하라고 하거나 정렬해보라고 하면 안될까?
영어가 아닌 한글로 말할때는 왜 더 안좋은 대답을 줄까?
단순한 수학 연산에 왜 약할까?
GPT-2가 왜 비정상적으로 Python coding 성능이 안좋았을까?
왜 |endoftext|라는 string을 보면 멈출까?
LLM에서 JSON보다는 YAML을 사용하는게 더 좋을까?
위의 질문에 대한 답은 모두 Tokenization 문제이다.
LLM Tokenization 과정은 LLM과 완전히 별도로 분리된 모듈이다. 일반적으로는 아래 그림과 같이 텍스트 → byte encode → encode → token sequence → byte decode → decode → text로 순환하는 구조이다.

본격적으로 GPT Tokenizer를 해부해보기 전에 시각적으로 확인할 수 있는 사이트인 Tiktokenizer에서 예제 텍스트를 넣고 결과를 보면 토큰들이 어떻게 잡히는지 확인해볼 수 있다.

위에서 볼 수 있듯이 하나의 단어가 여러 개로 쪼개지게 된다.
- Tokenization → Token + ization
- Egg. → E + gg + .
- egg. → egg + .
- 8041 → 804 + 1
숫자도 나뉘고 영어도 대문자/소문자일 때 나뉘는 패턴이 다르게 된다.
그리고 영문이 아닌 다른 언어의 경우(위 예제에서는 한글) 동일한 의미를 전달하는 것이라도 chunk가 훨씬 많이 나뉘게 되어 불리하다.
즉 토큰을 더 많이 잡아먹는 상황인 것이다.
코드의 경우에도 Python indentation의 경우 다수의 whitepsace로 구성되어있는데, 이 각각이 하나의 토큰으로 분류되면 토큰 용량을 많이 잡아먹는다.
하지만 GPT 3.5-turbo의 토크나이저의 경우 tab과 double tab이 각각 하나의 토큰으로 분류되는 것을 볼 수 있다.
그럼 이제 본격적으로 Tokenizer의 인코딩 방법에 대해 들여다보자.
일반적으로 우리가 익숙한 Unicode Byte Encoding(ASCII, UTF-8, UTF-16, UTF-32)에서 BPE, 즉 Byte Pair Encoding를 GPT Tokenizer가 채택하고 있다. BPE알고리즘은 간단하게 빈번히 등장하는 짝끼리 묶어 치환한 뒤 인코딩하는 방식이다.
예로, aaaabbcc라는 문자열이 있을 때 자주 등장하는 aa를 X로 치환하면 XXbbcc로 바뀌고, 여기서 다시 bb = Y로 치환하게 되면 XXYcc라는 문자열, 그리고 반복이다.
코드로 살펴보면,
def get_stats(ids):
counts = {}
for pair in zip(ids, ids[1:]): # Pythonic way to iterate consecutive elements
counts[pair] = counts.get(pair, 0) + 1
return counts
stats = get_stats(tokens)
# print(stats)
# print(sorted(((v,k) for k,v in stats.items()), reverse=True))
vocab_size = 276 # the desired final vocabulary size
num_merges = vocab_size - 256
ids = list(tokens) # copy so we don't destroy the original list
merges = {} # (int, int) -> int
for i in range(num_merges):
stats = get_stats(ids)
pair = max(stats, key=stats.get)
idx = 256 + i
print(f"merging {pair} into a new token {idx}")
ids = merge(ids, pair, idx)
merges[pair] = idx
get_stats()라는 함수가 문자열에서 가장 빈번히 등장한 byte pair끼리 frequency를 뽑고 통계치를 dictionary로 저장하고 있다. 이 stats를 활용하여 pair를 맺어줄 byte 조합을 찾게 되는데, 원하는 vocab_size를 지정하고, 그것과 256(=UTF-8의 인코딩 최대 표현 가능한 값)간의 차이만큼의 pair를 생성하게 된다. 즉 내가 10개 byte pair를 생성하고 싶다면 상위 10개의 빈번한 pair 조합을 merge 대상으로 지정하는 것이다. 이 역시 dictionary로 저장해둔 뒤 추후 input으로 들어오는 문자열에 대해 UTF-8로 인코딩하고, 그 byte code들 중 빈번한 pair를 병합하면서 최종 인코딩 결과를 뱉는다.
