
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- AWS
- transformer
- 합격후기
- 머신러닝
- BERT이해
- MAB
- nlp
- 자연어처리
- maang
- MLOps
- 미국석사
- docker
- swe취업
- BANDiT
- BERT
- 추천시스템
- 중국플랫폼
- HTTP
- 언어모델
- chatGPT
- 클라우드
- 네트워크
- MSCS
- TFX
- 메타버스
- RecSys
- 클라우드자격증
- 플랫폼
- llm
- 미국 개발자 취업
- Today
- Total
SWE Julie's life
앙상블 - 배깅과 부스팅, GBM(Gradient Boosting) 알고리즘 본문
Kaggle 필사를 하다 보면 가장 흔하게 사용되는 모델들이 있다.
예를 들어 XGBoost와 lightGBM 모델이 그 예로 해당된다.
오늘은 이 두 모델이 근간을 두고 있는 앙상블에 대한 개념을 다시 짚고,
Gradient Boosting 알고리즘에 대해 살펴볼 것이다.
앙상블에는 두 가지 타입이 있다.
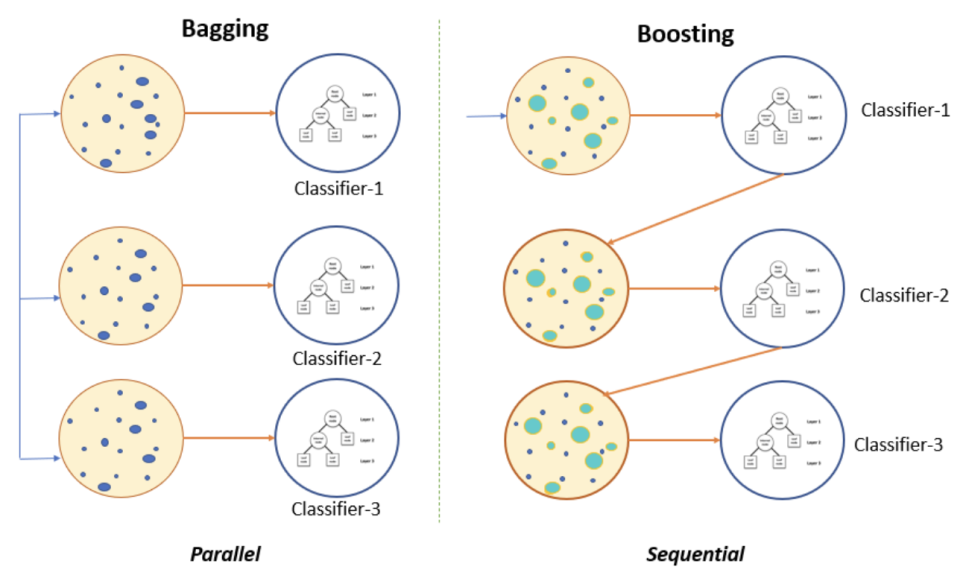
1. 배깅(Bagging)
배깅은 독립된 모델들의 결과를 합산하여 다수결 투표(Voting)을 통해 결과를 산출하는 것이다. parallel ensemble이라고도 부른다. 위 이미지에서 왼쪽처럼 bootstrap된(=랜덤 복원샘플링) 데이터가 각 분류기에 input되고, 각각에 따른 결과물들을 한 데 결합하여(Aggregation) 중 다수가 추측한 결과대로 결과를 뽑는 것이다.

2. 부스팅(Boosting)
부스팅은 특정 모델의 결과를 다른 모델의 input으로 사용하는 방식으로, 모델간 가중치를 부여하여 결과를 산출한다. sequential ensemble이라고도 부른다. 첫 이미지에서 분류기 1-2-3 순서로 input되는 것을 알 수 있다. 첫 모델 결과에 따라 오차가 큰 데이터의 경우에는 가중치를 부여하여 다음 분류기로 전달하게 된다. 오차가 큰 데이터(=잘못 예측한 데이터)는 가중치를 크게 부여하고, 잘 예측한 데이터에 대해서는 낮은 가중치를 부여하여 다음 모델로 넘겨준다. 이 때 각 모델은 다른 정확도/성능을 지니고 있기 때문에 모델간 가중치도 부여하여 최종 결과를 산출한다.
