
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- HTTP
- MSCS
- TFX
- 미국 개발자 취업
- 미국석사
- llm
- 자연어처리
- 언어모델
- maang
- nlp
- AWS
- BERT이해
- transformer
- RecSys
- 머신러닝
- 중국플랫폼
- 클라우드
- 메타버스
- BANDiT
- BERT
- MLOps
- chatGPT
- 네트워크
- 플랫폼
- 클라우드자격증
- MAB
- 추천시스템
- 합격후기
- swe취업
- docker
- Today
- Total
SWE Julie's life
딥러닝 기초 - 사례로 배우는 이진분류 모델링 본문
keras의 인터넷 영화 DB(IMDB)로 이진분류 모델링을 실습해볼 것이다.
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = {})num_words 파라미터는 시퀀스에서 가장 빈번하게 등장하는 상위 x개 만큼을 사용하겠다는 것이다.
1만개를 적용하게 되면 상위 1만개 빈번 단어가 출력된다.
train_data를 프린트해보면 알겠지만, 여러 정수형 원소들이 들어있는 리스트의 묶음체이다.
신경망에는 숫자 리스트를 input할 수 없어, 리스트를 텐서로 변환해야한다.
두 가지 방법 정도로 정리할 수 있는데,
1) 리스트에 패딩을 추가하여 시퀀스를 모두 동일한 길이의 정수 텐서로 변환
2) 리스트를 one-hot encoding
// one-hot encoding simple code
def one_hot_encoding(sequences, dimension=100000):
encoded = np.zeros(len(sequences), dimension) //(sample개수, sequence의 dimension)
for i, sequence in enumerate(sequences):
encoded[i, sequence] = 1
return encoded// encoding train data
x_train = one_hot_encoding(train_data)
x_test = one_hot_encoding(test_data)
// convert labels as scala array
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')학습데이터와 테스트 데이터를 모두 전처리했다면,
이제는 모델을 빌딩할 차례이다.
모델을 빌딩할 때, 여러 레이어를 겹겹이 쌓게 되는데,
이 때 input으로 들어가는 파라미터의 의미를 잘 알아야 한다.
keras에서는 아래 예시와 같이 간단하게 층을 만들 수 있다.
layers.Dense(16, activation = 'relu'))
위에서 은닉층을 16 차원으로 지정했다는 것은,
output = reul(dot(W, x) + b)
에서 W, 즉 가중치 행렬이 (input_dimension, 16) 크기를 갖게 되는 셈이다.
이러한 배경지식을 바탕으로 간단한 3층 모델을 구현해보면,
from keras import models
from keras import layers
// Keras에서 모델을 빌드하는 방법은 Sequential()과 함수형 API 두 방법이 있다.
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))위와 같다. 모델을 컴파일하기 전에 Optimizer, loss function, metric에 대해 정해야한다.
이진 분류 문제에서는 loss function으로 binary_crossentropy 또는 mean_squared_error를 사용할 수 있다.
// 문자열로 전달
model.compile(optimizer='rmsprop', loss = 'binary_crossentropy', metrics=['accuracy'])
// 객체로 전달
from keras import losses
from keras import metrics
from keras import optimizers
model.compile(optimizer = optimizers.RMSprop(lr=0.001),
loss = losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])모델을 빌딩했으니, 본격적으로 학습할 차례이다.
중간에 학습데이터에서 일부를 떼어 validation set을 만들어준다.
history = model.fit(x_train, y_train, epochs=20, batch_size=512,
validation_data(x_val, y_val)
train, validation set별 loss 값을 plotting해볼 수 있다.
import matplotlib.pyplot as plt
history_dict = history.history // history 속성을 갖고 있음
loss = history_dict['loss'] // 혹은 'acc'
val_loss = history_dict['val_loss'] // 혹은 'val_acc'
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, label = 'Training Loss')
plt.plot(epochs, val_loss, label = 'Validation loss')
plt.show()
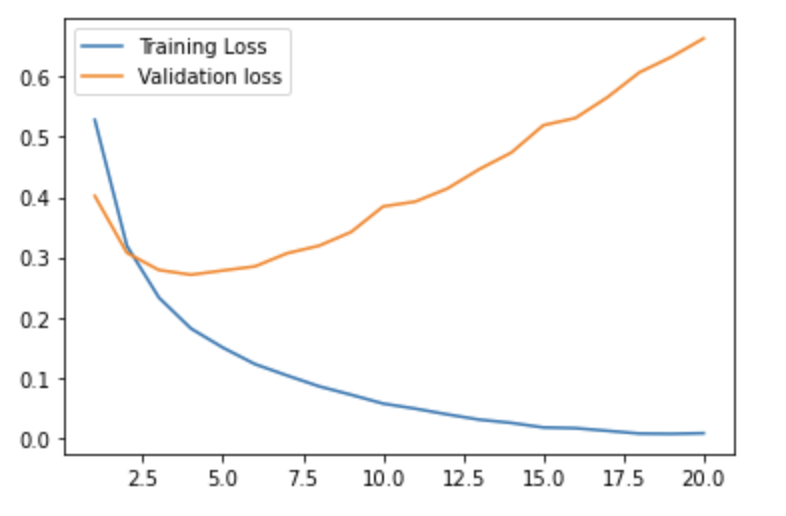
(좌) accuracy (우) loss
위 그림에서도 볼 수 있듯이 training set에 대한 정확도와 validation set에 대한 정확도 차이가 크다.
overfitting이 발생했다는 것을 확인할 수 있다.
