
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- BANDiT
- 자연어처리
- 중국플랫폼
- 메타버스
- 미국 개발자 취업
- nlp
- maang
- AWS
- TFX
- 미국석사
- HTTP
- BERT이해
- 추천시스템
- 클라우드
- 합격후기
- swe취업
- 머신러닝
- MSCS
- MLOps
- MAB
- 플랫폼
- RecSys
- transformer
- chatGPT
- 네트워크
- llm
- 언어모델
- 클라우드자격증
- docker
- BERT
- Today
- Total
SWE Julie's life
LLM으로 어플리케이션 만들기 - LangChain이란 본문
최근 ChatGPT의 흥행 이후 많은 LLM 기반 패키지들이 생겨나고 있다. 마치 물이 들어오기를 기다리고 있었던 선박들 마냥 기존의 라이브러리를 확장해서 오픈 소스로 공개하기도하고, 기존 서비스에 extension으로 확장해서 사용할 수 있게끔 기능을 제공하는 등 LLM ecosystem이 더 풍부해지고 있다.
그 중에서도 오늘 글은 LangChain이란 LLM으로 E2E Application을 개발할 수 있도록 해주는 프레임워크에 대해 다뤄볼 것이다. 개인적으로 독스나 코드를 보며 여러 방면에서 가려운 곳을 정확히 긁어주고 있어 감동(?)받았었다.
LangChain은 여러 모듈로 구성되어있는데, 그 모듈들로 Application을 아래와 같이 확장해나갈 수 있다.
- LLMs: LM에 input을 넣어 prediction
- Prompt Template: prompt 매니징
- Chains: LLM과 prompt의 결합체들로 multi-step workflow를 구성
- Agents: 유저 인풋에 따라 Chain을 ‘동적’으로 call. 여기서 ‘동적’이라는 의미는 순서가 정해져있지 않다는 것
- Memory: Chain, Agent에 State를 추가
여기서 LLM, Prompt보다는 Chains, Agents, Memory가 LangChain의 핵심 block이라고 할 수 있다.
그 중에서도 Chain이 LangChain 이름 자체가 암시하는 것처럼 LLM기반 Application의 큰 구조물(?)이라고 할 수 있다. Chain을 여러 개를 엮어 Application을 구성하는 방식이라 생각하면 된다.
우선 LangChain이 제공하고 있는 모듈에 대해 한 눈으로 크게 살펴본 뒤, 세세하게 하나씩 설명을 읽으면 이 라이브러리가 전반적으로 어떤 영역을 커버해줄 수 있는지에 대해 쉽게 파악할 수 있다.
Modules at a glance
- Indexes
- Document Loaders - langchain.document_loaders
- Azure Blob Storage File / Container, S3 Directory / File
- BigQuery Loader
- CSV, DataFrame Loader
- URL, Email, Youtube, GoogleDrive, PowerPoint, PDF, Notion… 등
- 파일 포맷외에 클라우드 스토리지 서비스와의 연결, 웹기반 서비스, 어플리캐이션 데이터 모두 지원
- Text Splitters - langchain.text_splitter
- LaTex, Markdown, NLTK, Python Code, spaCy, Tiktoken.. 등
- Vectorstores - langchain.vectorstores
- Redis, AtlasDB, Chroma, Deep Lake, ElasticSearch, FAISS…
- Document 혹은 LLM이 참고해야할 정보를 원문/임베딩한 형태로 저장하는 스토리지 등이 포함
- Retrievers - langchain.retrievers
- ChatGPT Plugin Retriever
- VectorStore Retriever
- ElasticSearch BM25
- Document Loaders - langchain.document_loaders
- Prompts - langchain.prompts
- Prompt Templates
- Chat Prompt Template
- System + Human messages
- Example Selector
- Length-based, NGram, Similarity…
- few-shot prompt를 만들 때 사용해볼 수 있음
- Output Parser
- Pydantic, Comma Separated Lists, Retry Output, Structured…
- Models
- LLMs - langchain.llms
- async, cache, serialize, stream, track token usage 가능
- Azure OpenAI, OpenAI, SageMaker Endpoint 등, 기타 여러 오픈소스 LLM 지원
- Chat Models - langchain.chat_models
- Text Embedding Models - langchain.embeddings
- LLMs - langchain.llms
- Chains - langchain.chains
- LLM Chain
- Question Answering
- Retrieval Question / Answering
- Vector DB Text Generation
- LLM Math
- Memory - langchain.memory
- BufferMemory
- Entity Memory
- Knowledge Graph Memory
- SummaryMemory
- TokenBufferMemory
- Agents - langchain.agents
- Tools
- ChatGPT Plugins
- Google Search
- Human as a tool
- Agents
여기에 모든 모듈들을 포함할 순 없어서 주요 항목들만 나열하였는데, 대략 아래와 같은 흐름으로 활용하면 되겠다는 구상이 될 것이다.
