
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- chatGPT
- 클라우드자격증
- 미국석사
- swe취업
- 합격후기
- 중국플랫폼
- docker
- 추천시스템
- HTTP
- 미국 개발자 취업
- 머신러닝
- nlp
- MAB
- 자연어처리
- RecSys
- 언어모델
- BERT이해
- 플랫폼
- BERT
- MSCS
- 메타버스
- llm
- TFX
- BANDiT
- AWS
- transformer
- 네트워크
- maang
- MLOps
- 클라우드
- Today
- Total
SWE Julie's life
[UIUC MCS 회고] 대학원을 졸업하며.. 본문

짧다면 짧고 길다면 긴 대학원 생활이 끝을 맞이했다. 사실 나는 Professional Degree라서 논문을 쓰지는 않았기에 연구에 가까운 대학원 생활은 아니었지만, 학문 깊이가 깊어지고 + 과제/플젝 폭탄을 등에 얹고 쉬지 않고 달리는 느낌이었다. 미국 대학은 늘상 기본으로 weekly quiz, bi-weekly machine problems, 그리고 시험 혹은 프로젝트로 구성되어있어 학생들을 계속 바쁘게 굴린다. 나에게 계속 “너 이거 확실히 알아? 이거는? 저거는?” 하며 테스트하는 기분이었다. 그래도 각국에서 온 교수님 뿐만 아니라 학생들마저도 각기 다른 히스토리를 보유하고 있어 커뮤니티에서 서로 활발히 교류하는 그 과정이 굉장히 좋았다. 또 잘 설계된 과제들을 하다보면 정말 배우는 것도 많고 내가 성장하는 것도 체감할 수 있어 보람찼다.
나는 내 자신을 일부러 더 고되게 만들어서 학위를 얻었는데… 시작함과 동시에 미친척하고
1) 1년만에 졸업해보자
2) 올A+ 성적을 받아보자 라는 마음가짐으로 나를 갈아넣기 시작했다.
그래서 Summer 2023에 입학해서 Summer 2024에 졸업했고 지금 이 글을 쓰고 있다.
UIUC는 32학점을 채워야 졸업이 가능하며, 한 과목이 4학점씩 한 학기에 최대 2개까지 수강이 가능하여 총 4학기 각 2개 과목씩 수강했다. 오늘은 각 과목별 배웠던 것들을 간략히 정리하고 회고해보려고 한다.
SUMMER 2022:
(CS416) Data Visualization, (CS513) Theory and Practice of Data Cleaning
첫 시작을 여름학기로 했더니 학기도 짧고 강의도 짧아서 한 학기 좀 더 미뤄서 시작할 걸 후회했다. 그래도 DS계열 과목들을 듣기로 마음을 먹어서 data visualization과 data cleaning 과목을 신청했다.
Data Visualization: 이 과목은 전반적으로 시각화에 대한 기본적인 내용을 다루었다. 사람의 눈이 인지하는 색 범주와 어떤 색이 가장 주의력을 이끄는지, 그리고 각 차트 타입마다 어떤 유형의 데이터가 적합한지를 다루었다. 내가 일반적으로 알던 Bar chart, Pie chart 등 기본적인 차트들도 다루지만 그걸 이론적인 내용으로 접근해본 것은 처음이라 신기했다. 강의나 퀴즈, 시험 외에 프로젝트 과제가 하나 있었는데, 이 경우 narrative visualization으로 스토리를 전달해야했다. 이 때 웹기반 대시보드를 제작해야했고 데이터는 정해져있었지만 화면과 대시보드로 전달할 메시지는 내가 직접 정해야했다. 데이터는 미국에서의 Data Science 도메인의 직군별 연봉정보였는데, 나는 각 년도별 Top 5 연봉정보에 대해 돈의 양에 비례한 Pie chart, bar chart 등을 필터를 두고 selective하게 고를 수 있도록 구성했었다. 화면에서 각 년도별로 필터해서 볼 수도 있고, 혹은 슬라이드바로 움직이면서 flow를 볼 수도 있게 만들었었다. 이 때 외부 라이브러리를 쓸 수 없어서 html, css만으로 시각화를 만드느라 끙끙했던 기억이 난다.