하지만 이러한 인코딩 알고리즘은 단순하기에 단어를 섣불리 분리해서 그 의미를 온전히 전달하지 못하게끔 할 때가 있다.
그래서 GPT2에서는 정규식으로 특정 패턴은 분리될 수 없게 강제하게끔 후처리를 한다.
실제로 GPT2 논문을 보면 단순한 BPE 알고리즘은 sub-obtimal하다고 말한다.
예를 들어 학습 대상 텍스트에 dog / dog. / dog! 와 같은 단어가 빈번히 등장한다면 이들은 각각 별도로 tokenization이 될 수 있기 때문에 특정 패턴은 분리되어 Tokenization이 될 수 없도록 강제해야한다며 아래 정규식 표현을 제시한다:
's|'t|'re|'ve|'m|'ll|'d| ?\\p{L}+| ?\\p{N}+| ?[^\\s\\p{L}\\p{N}]+|\\s+(?!\\S)|\\s+
위 식은
- apostrophe + 문자열
- 문자(Letter) 구분
- 숫자 구분
- 문자도 숫자도 아닌 punctuation marks (느낌표, 물음표 등) 구분
- whitespace 묶음 구분 (\p는 whitespace)
순으로 우선순위를 따져 분리한다.
즉 문자는 문자대로, 숫자는 숫자대로, 느낌표 등은 따로, 그리고 일반적인 띄어쓰기가 아닌 2개 연속된 띄어쓰기는 별도로 구분한다.
ex) World123 → “World” + “123”, I’ve → “I” + “’ve”
단 예제에서도 볼 수 있듯 휘어진 apostrophe(’)는 분리되지 않는다. '만 해당된다.
눈여겨볼만한 것은 문장의 시작 단어를 제외하고는 스페이스바를 포함하고 나눈다는 것이다. 즉 Hello World는 “Hello”와 “ World”로 나뉘게 된다. 가끔 ChatGPT를 사용하면서 trailing space 에러가 날 때가 이러한 경우이다.
GPT2 Tokenizer를 우리는 inference 용으로만 사용하고 있어 그 내막에 대해 더 자세히 알 순 없지만 RegEx pattern과 BPE알고리즘 외에 추가로 손 본 것들이 있을 것으로 예상된다.
GPT4는 GPT2에서 좀 더 발전되었는데 유의하게 볼만한 것들은 아래와 같다.
GPT4에서는 연속된 whitespace가 각기 다른 token으로 나뉘지 않고 하나로 묶여서 tokenization된다.
주로 Python coding을 위함인 목적이 컸을텐데, 그냥 스페이스바와 4개/8개 스페이스바를 각 하나씩 묶는다.
그리고 apostrophe 조합에서 대소문자를 구분하고 있었는데, 이 패턴이 case insensitive하도록 설정하였다.
즉 ‘s이든 ‘S이든 동일하게 토큰화가 된다.
숫자의 경우 세 자리만 함께 묶인다. 그래서 네 자리 숫자는 각각 세 자리와 한 자리로 나뉘게된다. 1000 → 100 + 0.
Tokenization 결과는 토큰, merge pairs(BPE알고리즘) 그리고 special token으로 구성되어있다.
이 사이트에서 Tokenization 결과를 보면 special token인 <|endoftext|>를 완전히 입력하기 전까진 다른 토큰으로 분류되었다가, 완전히 입력하게 되면 바로 special token으로 분류되는데 이는 BPE 알고리즘 외에 후처리로 special token만을 인지하고 별도 ID로 리턴한다는 것을 알 수 있다.