데이터 로딩(indexes) → 프롬프트 만들기 (prompt) → LLM 모델 생성 (llms) → 이들을 연결 (chains) → 이전 대화를 기억하여 답변을 줄 수 있는 메모리를 생성 (memory) → 그 외 기타 기능(검색/연산 등)을 붙여 Agent 생성 (agent)
출처 입력
Chains
Chain은 단순히 하나의 Prompt로 LLM을 다루는 것을 넘어서 이들간의 조합을 workflow로 구성할 수 있다.
가장 간단하게는
1) 유저 input을 받고
2) PromptTemplate으로 만들어
3) LLM으로 이를 포맷팅하여 넘기는 workflow를 만들 수 있다.
LangChain 독스에 있는 튜토리얼 코드로 보면 Chain을 어떻게 활용할 수 있는지 알 수 있다.
예제는 '상품명'을 input으로 받아 회사명을 창의적으로 작명해주는 LLM 을 만들고 있다.
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt) # Prompt + LLM을 결합하는 LLMChain
chain.run("colorful socks")
# -> '\n\nSocktastic!'위 코드 스니펫에 쓰인 LLMChain이 가장 기본적인 Chain이고, ConversationChain이라 하여 여기에 메모리를 추가한 Chain도 있다(= Memory + PromptTemplate + LLM).
Memory
Memory는 우리가 ChatGPT를 봤을 때와 같이 Chain, 혹은 Agent가 일종의 ‘기억’을 갖는 것처럼 만들어주게 된다. 아래 MemPrompt의 예시처럼, 어느 external한 store에 유저의 Feedback 데이터를 저장해두고, Q에 해당하는 feedback이 있었는지를 지속적으로 체크하면서 응답을 주는 방식이다.
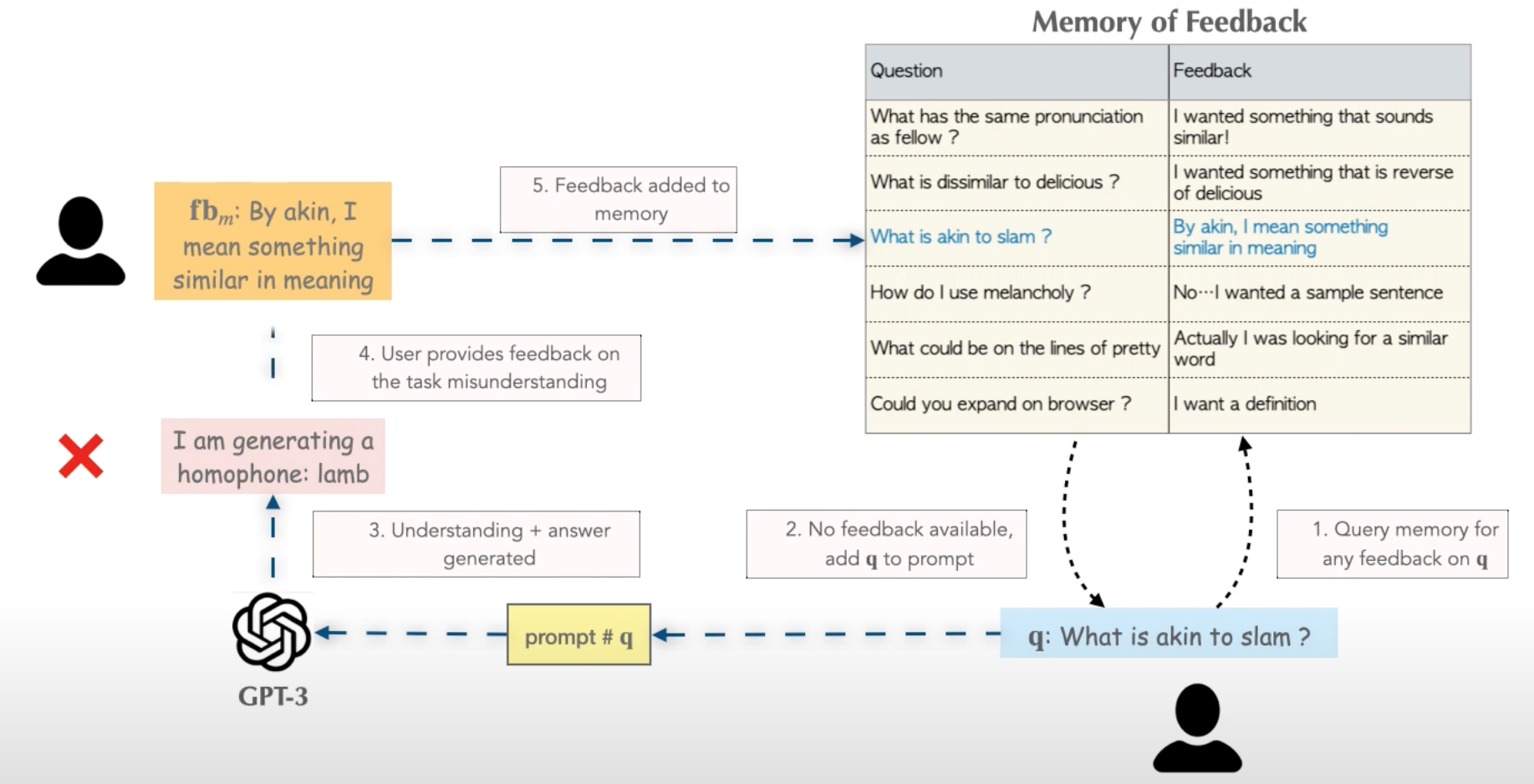
가장 간단한 ConversationBufferMemory는 아래와 같다. 코드가 많기보단 텍스트가 많아 따로 설명은 적지 않았다.
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
conversation = ConversationChain(
llm=llm,
verbose=True,
memory=ConversationBufferMemory()
)
conversation.predict(input="Hi there!")
# > Entering new chain...
# Prompt after formatting:
# The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context.
# If the AI does not know the answer to a question, it truthfully says it does not know.
# Current conversation:
# Human: Hi there!
# AI:
# > Finished chain.
#' Hello! How are you today?'
conversation.predict(input="I'm doing well! Just having a conversation with an AI.")