Data Cleaning: 사실 이 과목은 후기도 좋지 않고 500 단위 수업들 중에서도 제일 쉽다는 이야기가 있어서 고민했었지만 그래도 DS계열 과목을 듣고 싶었고, 내 업무상 data cleaning 이론을 모르기엔 데이터 엔지니어링 역량도 꽤 필요했던 터라 수강하게 되었다. 데이터 전처리와 관련된 내용이 주여서 정규식, Relational Algebra, 그리고 전처리 과정에 대해 에 대한 내용을 배웠고, 마지막엔 OpenRefine이라는 데이터 처리 툴에 대해서 실습과 프로젝트까지 있었다. 이 과목에 대한 기억은 많이 없는 것 같다.

FALL 2022:
(CS410) Text Information System, (CS447) Natural Language Processing
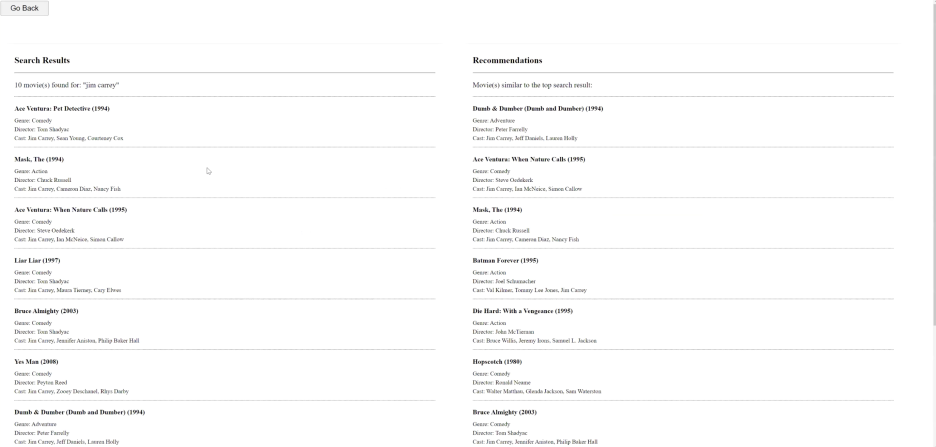
Text Information System: 텍스트 마이닝과 검색엔진까지 커버했던 과목. 검색엔진의 가장 기본적인 알고리즘인 TF-IDF, BM25, 그리고 BM25의 variant들을 커버했었다. 과제가 많이 기억에 남는 과목이었는데, 팀 프로젝트와 Tech Review가 파이널 과제같은 느낌이었고 많이 공들였어서 기억에 남아 적어본다. 팀 프로젝트는 5명 정도 모여 검색엔진 웹을 직접 기획하고 구현해보는 과제였다. 우리는 Flask로 간단한 웹을 만들었는데, 기본적인 BM25 알고리즘으로 간단한 검색엔진 위에 Collaborative Filtering 모델과 Wiki Data API에서 제공하는 지식그래프에서 검색된 영화와 연관도가 높은 영화를 추천해주는 추천시스템 웹이었다. 이 땐 다른 플젝과 다르게 메신저에서만 이야기를 주고받는게 아니라 줌 콜을 수차례 했었고 내가 팀 리더로 당첨이 되어서 리딩을 했어야했다. 친구들 모두 열정적이었어서 디자인이 화려하진 않지만 있을 건 다 있는 화면이 탄생해서 뿌듯했다. Tech Review 리포트는 여러 논문들을 리뷰하여 에세이처럼 작성하는 과제였는데, Attention - BERT - BERT variants 순으로 연결해서 커버했던 것 같다. 듣기만 했던 모델들에 대해서 논문을 강제로라도 읽어볼 기회가 생겨 좋았고, 우연의 일치인지 그 다음 해부터 우연의 일치인지 ChatGPT의 시대가 도래했고 덕분에 기반 지식으로 잘 활용할 수 있었다.

