
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 미국 개발자 취업
- 미국석사
- 중국플랫폼
- TFX
- HTTP
- 머신러닝
- BERT이해
- MSCS
- BERT
- 클라우드
- BANDiT
- transformer
- 언어모델
- 플랫폼
- 클라우드자격증
- llm
- 추천시스템
- 합격후기
- swe취업
- docker
- maang
- 네트워크
- chatGPT
- RecSys
- MAB
- MLOps
- 자연어처리
- 메타버스
- nlp
- AWS
- Today
- Total
SWE Julie's life
LLM Evaluation 본문
LLM 모델의 성능은 어떻게 평가할 수 있을까? LLM 모델 기반 어플리케이션을 개발하는 사람이라면 누구나 다 prompt engineering과 LLM 모델의 블랙박스에 진절머리가 나있을테다. 나 역시 LLM 프로젝트를 하면서 계속 고민했던 사항이고 아직도 답을 못내렸기 때문에 오늘은 이 글을 통해 evaluation에 대한 이야기를 나누어볼까 한다.
우리는 일반적으로 ML/DL 모델을 개발하면 ‘숫자’로 모델의 성능을 평가하려고 한다. 그 이유인 즉슨 하나의 모델도 실험해볼 것이 너무 많기 때문에 사람이 일일이 결과를 들여다보기 어려울 뿐더러, 대개 정답지가 있는 상황에서 개발되었기 때문에 숫자로 점수를 매길 수 있기 때문이다. 하지만 LLM은 생성형 AI 특성상 아웃풋의 품질에 대해 수치화하기가 참 어렵다. 그럼에도 운 좋게 정답지가 있다면 수치화된 metric으로 성능을 표현할 수 있는데 굳이 나눠보자면 아래와 같이 정리할 수 있다.
1) ground truth가 있을 때: semantic similarity를 측정
- F1 score: prediction, ground truth sentence를 bigram 단위로 나눈 다음 정답지와 예측 문장 간의 공통 단어 개수를 기반으로 precision, recall 계산 후 조화평균한다.
하지만 F1 score는 high-variance를 가진 모델인 생성형 AI에는 적합하지 않다. 예를 들어 핵심은 맞추더라도 생성된 문장이 정답지 문장보다 긴 경우 내용은 동일하더라도 공통 단어 수가 상대적으로 줄어들어 오답보다 낮은 수치로 계산될 수 있기 때문이다.
- BERTscore: BERT의 embedding 값의 similarity를 계산 (cosine distance 등)
이 metric은 F1 스코어와 다르게 문장의 길이에 따른 영향을 받지 않지는 않지만 여전히 정답의 정확도를 민감하게 수치로 반영하기 힘들다. 예를 들어 8월 15일이 정답일 때 8월 16일로 대답하더라도 임베딩 값의 차이가 크지 않을 수 있다.
- 혹은 Semantic Answer Similarity 즉 SAS라는 머신러닝 모델을 활용해본다.