이 떄 여러 가지 시도를 해볼 수 있지만,
단순하게 epoch를 줄이는 시도로 overfitting문제를 해결해볼 수 있었다.
추가로 만약 다중 분류 문제를 해결하려면,
동일하게 레이블을 one-hot encoding하거나 정수형 텐서로 바꾸는 방법이 있다.
레이블을 One-hot encoding하였다면 손실함수로 categorical_crossentropy를 사용하면 된다.
정수형 텐서로 사용했을 경우 sparse_categorical_crossentropy로 사용한다.
다중 분류 문제를 해결할 때 주의해야할 점은, 은닉층의 차원이 분류해야할 클래스 수보다 많이 적어선 안된다.
많은 정보를 중간층의 저차원 공간으로 표현하게 되면, 병목 현상이 발생할 수 있기 때문이다.
또한 회귀 분석과 같이 앞서 살펴본 feature가 범주형이 아닐 경우,
정규화를 통해 스케일을 맞춰주어야한다. 흔히 Min-max, 또는 표준 스케일러를 사용한다.
모델링을 진행할 때에는 보통 다른 일반 모델과는 다르다.
from keras import models
from keras import layers
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activation = 'relu', input_shsape(train_data.shape[1],)))
model.add(layers.Dense(64, activation = 'relu'))
model.add(layers.Dense(1)) // 별다른 activation 함수 사용 안함. 출력값 제한하기 때문
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])) // lossf mse 사용
return model
* MSE : Mean Squared Error
** MAE : Mean Absolute Error
데이터 수가 많지 않을 경우 훈련 검증을 위해 k-fold 검증방법을 사용할 수 있다.
데이터를 k개 만큼 분할하여 여러 폴드를 만드는 것인데, 예를 들어 5겹 교차 검증이라고 할 때,
한 묶음만큼 5회 교차검증할 수 있다.

5-fold cross validation
4개의 데이터는 학습에 사용되고, 하나의 데이터가 검증에 사용된다.
k = 4
cross = len(train_x) // k
epochs = 100
scores = []
mae_histories = []
for i in range(k):
val_x = train_x[i * cross : (i+1) * cross] // i 번째 항목
val_y = train_y[i * cross : (i+1) * cross] // i 번째 항목
train_x_part = np.concatenate([train_x[:i*cross], train_x[(i+1)*cross]], axis=0)
train_y_part = np.concatenate([train_y[:i*cross], train_y[(i+1)*cross]], axis=0)
model = build_model()
// type1
model.fit(train_x_part, train_y_part, epochs = epochs, batch_size = 1, verbose = 0)
val_mse, val_mae = model.evaluate(val_x, val_y, verbose = 0)
scores.append(val_mae)
// type2
history = model.fit(train_x_part, train_y_part, epochs = epochs,
validation_data = (val_x, val_y),
batch_size = 1, verbose=0)
mae_history = history.history['val_mean_absolute_error']
mae_histories.append(mae_history)type1 처럼 각 폴드별 검증점수를 평균내어 최종 점수를 낼 수도 있고,
type2처럼 epoch 전체에 대한 기록을 남겨 에포크별 MAE 점수 평균을 낼 수도 있다.
* mae_histories는 [[epoch1_fold1, epoch2_fold1..., epoch100_fold1], [epoch1_fold2...],...]
average = [np.mean([x[i] for x in mae_histories]) for i in range(epochs)]
epoch별로 위 그래프를 그렸을 때, 초반에는 MAE가 굉장히 높을 수 있다.
이럴 경우 지수이동평균을 통해 MAE변화에 대해 좀 더 살펴볼 수 있다.
MAE 그래프를 플라팅했을 떄, 변곡점처럼 어느 순간 이후 부터 과적합이 발생할 경우, 학습에 유의한 epoch수를 파악할 수 있다.
참고도서
https://book.naver.com/bookdb/book_detail.nhn?bid=14069088

케라스 창시자에게 배우는 딥러닝
단어 하나, 코드 한 줄 버릴 것이 없다!창시자의 철학까지 담은 딥러닝 입문서단어 하나, 코드 한 줄 버릴 것이 없다!창시자의 철학까지 담은 딥러닝 입문서케라스 창시자이자 구글 딥러닝 연구원인 저자는 ‘인공 지능의 민주화’를 강조한다. 이 책 역시 많은 사람에게 딥러닝을 전달하는 또 다른 방법이며, 딥러닝 이면의 개념과 구현을 가능하면 쉽게 이해할 수 있게 하는 데 중점을 두었다. 1부에서는 딥러닝, 신경망, 머신 러닝의 기초를, 2부에서는 컴퓨터 비전, 텍스트, 시퀀스, 생성 모델을 위한 딥러닝 같은 실전 딥러닝을 설명한다. 이외...
book.naver.com
'Tech > ML, DL' 카테고리의 다른 글
| Kaggle Case Study - (2) LightGBM 모델 (0) | 2021.05.13 |
|---|---|
| 딥러닝 기초 - Keras 함수형 API, callback (0) | 2021.05.13 |
| 머신러닝 기초 - 분류, 모델 평가, 과적합에 대해 (0) | 2021.05.13 |
| 딥러닝 기초 - 텐서(Tensor)와 신경망 학습 과정 (0) | 2021.05.12 |
| Kaggle Case Study - (1) Santander Customer Transaction Prediction (0) | 2021.05.12 |