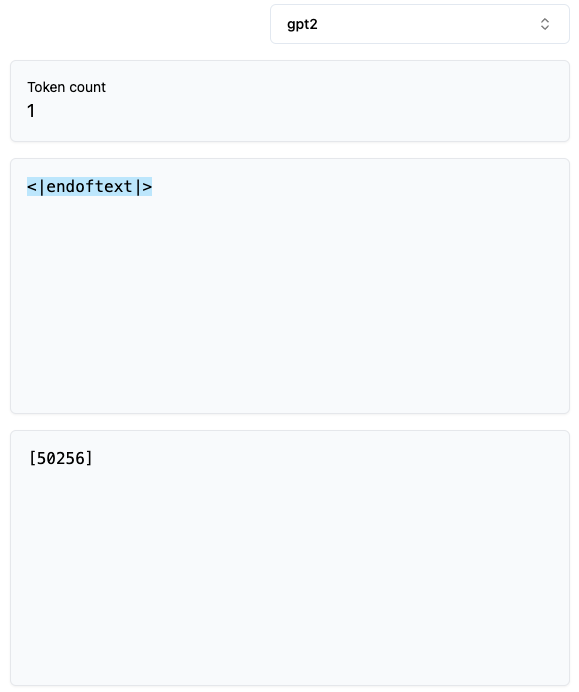
GPT2에는 “<|endoftext|>”라는 special token이 하나있으며,
GPT4에는 “<|endoftext|>”, “<|fim_prefix|>”, “<|fim_middle|>”, “<|fim_suffix|>”, “<|endofprompt|>”로 4가지 special token이 추가되었다. 이 토큰들이 추가된 배경으로는 이 논문을 들 수 있다. 대화형 서비스에서 채팅의 시작, 중간, 끝을 알림으로써 성능을 더 개선하기 위함으로 보인다.
다시 처음으로 돌아가 GPT 의혹들에 답을 하면 좀 더 GPT에 대해 이해할 수 있다.
1. 왜 스펠링이 안될까?
→ 문자를 Split하여 학습하기 때문이다.
2. String processing task가 안될까? (reverse 등)
→ 마찬가지로 문자를 Split하여 학습하기 때문. 하지만 띄어쓰기로 떨어뜨려서 reverse시키면 잘 대답함 ex) detection을 d e t e c t i o n으로 쓰고 reverse하라고 하면 잘 대답한다.
3. non-English language에는 성능이 낮을까?
→ 학습 데이터에 상대적으로 부족함. 그래서 tokenization 결과가 의미를 잘 전달하지 못할 수 있다.
4. 단순한 수학 연산에 왜 약할까?
→ 마찬가지로 숫자 tokenization 때문이다. 일반적으로 덧셈만 생각하더라도 우리는 숫자를 일의 자리부터 점점 큰 단위로 더해가지 앞 자리수부터 더하지 않는다. 게다가 이 자료를 보면 숫자를 구성할 수 있는 가짓수가 굉장히 많은데 이를 제대로된 연산으로 처리하기 위해서는 별도로 special case를 두고 학습해야한다.