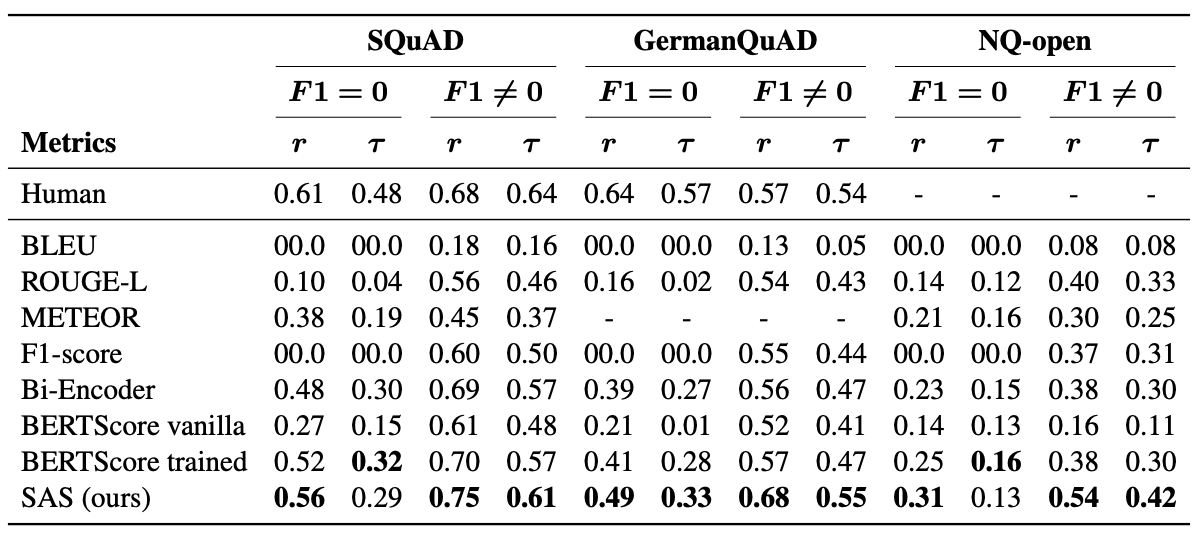
하지만 이 방법 역시 BLEU, F1-score, BERTScore보다 살짝 성능이 좋은 수준이므로 우리가 원하는 결과는 아닐 수 있다.
2) benchmark용 데이터셋을 사용: 요즈음 대세가 되고있는 방법 (글 쓰는 시기 한정, 워낙 빠르게 변하는 시장이라서..)
최근 자연어모델 도메인에서의 모델 성능 벤치마크 역할을 하는 데이터셋이 등장하였다. MMLU라고 하는데, 마치 NLP에서의 GLUE 역할을 한다. MMLU란 Massive multitask language understanding의 약어이며, UC Berkeley에서 논문을 통해 오픈한 평가 방법론이다. Official repo를 통해 평가하는 코드가 공개되어 있고 Hugging Face에서도 살펴볼 수 있다.
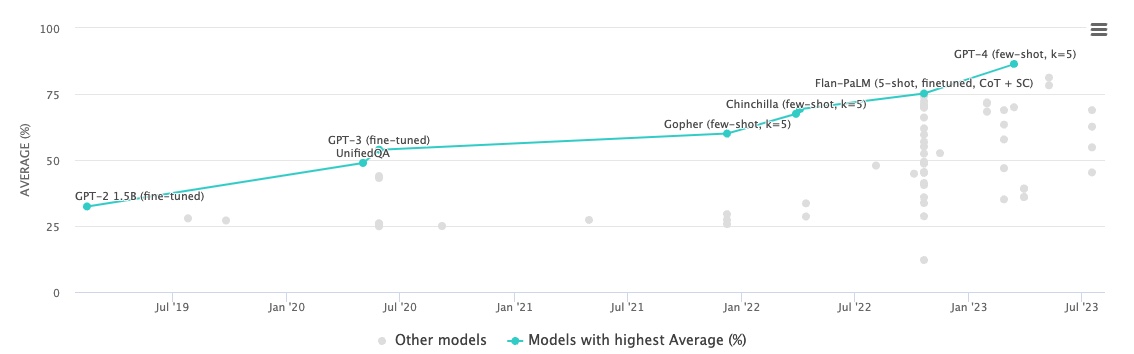
MMLU는 57가지 task로 LLM 모델의 성능을 평가한다. Task가 다루는 도메인은 여러 가지가 있는데 기초수학, 미국역사, CS, 법학 등 (STEM, humanity, social science로 보통 정리됨)을 아우르고 있다. 아래 그림이 데이터셋의 예제인데 수준은 elementary level ~ advanced professional level라고 하며 multiple choice question들로 구성되어있다. 대신 multimodal은 아니다. 하지만 논문에서 추후 보완해야할 사항으로 기재되어 있어 미래에는 multimodality 벤치마크 데이터셋도 생기지 않을까 싶다.