Natural Language Processing: TIS와 유사하게 텍스트 마이닝 도메인이나 이 강의는 보다 BERT와 같은 본격적인 자연어처리 모델들에 대해 알려주었다. 이 과목에서 기억나는 것은 매주 reflection 과제가 있었는데 독특했다. 퀴즈와는 다르게 정답이 정해져있지 않은 오픈형 질문들이 매주 나왔고 내가 배운 것을 기반으로 나만의 생각을 적용해서 풀어야했다. 가장 첫 주의 과제가 제일 기억에 남는데, 인공지능 영화에서 나온 로봇의 답변을 주고 그 로봇이 왜 적절한 답을 하지 못했을까에 대한 원인을 찾아야했다. 예를 들어 로봇이 “네 아버지는 어떤 사람이야?”라고 했을 때 사람이 “내 아버지는 별로 좋은 사람이 아니야. (말 돌리며) 너는 오늘 뭐했어?”라고 대답했을 때, 사람은 일반적으로 좋은 상황이 아님을 감지하고 그만 물어볼텐데, 로봇은 꾸준히 아버지가 왜 안좋은지, 어떤 사람이었는지를 캐물었다. 교수가 던진 질문은 로봇이 자각하지 못한 이유와 학습과정을 고려했을 때 왜 자각하지 못할 수 밖에 없었는지 였던 것 같다. 그 외엔 다른 과목들과 동일하게 퀴즈, 프로그래밍 과제가 있었고 마지막 프로젝트로는 개인마다 literature review를 작성해야했고, NLP 논문 3-4개를 읽고 에세이를 써야했다. 나는 TIS과목에서도 읽었던 BERT계열 논문을 리뷰하고 이 과목에서는 좀 더 딥하게 Attention behavior들을 시각화하고 이해해보려했던 기법들의 논문들을 리뷰했다. 논문을 단순히 요약만 하는게 아니라 비평이나 나의 인사이트가 있었어야 했기 때문에 쉽게 편히 읽지는 못했던 기억이 난다. 이 때도 LaTex로 써서 냈어야했는데 처음으로 인용해보기도 하고 논문처럼 introduction - background.. 순으로 짜임새 있게 구성해봤었다.

SPRING 2023:
(CS598) Deep Learning for Healthcare, (CS498) Cloud Computing Application
Deep learning for healthcare: 이 과목은 내가 들은 것 중에 거의 유일하게 Capstone같은 과목이라 꽤 설레며 학기를 시작했었다. 교수님이 꽤 이 분야에서 유명하신 것 같아 보였던게 주요 논문 저자에 교수님이 없는 것을 찾기 힘들 정도였기 때문이다. 심지어 연구실에서는 PyHealth 라이브러리를 개발하고 운영하고 있고, 실제로 다양한 퍼블릭 healthcare 데이터셋과 task들에 대한 모델들이 잘 통합되어 있어 유명한 것 같았다. 프로그래밍 과제는 대부분 healthcare 쪽 모델들을 재현하는 것으로 되어있었고 시험은 따로 없었지만 프로젝트가 꽤 도움이 많이 되었다. 수강하는 내내 프로젝트를 해야했는데 healthcare 모델 논문을 그대로 구현하는 과제(Reproducibility Project)였다. 이 과정에서 논문을 여러 개 리뷰하고 실제 논문 모델 성능 테스트를 재현해보면서 이론과 현실의 차이를 느껴보게 되었다. 공식 레포의 파이썬 및 다른 라이브러리 버전이 많이 낮아서 버전업도 하고 돌아가게끔 수정하는 과정이 꽤 걸렸는데, 코드가 길고 많아서 고생했다. 같이 프로젝트했던 친구가 SWE 포지션이라서 많이 자극받았는데, 나는 어텐션 시각화하는 기능을 추가함으로써 이 프로젝트에 데이터적인 측면에 기여를 했었다. 이전 NLP과목에서 literature review로 읽은 논문에서 찾은 방법을 적용했었다. 이 때 리포트 역시 모두 LaTex로 작성해야했어서 연구를 멀리서나마 터치해볼 수 있었다.