# > Entering new chain...
# Prompt after formatting:
# The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context.
# If the AI does not know the answer to a question, it truthfully says it does not know.
# Current conversation:
# Human: Hi there!
# AI: Hello! How are you today?
# Human: I'm doing well! Just having a conversation with an AI.
# AI:
# > Finished chain.
#" That's great! What would you like to talk about?"Buffer 외에도 여러 형태로 정보를 저장하게 되는데, 몇 가지만 나열해보면 아래와 같다.
- Entity Memory
- 말 그대로 Entity 형태로 메모리를 구성하는 것이다.
- Entity 형태로 정보를 추출하기 위해서 LLM을 활용한다.
- Prompt에 Dictionary 형태로 Entity Memory를 제공하게 되고, LLM은 그 정보를 기반으로 대화를 이어나가는 형태이다.
- 직접적으로 메모리에 접근하여 엔티티를 return받을 수 있다.
- conversation.memory.store
- >> {'Deven': 'Deven is working on a hackathon project with Sam.'}
- conversation.memory.store
- Knowledge Graph Memory
- Prompt에 relevant information이란 항목으로 제공하게 된다. KG 메모리를 붙인 경우 Prompt가 아래와 같이 포맷팅되어 LLM에게 input된다고 생각하면 된다.
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. The AI ONLY uses information contained in the "Relevant Information" section and does not hallucinate.
Relevant Information:
On Will: Will is an engineer.
Conversation:
Human: What do you know about Will?
AI:-
- 마찬가지로 엔티티에 대해 direct로 접근할 수 있다.
- memory.get_knowledge_triplets("her favorite color is red")
- >> [KnowledgeTriple(subject='Sam', predicate='favorite color', object_='red')]
- memory.get_knowledge_triplets("her favorite color is red")
- 마찬가지로 엔티티에 대해 direct로 접근할 수 있다.
- Conversation Summary Memory
- 앞서 말했듯, Prompt에 대화내용을 그대로 넣게 되면 토큰 수 제한 때문에 긴 시간, 혹은 방대했던 대화 기록은 담을 수 없게 된다. 이를 극복하기 위해 마찬가지로 LLM을 이용해서 내용을 요약한 것을 Prompt로 넣는 메모리이다.
- interaction 횟수만큼으로 기억을 제한할 수도 있고, Token 개수만큼 메모리 윈도우를 제한할 수도 있게 된다.
이 외에 Database를 message memory로 사용하여 Back up하는 경우도 있다. (Redis 등)
이에 대해서는 official docs 링크만 걸어두겠다:
Agents
Agent는 LangChain이 만들고자 했던, LLM을 궁극적으로 활용하는 모듈이라는 생각이 든다.
