
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- AWS
- COFIBA
- Collaborative Filtering Bandit
- docker
- 추천시스템
- HTTP
- TFX
- 클라우드자격증
- 중국플랫폼
- 네트워크
- chatGPT
- transformer
- MLOps
- 플랫폼
- RecSys
- 언어모델
- aws자격증
- nlp
- 자연어처리
- BERT
- MSCS
- 머신러닝
- llm
- MAB
- BANDiT
- 클라우드
- 메타버스
- BERT이해
- 미국석사
- 머신러닝 파이프라인
- Today
- Total
목록Tech (120)
Julie의 Tech 블로그
 Kaggle Case Study - (2) LightGBM 모델
Kaggle Case Study - (2) LightGBM 모델
오늘은 Santender Customer Transaction Prediction 모델에서 우승팀 중 하나가 사용했던 lightGBM 모델의 논문을 살펴본 결과를 공유할 것이다. 모델이 뿌리를 두고 있는 앙상블 기법과 GBT 모델에 대해 간단히 살펴보고, lightGBM이 새로 도입한 두 가지 기법에 대해 알고리즘적으로 살펴볼 것이다. 이 모델의 근간이 되는 GBM과 앙상블에 대해 정리된 글은 아래 링크에 있다. https://blog.naver.com/ilovelatale/222320553535 앙상블과 GBM(Gradient Boosting) 알고리즘 Kaggle 필사를 하다 보면 가장 흔하게 사용되는 모델들이 있다.예를 들어 XGBoost와 lightGBM 모델... blog.naver.com ..
 딥러닝 기초 - Keras 함수형 API, callback
딥러닝 기초 - Keras 함수형 API, callback
딥러닝 프레임워크 중 하나인 keras는 모델을 빌드할 때 두 가지 방법으로 할 수 있다. 첫째는 함수형 API이고, 두 번째는 Sequential 모델을 사용하는 것이다. Sequential 모델은 input과 output이 하나라고 가정한다. 여러 경우에는 sequential 모델을 사용해도 문제가 없지만, 데이터 소스가 다양할 때 등 일부 case에서는 함수형 API가 필요할 때도 있다. 예를 들어 텍스트 데이터와 이미지 데이터, 메타 데이터 세 가지를 합쳐 각각 모델을 만들고, 모델의 결과를 가중평균하여 output을 낸다고 할 때, 이 때는 input과 output이 하나가 아니기 때문에 함수형 API가 필요하게 된다. 또한 Google의 Inception module이나 Resnet..
 머신러닝 기초 - 분류, 모델 평가, 과적합에 대해
머신러닝 기초 - 분류, 모델 평가, 과적합에 대해
분류 머신러닝은 학습 타입에 따라 아래와 같이 구분해볼 수 있다. - 지도학습 : 정답 데이터(target)가 있는 것. 대부분 분류와 회귀 추가로 시퀀스 생성, 구문 트리 예측, 물체 감지, 이미지 분할 등이 있음 - 비지도 학습 : input 데이터에 대한 변환을 찾아내는 것. 차원축소, 군집 등이 해당 - 자기 지도 학습 : label이 필요하지만, input 데이터로부터 생성. 사람이 개입되지 않는 지도 학습 - 강화 학습 : 보상을 최대화하는 행동을 선택하도록 학습하는 것. 대부분 게임에 집중되어있음 모델 평가 우리가 어느 도메인에서 머신러닝을 돌리더라도, 항상 '일반적인' 모델을 세우고자 노력한다. '일반적'이라는 것은 어느 특정한 데이터 셋에 한정된 모델이 아니라는 것인데, 이를 위해 과..
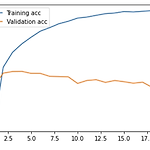 딥러닝 기초 - 사례로 배우는 이진분류 모델링
딥러닝 기초 - 사례로 배우는 이진분류 모델링
keras의 인터넷 영화 DB(IMDB)로 이진분류 모델링을 실습해볼 것이다. from keras.datasets import imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = {}) num_words 파라미터는 시퀀스에서 가장 빈번하게 등장하는 상위 x개 만큼을 사용하겠다는 것이다. 1만개를 적용하게 되면 상위 1만개 빈번 단어가 출력된다. train_data를 프린트해보면 알겠지만, 여러 정수형 원소들이 들어있는 리스트의 묶음체이다. 신경망에는 숫자 리스트를 input할 수 없어, 리스트를 텐서로 변환해야한다. 두 가지 방법 정도로 정리할 수 있는데, 1) 리스트에 패딩을 추가하여 시퀀..
 딥러닝 기초 - 텐서(Tensor)와 신경망 학습 과정
딥러닝 기초 - 텐서(Tensor)와 신경망 학습 과정
딥러닝 모델 공부 시작 전에, 기초를 다시 잡고 간다는 마음으로 텐서와 딥러닝 역사에 대해 간략하게 살펴보았다. 우선 텐서부터 짚고 넘어가자. 텐서는 데이터를 담는 컨테이너로도 볼 수 있다. 스칼라인 0 차원 텐서부터, 1차원 벡터, 2차원 행렬, 고차원 텐서 등이 있다. 텐서의 속성으로는 축(rank)과 크기(shape)가 있다. 타입은 float32, uint8, float64가 있다. 실제 딥러닝에 사용되는 사례들로 텐서들을 분류해보면 아래와 같다. 1. 벡터 데이터 : (samples, features) 2. 시계열 데이터 : (samples, timesteps, features) 3. 이미지 : (samples, height, width, channels) or (samples, chan..
 Kaggle Case Study - (1) Santander Customer Transaction Prediction
Kaggle Case Study - (1) Santander Customer Transaction Prediction
본 카테고리는 Kaggle Case study를 통해 학습데이터 구성부터 모델 빌딩까지의 cycle 경험을 늘려보려고 한다. 참고한 코드는 아래 링크에서 확인 가능하다. Santander Customer Transaction - EDA / FE / LGB https://www.kaggle.com/gunesevitan/santander-customer-transaction-eda-fe-lgb Santander Customer Transaction - EDA / FE / LGB Explore and run machine learning code with Kaggle Notebooks | Using data from Santander Customer Transaction Prediction www.kaggle..