Cloud Computing Applications: CCA는 당시에 속해있던 조직이 Cloud 유관조직이라 AWS 자격증을 땄던 것도 있고, 좀 더 본격적으로 실전역량을 길러보고 싶어서 수강했는데 교수님/TA들이 과제를 굉장히 잘 디자인하셔서 AWS에서 실제로 리소스 띄우고 어플리케이션을 만들어볼 기회가 굉장히 많았다. 주피터 노트북으로 모델 만들고 테스트하던 과제들과는 다르게 서버나 DB 리소스 등을 만들어서 어플리케이션 로직을 개발하고 그 위에 띄워서 돌려볼 기회가 12번이나 있었다. 여러 디자인이 있었는데 챗봇을 만들어 이 과목은 개인적으로 많이 아꼈다. 시험은 거의 AWS 자격증 시험과 비슷했어서 사실상 과제 비중이 꽤 컸던 과목. Hadoop, Spark, Storm과 같은 클라우드 리소스 외에 다양한 빅데이터 처리 프레임워크들, Docker와 Redis까지 접해볼 수 있어 무척 재미있었다. 이 과목을 들으면서 나는 데이터 분석 그 자체도 좋아하지만 수집부터하여 end-to-end로 서비스까지 개발해보는 그 일련의 과정들을 매우 흥미로워하는구나 느꼈다. 뿐만 아니라 클라우드에서 아키텍쳐를 그리고 연결하는 일에도 흥미로워하는구나 알 수 있었다.
SUMMER 2023:
(CS411) Database System, (CS519) Scientific Visualization
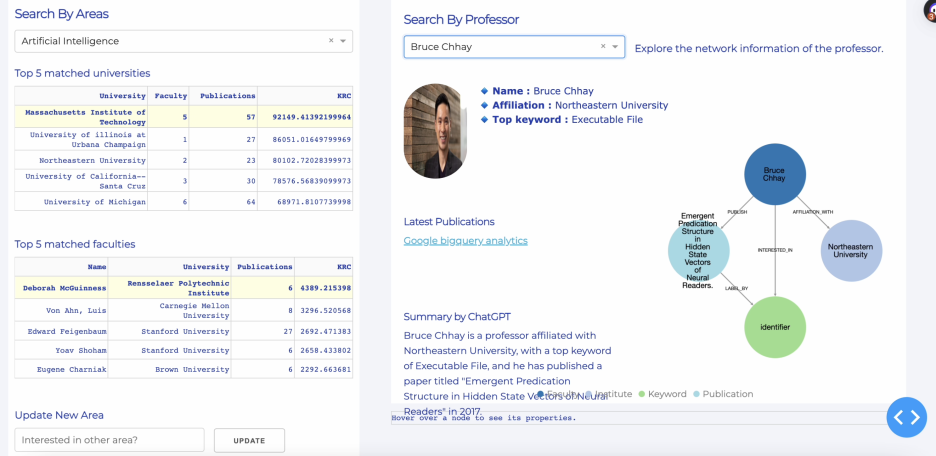
Database System: 전반적으로 DB와 친해지고 데이터베이스를 관리하는 방법에 대해 알려주는 과목이다. MySQL, Neo4j, MongoDB로 Non-relational DB까지 이용방법과 SQL, MongoDB Query Language, Cypher에 대해 익숙해질 수 있었다. 시험 총 3번, 프로그래밍 과제, 그리고 파이널 프로젝트가 있었고 특히 시험에서 쉽게 놓칠만한 중요한 부분들에 대해 한 번 더 꼬아둔 질문이 많아서 더 열심히 공부하게 되었다. 아주 쉬운 예로는 MySQL 쿼리에서 groupby, agg로 평균을 구하는 쿼리인데 데이터 상 Null이 있을 때 없을때 등을 감안하고 데이터 결과를 연산해야했다. Final project로는 대시보드를 만들어야했는데 MySQL, Neo4j, MongoDB를 모두 백엔드로 두고 여러 위젯을 만들어야했다. 대시보드 시나리오 구상부터 화면 기획, 데이터 연결 코드 등을 직접 작업해야해서 꽤 재밌게 했다. 도메인이 대학교 교수, 교수들의 연구활동, 대학 정보를 다루고 있어서 University Explorer 웹을 개발했다. CS-rankings와 같이 학생들이 원하는 분야를 설정하면 연구결과로 상위 매칭 대학들을 보여주고, 교수를 선택하면 교수와 관련된 연구분야, 논문 실적 그리고 네트워크로 연결된 다른 교수들까지 모두 보여준다. 이 과정에서 Extra-credit 활동으로 외부 데이터 확장을 하면 점수를 더 준다해서 욕심내서 SERP API로 Google Scholars 데이터와 OpenAI 로 ChatGPT 응답을 합쳐서 대시보드를 만들어 보여주었다.
