
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- maang
- transformer
- swe취업
- llm
- BERT이해
- 클라우드
- 미국 개발자 취업
- 머신러닝
- MLOps
- 자연어처리
- 미국석사
- AWS
- BANDiT
- 메타버스
- docker
- nlp
- MAB
- 추천시스템
- RecSys
- 언어모델
- 네트워크
- BERT
- 중국플랫폼
- HTTP
- 플랫폼
- TFX
- 클라우드자격증
- 합격후기
- MSCS
- chatGPT
- Today
- Total
SWE Julie's life
MLOps - (2) GCP TFX 기반 ML시스템 아키텍쳐 이해 본문
MLOps 의 서비스 플로우를 이해하기 위해서 GCP에서 제공하는 TFX 기반 ML 시스템 아키텍쳐를 살펴보기로했다.
MLOps 서비스는 모델을 어떻게 하면 지속적으로 관리하고 배포할 수 있을지에 대한 파이프라인을 설계해야한다. 이를 CI/CD 파이프라인이라고 부른다.
Glossary
TFX : Tensorflow Extend, ML을 빌드하고 배포하기 위한 통합 플랫폼
CI/CD 파이프라인 : CI(지속적 통합), CD(지속적 배포)
TFX의 주요 라이브러리
- TFDV (Data Validation) : 데이터 이상치 감지
- TFT (Transform) : 데이터 전처리 및 특성 추출을 위해 사용
- Estimators and keras : ML 모델 빌드 및 학습에 사용
- TFMA(Model Analysis) : 모델 평가 및 분석에 사용
- TFServing : REST 및 gRPC API로 제공하기 위해 사용
TFX ML 시스템 flow chart
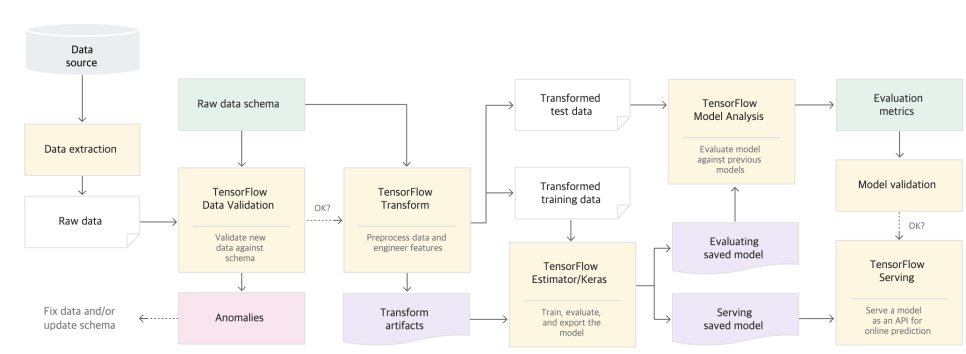
TFX ML 시스템 개요
TFX의 주요 라이브러리가 어떤 STEP에서 사용되는지를 정리하면 아래와 같다.
데이터 수집을 생략하고, 데이터를 준비하여 모델 서빙하는 데까지의 단계를 순차적으로 표현했다.
1) raw data에서 데이터 추출 이후 TFDV 적용 (데이터 검증)
2) 1)에서 이상치가 없는 것을 확인 후 TF 라이브러리 적용 (데이터 전처리, feature 가공)
3) 2)에서 생성된 train / test data 중 train data로 TF Estimator/Keras로 모델 학습/평가, test data는 model analysis 라이브러리로 모델 평가
4) 모델 평가 측정값을 바탕으로 모델 검증을 거친 후 Serving
출처 : Google Cloud MLOps 가이드문서 - https://cloud.google.com/solutions/machine-learning/architecture-for-mlops-using-tfx-kubeflow-pipelines-and-cloud-build?hl=ko
'Tech > MLOps' 카테고리의 다른 글
| MLOps, 머신러닝 파이프라인 설계 - (2) TFX, Apache Beam 개요 (1) | 2021.09.01 |
|---|---|
| MLOps, 머신러닝 파이프라인 설계 - (1) 개요 (1) | 2021.09.01 |
| 도커 - 네트워킹 / bridge와 overlay (0) | 2021.05.30 |
| Spark, Zeppelin, Scala에 대해 (0) | 2021.05.12 |
| MLOps - (1) MLOps란? ML Pipeline에 대해 (0) | 2021.05.12 |