Agent는 LLM을 이용하여 어떤 Action*이 어느 단계에서 이루어져야하는지 판단하여 task를 수행한다.
* action이란 간단하게는 output을 유저에게 리턴하는 것부터 tool*을 사용하는 등의 행위를 모두 의미한다.
* tool: 특정한 임무를 수행하는 function. Google Search, DB Lookup, Python REPL 등이 해당될 수 있다.
예를 들어 검색과 산수 기능을 보유한 Agent를 만들고 싶을 경우, 이러한 tool들을 지정하여 Agent를 initialize할 때 함께 로드하게 되면 Agent가 유저의 input을 처리하기 위해 어떤 스텝을 밟아야하는지 생각하게 된다. 코드로 보면 더 쉽게 이해할 수 있다.
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
# First, let's load the language model we're going to use to control the agent.
llm = OpenAI(temperature=0)
# Next, let's load some tools to use. Note that the `llm-math` tool uses an LLM, so we need to pass that in.
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# Finally, let's initialize an agent with the tools, the language model, and the type of agent we want to use.
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
# Now let's test it out!
agent.run("What was the high temperature in SF yesterday in Fahrenheit? What is that number raised to the .023 power?")LLM에게 San Francisco의 어제 날씨를 묻고, 그에 간단한 수학 연산한 값을 물어보고 있다.
verbose=True로 셋팅하고 Output을 보게되면 아래와 같다.
> Entering new AgentExecutor chain...
I need to find the temperature first, then use the calculator to raise it to the .023 power.
Action: Search
Action Input: "High temperature in SF yesterday"
Observation: San Francisco Temperature Yesterday. Maximum temperature yesterday: 57 °F (at 1:56 pm) Minimum temperature yesterday: 49 °F (at 1:56 am) Average temperature ...
Thought: I now have the temperature, so I can use the calculator to raise it to the .023 power.
Action: Calculator
Action Input: 57^.023
Observation: Answer: 1.0974509573251117
Thought: I now know the final answer
Final Answer: The high temperature in SF yesterday in Fahrenheit raised to the .023 power is 1.0974509573251117.
> Finished chain.위와 같이 Agent가 질문에 따라 어떤 action을 수행해야하는지, 그 action을 수행하기 위한 툴은 무엇인지, 툴을 통해 얻은 중간 결과값(observation)을 활용하여 온전한 답을 생성하기 위해 추가적인 단계는 어떤 것이 있는지를 파악하는 과정을 볼 수 있다. GPT등 LLM모델이 특성상 수학 연산 능력이 부족하다는 등의 한계가 있다는 점을 보완할 수 있는 llm-math와 같은 툴을 제공하고 있다.
이처럼 최종 output을 내기 위해서 어떤 Action을 단계별로 수행해야하는지에 대해 판단한다. 중간 결과를 계속해서 관측(Observation)하면서 단계를 이어나가고, 각 중간 결과에 따라 다음 Step에서 어떤 Action을 수행해야하는지를 지속적으로 판단한다.
이러한 Agent의 response에서의 각 intermediate step들도 직접적으로 접근하여 추출할 수 있다.
print(response["intermediate_steps"])[(AgentAction(tool='Search', tool_input='Leo DiCaprio girlfriend', log=' I should look up who Leo DiCaprio is dating\nAction: Search\nAction Input: "Leo DiCaprio girlfriend"'), 'Camila Morrone'), (AgentAction(tool='Search', tool_input='Camila Morrone age', log=' I should look up how old Camila Morrone is\nAction: Search\nAction Input: "Camila Morrone age"'), '25 years'), (AgentAction(tool='Calculator', tool_input='25^0.43', log=' I should calculate what 25 years raised to the 0.43 power is\nAction: Calculator\nAction Input: 25^0.43'), 'Answer: 3.991298452658078\n')]아래 케이스들을 보면 이 모듈이 얼마나 파워풀한가를 좀 더 체감할 수 있다.
- JSON Agent
- JSON blob 파일이 큰 경우에도 (LLM의 context window보다 더 큰) Agent를 이용하여 파일 내용에 대한 질의를 할 수 있다고 한다. 튜토리얼에서는 OpenAI API Spec을 읽어 질문에 대한 응답을 생성하는 Agent를 보여준다. verbose=True로 셋팅해서 LLM이 어떻게 chain of thoughts를 이어나갔는지 살펴보면 더 놀랍다.
json_agent_executor.run("What are the required parameters in the request body to the /completions endpoint?")