Gradient Boosting 알고리즘 역시 이 앙상블 기법에 해당한다.
배깅과 부스팅의 성능을 비교하면, 부스팅이 통상 성능이 더 좋지만, 소요되는 시간이 오래 걸리고 연산량도 많다. Gradient Boosting은 부스팅 기법을 이용한 앙상블 모델 중 하나로, GBM(Gradient Boosting Machine) 계열 모델들을 보유하고 있다. GBM은 Boosting 앙상블 기법의 특성처럼, 연산량이 많기 때문에 속도에 대한 개선이 필수적인데,
이를 효율적으로 처리한 여러 가지 모델들이 있는 것이다 : XGBoost, lightGBM, CatBoost 등
Gradient Boosting은 다음 모델로 넘겨주는 input을 gradient로 삼고, 그에 가중치를 부여하는 방식이다.
* gradient descent + boosting을 합친 용어, 잔차에 대한 음의 경사도(기울기)를 이용하여 잔차가 줄어드는 방향으로 모델을 학습하는 기법이다. 이 때 negative gradient를 사용하는 이유는 미분의 수학적인 정의를 참조하면 이해할 수 있다.
GB는 loss function에 대한 미분값(=잔차에 대한 음의 경사도)을 이용하여 loss function 값이 줄어드는 방향을 찾는다. 이 결과를 새로운 모델의 Input으로 전달하면, 새로운 모델은 이 값을 줄이는 방향으로 업데이트가 될 것이다. 즉 모델들은 계속해서 잔차(실제값과 예측값의 차이)를 줄여가는 방향으로 학습하는 것이다.
수학적으로 좀 더 들여다보자. 만약 모델의 loss function이 squared error로 정의가 된다면, 아래와 같이 negative gradient는 잔차와 동일하다. (y : 실제값, f(x) : 모델 예측값)

따라서 squared error 손실함수를 사용하는 모델은 Boosting이 잔차 적합(=residual fitting) 과정이기도 하다.
위 식에서도 살펴볼 수 있다시피, negative gradient가 residual (= 실제 값과 예측값의 차이, 잔차)와 동일하다.
도식화하여 살펴보면 좀 더 직관적으로 잔차를 최적화해나가는 것을 볼 수 있다.
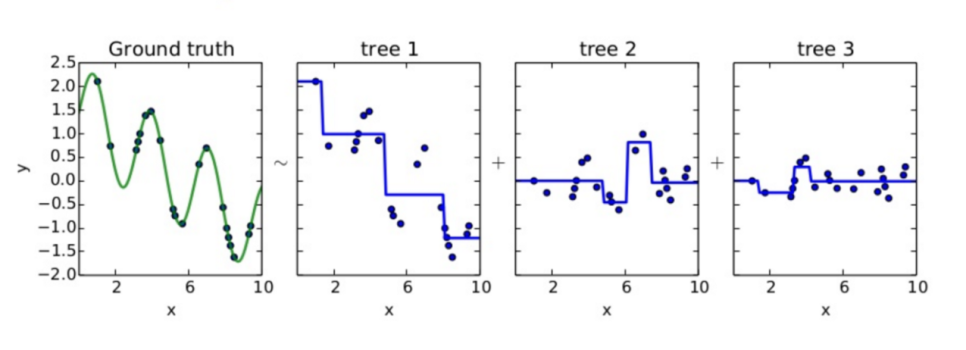
다른 loss function을 사용하여 Gradient Boosting하는 모델의 경우 위와 마찬가지로 negative gradient를 이용하여 모델을 학습해나가게 된다.
