
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- chatGPT
- docker
- maang
- 미국석사
- TFX
- RecSys
- 자연어처리
- llm
- swe취업
- 네트워크
- BERT이해
- HTTP
- 머신러닝
- 클라우드자격증
- 클라우드
- 중국플랫폼
- 추천시스템
- transformer
- MAB
- AWS
- BERT
- MSCS
- 합격후기
- BANDiT
- 미국 개발자 취업
- 메타버스
- nlp
- 언어모델
- MLOps
- 플랫폼
- Today
- Total
SWE Julie's life
이상탐지, Anomaly Detection 본문
우리는 생각보다 빈번히 특정 데이터가 이상 데이터인지를 판단해야한다. 이러한 경우에는 분류 모델로도 접근할 수 있지만, 이상탐지 모델이 더 적합할 때가 있다.
이상탐지 모델은 흔히 공정 과정에서 생산되는 이미지 데이터에 적용하는 경우가 많다. 실제로 대표적인 이상탐지 모델들은 딥러닝계열 모델들이다. 그외엔 시계열 데이터에 적용되는 모델들이 있다. 시계열 데이터도 공정과 같은 일정한 프로세스에서 생산된 데이터를 시간 기반으로 놓고 어떤 부분에서 특이 패턴이 나타나는지를 탐지한다.
좀 더 리서치를 해보면 이 외에도 더 많은 분야에서 이상탐지 모델들을 활용하곤 한다. 실제로 카드사에서도 고객들의 카드결제 내역을 바탕으로 이상탐지를 판단할 때가 있다고 한다.
전통적인 이상감지 방법은 세 가지가 있다. 우리가 흔히 아는 통계에서 outlier를 분류하는 기준인 3-sigma가 그 첫 번째이다. 3-sigma는 3*표준편차 범위 만큼은 정상 범주에 속하는 데이터로 보고, 그 외의 범위에 존재하는 데이터들을 이상치로 판단한다. 두 번째는 boxplot으로 사분위수를 정하여 데이터의 outlier를 정하게 된다. 마지막은 ARIMA로 시계열 데이터 기반 모델인데, 다변량 변수가 아닌 univariate, 단변량 변수 즉 변수가 하나인 데이터에 적용되곤 한다. 이 모델들은 모두 데이터가 단순하기 때문에 지금의 데이터에 적용하기는 어렵다. 단순하다는 것은 단변량, 즉 변수가 하나라는 의미이다.
* ARIMA 모델이란?
- univariate time series, 단변량 모델
AR : 자기회귀모형 - 현재 데이터는 과거 데이터로 설명이 가능하다는 취지
MA : 이동평균모형 - 충격이 발생했을 때 평균으로 이동하고자 하는 취지, 정상성(Stationary) 모형
AR + MA = ARIMA
ARIMA는 현재의 관측치가 과거의 어떠한 규칙성에 의해서 재현되며, 이러한 규칙성은 미래에도 유지된다고 가정하고 미래를 예측하는 모델