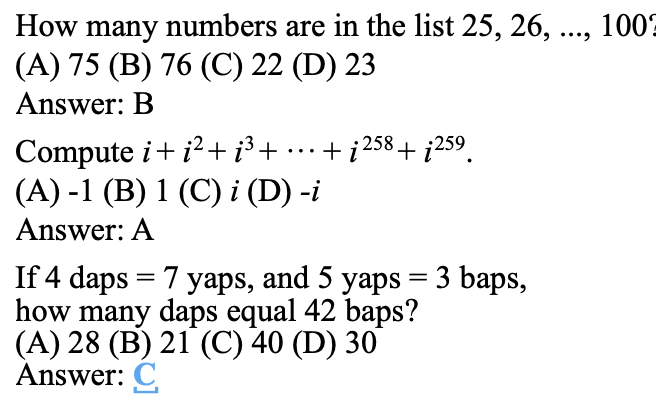
MMLU에 대해 논문 저자는 뛰어난 점수를 받는 모델은 광범위한 세계 상식과 문제 해결 능력을 갖췄다고 볼 수 있다고 말한다. 지금 글을 쓰는 날짜를 기준으로(23.08.18) GPT4가 가장 성능이 좋긴 한데 점차 오픈소스가 격차를 줄이며 따라잡고 있다고 한다. PaLM 모델도 생각보다 괜찮다는 이야기가 많이 있는 듯 하다.
요즈음은 대부분 MMLU 기반으로 모델의 성능을 줄세우지만 이 데이터셋 하나조차도 여러 방식으로 모델 평가 알고리즘을 구현할 수 있다고 한다. 사실 단일 데이터셋이라서 구현 방식에 따른 성능 차이가 얼마나 크겠냐 싶지만 아이러니하게도 customize할 수 있는 영역이 많아 여러 주요 모델을 ranking할 때 순위 차이가 크다고 한다. 아직 standard가 확립되지 않은 요즘에는 이러한 평가 방식의 차이가 좀 더 크게 와닿는다고 한다.
관련하여 Hugging face에서 논란을 한 차례 정리한 블로그가 있어 이에 대해 정리하고 간단한 내 생각을 덧붙이면서 이 글을 마무리하려고 한다. Hugging Face에서도 동일한 MMLU 데이터셋이더라도 어떻게 평가하느냐 방식에 따라 모델의 랭킹이 천차만별이라는 점을 인정하였다. (사실 단순히 생각해도 output으로 text를 기준으로 metric을 산출하느냐, text의 probability로 산출하느냐의 2가지 대안이 공존한다.)
이들에 따르면 대표로 꼽을 수 있는 평가 방식은 아래와 같이 3가지가 있다고 한다.
1) Stanford CRFM에서 내온 HELM implementation 방식 (Holistic Evaluation for Language Models)
2) MMLU 논문에서 나온 original implementation (https://github.com/hendrycks/test/pull/13)
3) AI Harness commit (Hugging Face에 있는 LLM Leaderboard, https://github.com/EleutherAI/lm-evaluation-harness/tree/e47e01beea79cfe87421e2dac49e64d499c240b4)
위 세 가지의 평가 구현방법이 조금씩 다르다. 첫 번째는 Prompt의 차이이다.(prefix, extra space 등)
| Original implementation https://github.com/hendrycks/test/pull/13 | HELM https://github.com/stanford-crfm/helm/tree/cab5d89fadbff86190f29ddfa497301958eaf2ec | AI Harness https://github.com/EleutherAI/lm-evaluation-harness/tree/e47e01beea79cfe87421e2dac49e64d499c240b4 |
| --- | --- | --- |
| The following are multiple choice questions (with answers) about us foreign policy.How did the 2008 financial crisis affect America's international reputation?A. It damaged support for the US model of political economy and capitalismB. It created anger at the United States for exaggerating the crisisC. It increased support for American global leadership under President ObamaD. It reduced global use of the US dollarAnswer: | The following are multiple choice questions (with answers) about us foreign policy.Question: How did the 2008 financial crisis affect America's international reputation?A. It damaged support for the US model of political economy and capitalismB. It created anger at the United States for exaggerating the crisisC. It increased support for American global leadership under President ObamaD. It reduced global use of the US dollarAnswer: | Question: How did the 2008 financial crisis affect America's international reputation?Choices:A. It damaged support for the US model of political economy and capitalismB. It created anger at the United States for exaggerating the crisisC. It increased support for American global leadership under President ObamaD. It reduced global use of the US dollarAnswer: |
우선 세 가지 구현방법 모두 few-shot 방식으로 prompt에 5가지 정도의 example을 추가하여 multi-choice question에 대한 응답을 짧게 추론하였다. 하지만 미묘하게 prefix가 있느냐, 지시문과 multiple-choice 사이에 개행문자가 있느냐 등의 차이가 있다. Prompt engineering을 해본 사람이라면(LLM에 데여본 사람이라면) 이 작은 차이도 때로는 전혀 다른 결과를 만들어낼 수 있다는 것에 공감할 것이다 ㅠㅠ..