Scientific Visualization: 수강했던 과목들 중에 가장 마이너하고 흥미가 떨어졌던 과목이다. 그렇지만 졸업해야해서 어쩔 수 없이 수강했다. 정말 Science 필드에서의 visualization 기법에 대해 제너럴하게 커버하고 있기 때문에 주로 의료분야 / 일반과학 / 렌더링 쪽에서 어떤 시각화 기법이 있는지에 대해 다루었다. 중간고사까지는 Color map에 대한 이야기, 렌더링에 필요한 data interpolation, mesh생성에 사용될 marching square/cube/tetrahedra 등의 알고리즘에 대해 배우고 기말고사부터는 본격적으로 vector 값을 시각화 하는 법, 샘플링 방법, 그리고 대규모 데이터를 렌더링할 때 효율적으로 mesh 사이즈를 줄이거나 연산을 가속화하는 방법 등에 대해 배웠다. 별다른 프로젝트 과제는 없었고 시험과 프로그래밍 과제 뿐이었으며 시험이 많이 어려워서 꽤 디테일하게 공부를 하게 만들었다. 프로그래밍 과제는 알고리즘을 제대로 이해하고 구현하게 만드는 과제가 많았지만 보통 3D size array를 이리저리 굴리는 로직이다보니 디버깅에 쓸데없이 많은 시간도 들이고 머리도 꽤나 굴렸던 기억이 난다. 배운 건 많았지만 내 커리어에 유용할지는 여전히 의문이 남는 과목이다. (그리고 유일하게 A를 받았다 ㅠㅠ)
내가 UIUC에서 Professional Degree를 선택하게 된 계기는 회사에서 지원해줘서 고민을 시작하게 된 것이 컸지만, 결과적으론 내가 성장할 수 있는 발판이 되어주었다. 강의들이 꽤 알차고 수준이 높아서 CS 단일 전공이 아니었던 나로서는 내 스스로 부족하다고 느낀 점들을 메꿀 수 있는 기회가 되었다.
그리고 어렸을 적 교환학생 생활부터 이어 지금까지도 미국에 대한 접점을 지속적으로 만들어나가고 있다는 생각도 들었다. 졸업식에서나 내 학교에 처음 등교해보는 것이지만 그럼에도 불구하고 MCSDS 과정은 나에게 지속적으로 소속감을 심어주었다. 오프라인으로 수강하는 학생들도 모두 같은 과제와 수업을 들었으며, 심지어는 수업 게시판도 공유했어서 함께 공부하는 느낌이 들었다.
그래도 20대 이후로 다시 돌아가고 싶지 않을만큼 힘들고 고생했던 시간들이었다. 이제는 아름답게 추억으로 덮어두고싶고, 이렇게 글로 적으면서 대학원 생활에 마침표를 찍을까 한다. 시원섭섭한 마음이지만 이젠 안녕.
'Tech' 카테고리의 다른 글
| LLM OS? 언어모델이 제시하는 새로운 패러다임 (1) | 2023.11.25 |
|---|---|
| Vector Store: Azure Vector Search에 대하여 (0) | 2023.08.22 |
| ChatGPT Plugin이란, 구축 방법 (0) | 2023.04.25 |
| 미국 석사(MSCS) 준비 시리즈 (5) - 추천서 (0) | 2022.05.24 |
| 미국 석사(MSCS) 준비 시리즈 (4) - CV (0) | 2022.05.11 |