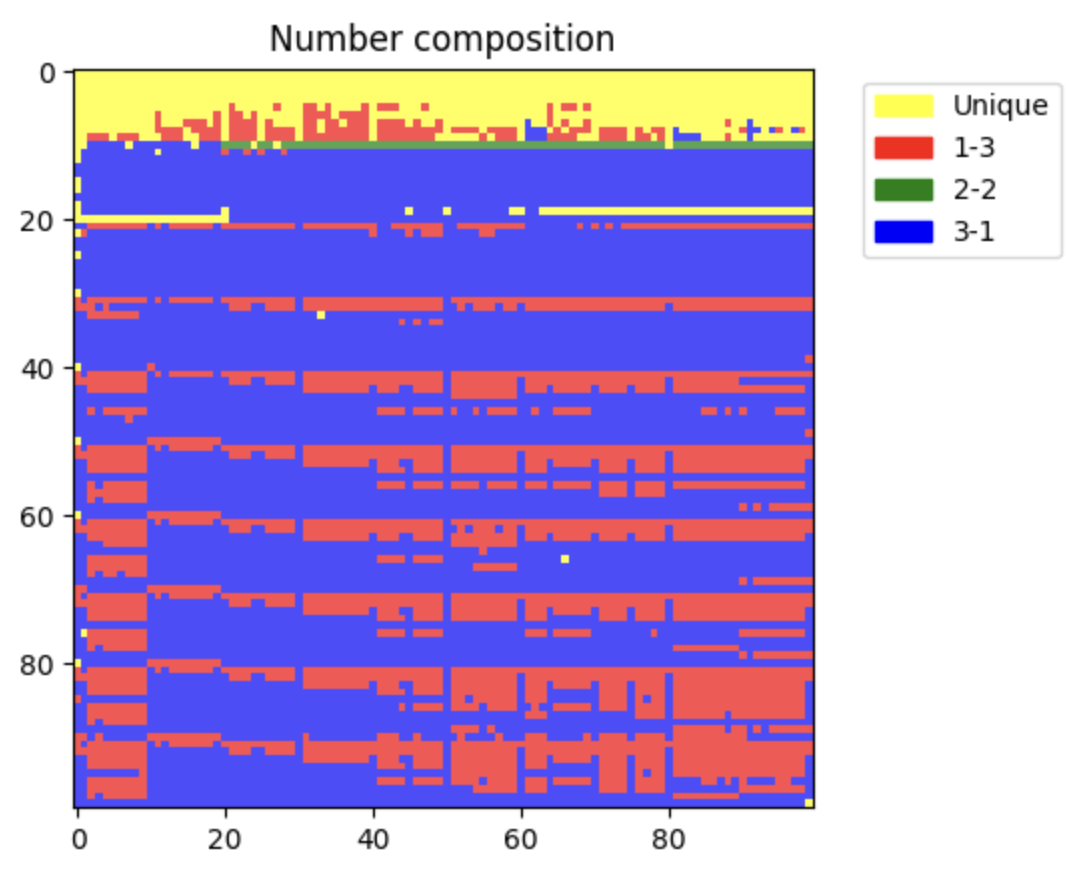
5. GPT-2가 왜 비정상적으로 Python coding 성능이 안좋았을까?
→ indentation(= 연속된 스페이스바)를 어떻게 토큰화하느냐의 차이이다.
6. 왜 |endoftext|라는 string을 보면 멈출까?
→ special token이기 때문이다. 마찬가지로 .DefaultCellStyle과 같이 특수한 토큰들은 일부만 입력하더라도 이러한 단어를 학습데이터에서 보기가 드물기 때문에 예측한 Token distribution이 괴랄할 것이다. 따라서 Completion API를 이용하여 쿼리로 던지게 되면 에러메시지를 뱉는다. 특히 스페이스만 하나 더 추가해서 쿼리를 던지더라도 앞서 본 tokenization 과정에서 알 수 있듯 단어의 시작은 늘 스페이스를 포함하고 있기 때문에 에러를 뱉게 된다. Tiktoken 코드에 “unstable token”이라고 검색하게 되면 실제로 수기로 처리하는 특수 토큰들이 많는다.
7. LLM에서 JSON보다는 YAML을 사용하는게 더 좋을까?

→ YAML에서의 토큰 활용도가 훨씬 높는다. JSON은 토큰 효율성이 좋지 않는다.
8. 특정 단어에 답을 하지 못하는 경우 (ex. SolidGoldMagikarp)
→ 이 사이트에 따르면 Embedding 모델 학습 과정에서 유사한 단어끼리 임베딩 공간에 클러스터링하는데, 가끔 어떤 클러스터에서 이상한 단어들이 묶여있을 때가 있다.