** Stationary Process : 정상 프로세스, 시간과 관계없이 평균과 분산이 일정한 시계열 데이터. ARIMA모델과 VAR모델 사용시에는 데이터의 stationary(정상성)를 체크해야함
지금의 이상탐지 모델들은 어떤 기준으로 비정상이라고 판단하느냐에 따라 분류를 세 가지로 나눌 수 있다 :
- Point Anomaly : 정상 데이터 분포로부터 벗어난 데이터
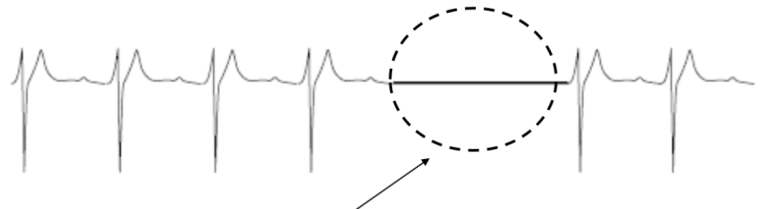
- Contextual Anomaly : 데이터 흐름 혹은 맥락상 정상이 아닌 데이터
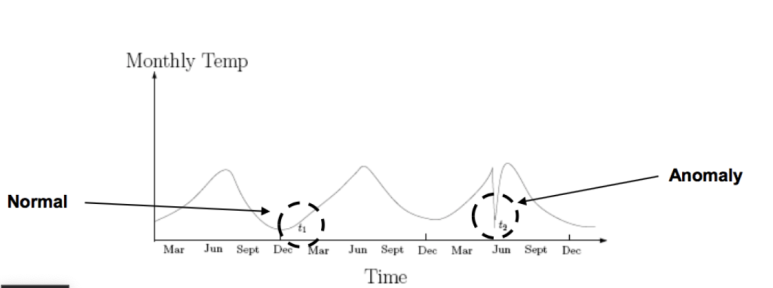
- Group Anomaly : 단일 데이터만 봤을 때는 정상이지만 모아놓고 보면 비정상처럼 판단되는 Anomaly
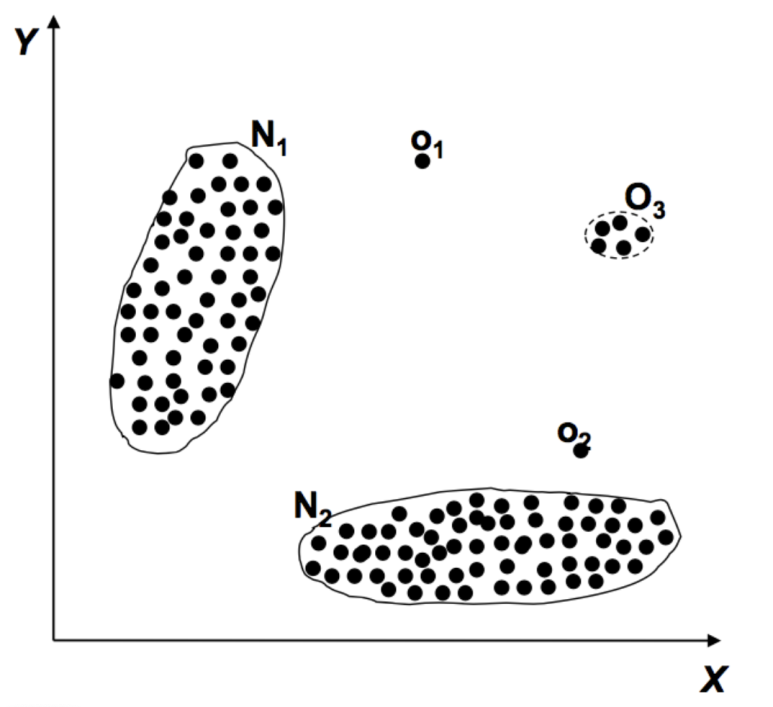
Point anomaly는 우리가 흔히 아는 anomaly 로 볼 수 있다. 데이터 내에 outlier처럼 툭 튀는 부분이 있다면 그것을 point anomaly라고 부른다. 앞에서 살펴보았던 전통적인 anomaly detection모델이 point anomaly를 탐지하기 위한 모델로 사용된다.
Contextual Anomaly는 연속적으로 데이터를 읽어들여 이상치를 감지하는데, 그림에서 보는 것처럼 예상되는 변화와 다르게 움직일 경우 anomaly로 진단한다.
반면 Group Anomaly는 단일 구간은 정상처럼 보일 수 있다. 그림에서 보는 것 처럼 일직선상으로 이어지는 그래프가 그 구간에서는 정상처럼 보일 수 있지만, 전체 데이터를 놓고 보면 반응/신호가 없는 것처럼 비정상 구간으로 판단할 수 있다.
또는 학습 시에 사용되는 정답지에 따라서 Anomaly Detection 모델을 분류할 수도 있다 :
- 지도학습기반 이상감지
- 비지도학습기반 이상감지
- 반지도학습기반 이상감지
로 총 3가지로 나뉜다.
우리가 흔히 지도학습 계열 머신러닝 모델을 많이 사용하지만, anomaly 를 탐지하는 데이터에서는 지도학습이 가능하도록 '라벨링'하는 것이 쉽지 않을 수 있다. anomaly라는 말 자체에서도 알 수 있듯이 탐지하고자 하는 데이터가 아웃라이어기에 워낙 소수이며 그 소수 데이터를 정의하기도 쉽지 않기 때문이다. 이에 따라 anomaly detection의 모델들은 대부분 비지도학습 계열로 분류된다. 흔히 Autoencoder를 사용하여 '정상'데이터만을 모델에 input하여 학습시킨 뒤 정상 패턴을 학습하는 것이다. Autoencoder는 encoder과 decoder로 나뉘는데 encoder에 데이터를 넣어 모델이 패턴을 학습한 뒤 decoder를 통해 입력된 데이터에 가깝게 복원을 한다. decoder로 생산된 데이터가 입력 데이터와 가깝도록 학습하며 '패턴'을 익히게 된다. 이후 이상 데이터를 input하게 되면 학습한 정상 패턴에서 벗어난 정도가 클 것이기 때문에 이 오차의 범위로 anomaly여부를 판단한다.