이처럼 GBM은 잔차를 0으로 학습하는 방향으로 가기 때문에 정확도가 좋아 높은 성능을 보일 수 있다. 하지만 동시에 과적합이 될 수 있다는 단점이 있다. 다시말해 모델이 학습데이터에 맞추어 학습하다보면, 다른 일반적인 데이터를 예측하는 데 어려움이 있을 수 있다. 이에 따라 GBM 기반 모델에는 정규화하는 알고리즘이 꼭 포함되어 있다. 예를 들어 learning_rate를 활용하여 정규화할 수 있는데, 예측값에 곱하여 예측값과 실제값과의 차이를 일부러 조금씩 남겨두는 것이다.
GBM 알고리즘은 tree를 단계적으로 하나씩(one-by-one) 결합해나가게 된다. 즉 앞선 그림에서 보았던 것처럼 Sequential하게 각 tree의 예측 결과를 합산해나간다. 아래와 같이 결합된 Tree n개 예측값을 합산한 것을 D(x)로 정의하였을 때, 이 D(x)와 실제 함수 f(x)간의 차이를 줄여나가는 것이다.

GBM의 pseudo-code는 아래와 같다.

2-1이 negative gradient를 구하여 잔차를 정의하는 부분이다.
2-2는 base tree를 pseudo-residual에 맞추어 만들어내는 부분이다. 즉 학습해나갈 모델을 만들기 위해 가장 기본이 되는 tree를 만드는 것이다. (앞선 수식에서는 D1(x)가 될 수 있다. 이 때 pseudo-residual은 여러 가지로 구현될 수 있는데, 일반적으로 예측값을 학습데이터의 y값 평균으로 구하고, 그 값과 실제값간의 차이를 pseudo-residual로 삼기도 한다.
2-3은 2-1에서 정의한 잔차를 최소화하도록 모델을 학습하는 과정을 풀어내었다.
2-3에서 구한 모델과 base tree를 결합하여 새 모델을 학습한뒤, 다시 2-1부터 과정을 반복한다. 특정 횟수 M만큼 과정을 반복하여 최종 모델인 FM(x)를 산출한다.
마지막으로는 Gradient Boosting 알고리즘을 시각적으로 체험해볼 수 있는 사이트가 있어 공유한다.
http://arogozhnikov.github.io/2016/06/24/gradient_boosting_explained.html
요약
* 앙상블
- Bagging : bootstrap + aggregation > Voting, 독립된 모델들
- Boosting : Sequential ensemble, 모델의 결과가 다른 모델의 input으로
Boosting이 더 성능이 좋으나, 연산량이 많음
* GBM
- Gradient Descent + Boosting
- loss function이 SE일 경우 negative gradient = residual, residual fitting
잔차를 최적화할수록 오차는 적으나 과적학될 가능성이 있음
이에 따라 정규화하는 알고리즘 필요
GBM모델이 학습되는 과정에 대해 손쉽게 설명해놓은 블로그를 공유한다.
https://bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-15-Gradient-Boost
머신러닝 - 15. 그레디언트 부스트(Gradient Boost)
앙상블 방법론에는 부스팅과 배깅이 있습니다. (머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)) 배깅의 대표적인 모델은 랜덤 포레스트가 있고, 부스팅의 대표적인 모델은 A..
bkshin.tistory.com
'Tech > ML, DL' 카테고리의 다른 글
| Tensorflow에 대해 (0) | 2021.05.14 |
|---|---|
| GBM 모델 : lightGBM vs XGBoost (0) | 2021.05.14 |
| 딥러닝 기초 - Keras API 사용 없이 small DNN 구현하기 (0) | 2021.05.14 |
| 딥러닝 기초 - 노드와 퍼셉트론 (0) | 2021.05.13 |
| Kaggle Case Study - (2) LightGBM 모델 (0) | 2021.05.13 |