prompt 외에도 모델의 점수를 산출하는 기준이 되는 평가 대상 혹은 범주를 어떻게 잡느냐도 다르다.
| Original implementation | HELM | AI Harness (as of Jan 2023) |
| --- | --- | --- |
| We compare the probabilities of the following letter answers: | The model is expected to generate as text the following letter answer: | We compare the probabilities of the following full answers: |
| A
B
C
D | A | A. It damaged support for the US model of political economy and capitalism
B. It created anger at the United States for exaggerating the crisis
C. It increased support for American global leadership under President Obama
D. It reduced global use of the US dollar |
위의 표에 따르면 original implementation (UC Berkeley)에서는 next generation token이 A, B, C, D 중에서 확률이 높은 것을 예측값으로 결정하고 정답지와 비교하지만 HELM은 전체 vocab 중에서 확률이 가장 높은 것을 예측값(A,B,C,D가 아니더라도)으로 삼아 정답과 다르면 점수를 받지 않는다.
하지만 Harness의 경우 next token generation이 아니라 answer 전체에 대한 각 token의 확률값을 aggregation해서 구한다. 여기서는 각 토큰의 probability의 logarithm 값을 모두 더해서 총 점수를 산출한다. (추가적으로 normalization을 할 수도 있는데, 분모를 각 토큰의 길이로 두는 것이 하나의 옵션이라고 한다)
이렇게 정리하더라도 아직 어떤 방법이 좀 더 standard한지에 대해 공통의 합의점이 없다는 것이 hugging face 쪽의 결론이다. 그들은 특정 쓰레드에서 여러 사람들의 의견을 모아보겠다며 한 발자국 물러선 모습을 보였다. 저 쓰레드를 대충 읽어봤을 땐 뚜렷하게 어떤 방향으로 이야기가 흘러가고 있는 것 같진 않아 보였다.
사실 생성형 AI의 특성상 성능을 수치화해서 평가하기가 쉽지 않을 뿐더러 디자인을 어떻게 하느냐도 개인의 관점에 따라 판단이 모두 다를 것이라 아마 많은 모델들이 각자가 좋은 결과를 내는 metric으로 디자인되지 않을까 싶다. 이것도 시간이 어느 정도 흐르고 나면 주류가 되는 벤치마크가 standard로 자리잡힐 것 같은데 MMLU가 그 기준이 될지 아니면 다른 새로운 데이터셋과 평가방식이 그러할지는 지켜봐야할 것 같다. 개인적으로는 좀 더 LLM이 수행하는 task가 카테고리화로 정리가 되고, 그 분류에 따라 모델의 평가 방식이 어떤 것이 적합할지에 대한 암묵적인 합의가 생길 것 같다는 생각이 든다.
'Tech > ML, DL' 카테고리의 다른 글
| GPT 말 잘듣게 하는 법 - Prompt 작성 팁 (0) | 2023.10.09 |
|---|---|
| [오피니언] GPT 등장 이후 시장은 어떻게 변화하고 있나, 우리는 어떻게 대응하나? (2) | 2023.08.23 |
| Quantization (0) | 2023.08.18 |
| W&B Prompts: LLMOps, 언어모델 E2E 대시보드 (0) | 2023.05.01 |
| LLM으로 어플리케이션 만들기 - LangChain이란 (0) | 2023.04.09 |