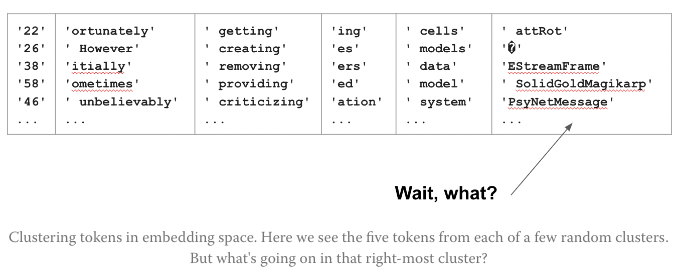
아마도 이러한 단어들은 이커머스 홈페이지/Reddit threads/게이밍 플랫폼 로그기록 등에서 나온 단어들일 것이고 학습 데이터에서 비중이 크지 않아 마주하게 되었을 때 어떻게 해야할지 모를 수 있다. 이러한 이상행동들은 forward propagation에서의 floating point error로 추정되고 있다.
실제로 GPT에게 해당 단어를 물어보게 되면 다른 단어로 답변을 하거나, 답을 피하거나, hallucination이 섞여있거나 욕으로 되받아치거나, 등 이상 행동을 보이게 된다.
결국 LLM 모델도 어떻게 데이터를 전처리해서 넣어주느냐가 중요하다.
Build my own tokenizer
나만의 데이터로 Tokenizer를 학습하고싶다면 Sentencepiece같은 오픈 소스가 있다.
- Sentencepiece
- Llama와 Mistral에서 사용하는 학습/추론 모두 가능한 tokenizer, BPE 알고리즘을 포함하고 있음
- Google에서 제공하는 GitHub 코드가 있는데, sentencepiece는 tiktoken과는 flow가 다름
- tiktoken: 문장을 UTF-8로 변환, 그 다음이 BPE
- sentencepiece: Unicode code point를 바로 BPE로 변환하고 character_coverage 값에 따라 희귀한(빈번하지 않은) code point에 대해서는 UNK 토큰으로 변환하거나 byte_fallback이라는 옵션이 True라면 UTF-8로 변환한 뒤 raw byte를 인코딩함
- byte_fallback = False라면 UNK토큰으로 분류되어 “안녕하세요” 전체가 UNK token의 ID값을 지님
- ex) byte_fallback = True라면 영문으로 학습된 Tokenizer에 “안녕하세요”라고 넣으면 UNK 토큰으로 분류하지 않고 UTF-8로 인코딩한 뒤 그 raw byte를 다시 vocab에 따라 인코딩함
이 외에 이 글을 작성하게 된 배경인 Andrej Karphaty가 간소화한 minBPE도 활용이 가능하다.
- 기타 팁
- vocab_size 는 얼마가 적당한가?
vocab_size 파라미터는 embedding layer, linear layer에 사용된다. 많이 늘릴수록 모든 vocab 속 토큰마다의 확률값을 계산해야하고, 임베딩 학습 레이어의 연산복잡도도 올라간다. 또 너무 vocab size가 크다면 under-training될 확률도 올라가는데, 더 많은 문자(character)에 대해 학습하기 때문에 상대적으로 빈번한 토큰 패턴도 덜 빈번하게/유의하게 학습될 것이기 때문이다. 게다가 vocab_size가 크다면 긴 문자열을 짧게 인코딩하게 되기 때문에 모델이 충분히 단어간 의미에 대해 학습할 여유를 줄여버리게 된다.
- vocab_size 는 얼마가 적당한가?
'Tech > ML, DL' 카테고리의 다른 글
| MemGPT: LLM 시스템, context window 한계 극복법 (1) | 2023.11.25 |
|---|---|
| Secret of Long Context Length (2) | 2023.11.25 |
| GPT 말 잘듣게 하는 법 - Prompt 작성 팁 (0) | 2023.10.09 |
| [오피니언] GPT 등장 이후 시장은 어떻게 변화하고 있나, 우리는 어떻게 대응하나? (2) | 2023.08.23 |
| LLM Evaluation (0) | 2023.08.20 |