# > "The required parameters in the request body to the /completions endpoint are 'model'."- Python Agent
- Python으로 요구사항을 적으면 응답을 작성해주는 Agent이다.
- 하위에 Pandas Dataframe Agent도 있다.
agent_executor.run("What is the 10th fibonacci number?")
# > Entering new AgentExecutor chain...
# I need to calculate the 10th fibonacci number
# Action: Python REPL
# Action Input: def fibonacci(n):
# if n == 0:
# return 0
# elif n == 1:
# return 1
# else:
# return fibonacci(n-1) + fibonacci(n-2)
# Observation:
# Thought: I need to call the function with 10 as the argument
# Action: Python REPL
# Action Input: fibonacci(10)
# Observation:
# Thought: I now know the final answer
# Final Answer: 55
# > Finished chain.- Evaluation 모듈이 있는데, 이 역시도 Language Model을 이용하여 LLM이 응답한 결과에 대해 옳고 그름을 판단하게 된다.
from langchain.evaluation.qa import QAEvalChain
## EvalChain 생성
llm = OpenAI(temperature=0)
eval_chain = QAEvalChain.from_llm(llm)
## Evaluate
graded_outputs = eval_chain.evaluate(dataset, predictions, question_key="question", prediction_key="output")
for i, prediction in enumerate(predictions):
prediction['grade'] = graded_outputs[i]['text']
from collections import Counter
Counter([pred['grade'] for pred in predictions])
# > Counter({' CORRECT': 4, ' INCORRECT': 6})이렇게 유용한 Agent 모듈을 활용할 때 한 가지 주의해야할 점은 어떤 행위를 진행해야하는지, 중간 결과를 어떻게 처리할지 등의 중간 판단 과정에 모두 LLM을 이용한다는 것이다. 즉 LLM API를 매번 call한다는 것이다. 이 때문에 하나의 질문이라도 call이 다회가 되기 때문에 비용 추산을 잘 해야한다.
정리
간단한 챗봇 시스템을 만든다고 했을 때 아래 소스코드가 참고하기에 적합할 것이다.
## 1. Text로 Chroma DB 구축
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union) # 임베딩 토큰 길이 제한에 맞추어 Text를 split
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))])
## Q와 연관도가 높은 문서 추출
query = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(query)
## 연관 문서로 Prompt -> Prediction 실행
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
template = """You are a chatbot having a conversation with a human.
Given the following extracted parts of a long document and a question, create a final answer.
{context}
{chat_history}
Human: {human_input}
Chatbot:"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input", "context"],
template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain(OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt)
chain({"input_documents": docs, "human_input": query}, return_only_outputs=True)
이외에 자주 하는 질문에 대한 응답은 캐싱을 해두어 Call횟수나 Latency를 줄이는 방법이 있다.
뿐만 아니라 목적에 따라 적합한 파라미터들로 pre-set된 LLM모델을 serialize해서 어느 환경에서든 동일 모델을 서빙할 수 있게끔 구성할 수도 있다.
또한 여러 사람이 동시에 LLM을 호출해야하는 상황이라면 비동기로 함수를 구성할 수 있어(asyncio 지원) 다회의 콜이 있을 때 응답 latency를 낮춰볼 수 있다.
이 외에도 최신 정보가 필요한 경우 검색엔진 tool을 로드하여 Agent를 구성하면 적절한 단계에 검색엔진 결과를 참조하여 응답을 생성하게 된다.
마지막으로 prompt 템플릿을 제공한다는 점에서 유용하다는 이야기로 이 글을 마무리하려고 한다.
요즘 prompt가 점차 자산화가 되고 있다. 양질의 prompt를 어떻게 구성할 것인지에 대한 아이디어를 얻는다는 목적에서 docs를 한 번 살펴보는 것도 유의미하다. LLM에게 내가 원하는 방향대로 response를 주도록 구성하기 위해서는 적절한 instruction을 작성해야한다. 아래 prompt도 한 번 읽어보기를 바란다.
Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics.
As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving.
It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions.
Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics.
Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
'Tech > ML, DL' 카테고리의 다른 글
| Quantization (0) | 2023.08.18 |
|---|---|
| W&B Prompts: LLMOps, 언어모델 E2E 대시보드 (0) | 2023.05.01 |
| ChatGPT란? - 기술과 활용법, 개인견해까지 (0) | 2023.02.16 |
| Inductive Bias : ML/DL 모델 디자인에 대하여 (0) | 2023.01.12 |
| BERT - (4) BERT 이해하기 (0) | 2022.12.20 |