라벨링이 가능한 anomaly detection 모델들의 경우 반지도 학습으로 지도학습과 비지도학습을 섞어 사용하기도 한다.
반지도 학습 모델 중에서는 DeepSVDD라는 모델이 대표적인데, SVDD는 Support Vector Data Description의 약자로 정상 데이터만을 input하여 데이터를 다른 차원으로 표현한 뒤 그 정상 데이터 범주를 지정하는 구(Hypersphere)를 학습하게 된다. 최종적으로 이 구를 벗어난 데이터는 이상 데이터, 아닌 경우는 정상 데이터로 판단하는 것이다.
그 외에 VAR + LSTM Autoencoder로 반지도 학습 모델을 설계한 경우도 있었는데, 이 경우 LSTM Autoencoder를 사용한 이유는 Neural Network의 힘을 빌려 시계열 모형의 예측력을 좀 더 높이기 위함이었다. 모델을 좀 더 자세히 살펴보자면 "시계열 데이터를 VAR모델로 빌딩하고 LSTM Autoencoder에 VAR모델을 만들어 이상탐지"를 했다. 여기서 VAR모델은 앞에서 잠깐 등장한 ARIMA의 고도화된 버전인데, ARIMA 모델이 단변량 모델이라면 VAR은 다변량 모델이다. 둘 이상의 여러 변수로 구성된 시계열 데이터로 예측 모델을 만드는 것이다. VAR모델로 과거 데이터를 학습한 뒤 미래 데이터를 예측하도록 하였고, LSTM Autoencoder로 시계열 데이터 외의 특성들 (혹은 외부 데이터)를 결합하여 예측력을 높이고자 하였다. 그리고 저자는 이러한 multi-step training은 forgetting problem(= 머신러닝 모델이 첫번째 모델에서 학습한 것을 잊는다는 의미)을 직면할 수 있다는 점을 감안하여 각 모델들을 fine tuning했다고 한다(구체적으로 어떠하게 진행했는지는 생략되어있었다.)
* LSTM : Long-Short Term Memory. 현재 시점의 정보를 바탕으로 과거 내용을 얼마나 잊을지/기억할지를 계산, 그 결과에 현재 정보를 추가해서 다음 시점으로 정보 전달. input gate, forget gate, output gate 세 단계로 구성되어있음.
* VAR 모델이란?
- multivariate time series
- 벡터 자기회귀 모형 (내/외생 변수 구분없이 적용할 수 있는 다변량 시계열 모델)
- ARIMA와 달리 다른 변수의 변동과 시차를 함께 고려하여 변동을 설명할 수 있는 모형
- ARIMA의 다변량 일반화(multivariate generalization) 모델. (cf. 다변량 통계분석 : 여러 변인들 간의 관계성을 동시에 고려해 그 효과를 밝힘. 여러 현상이나 사건에 대한 측정치를 개별적으로 분석하지 않고 동시에 한번에 분석하는 통계적 기법)
이처럼 Anomaly Detection모델들은 다루고자 하는 데이터의 여러 상황에 따라 분류를 적절히 선정하여 사용할 수 있다.
현재 이상탐지 모델은 대부분 이미지 데이터를 기반으로 하고 있어 시계열 데이터를 이미지 데이터로 변환하여 이상탐지를 하는 모델들도 점점 등장하고 있는 추세이다.
'Tech > ML, DL' 카테고리의 다른 글
| BERT - (1) Background, Attention 이해하기 (4) | 2022.12.13 |
|---|---|
| 불균형(imbalanced) 데이터 모델링은 ROC curve를 사용을 추천하지 않는 이유 (0) | 2022.06.24 |
| Catboost 모델에 대하여 - 알고리즘, 구현 코드 (2) | 2022.06.03 |
| A/B Test in Data Science - (3) 샘플 크기는 얼마나 해야할까? 검정력 분석(Power Analysis) (0) | 2022.04.05 |
| A/B Test in Data Science - (2) ANOVA (0) | 2022.04.04 |



