
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- MAB
- 클라우드자격증
- HTTP
- 합격후기
- chatGPT
- BANDiT
- MLOps
- BERT
- MSCS
- 머신러닝
- 메타버스
- swe취업
- TFX
- BERT이해
- 플랫폼
- 미국 개발자 취업
- transformer
- 중국플랫폼
- 추천시스템
- llm
- AWS
- docker
- RecSys
- 자연어처리
- 언어모델
- 미국석사
- 네트워크
- nlp
- 클라우드
- maang
- Today
- Total
SWE Julie's life
BERT - (1) Background, Attention 이해하기 본문
Background
요즈음의 Machine Translation (MT)의 최신 모델들은 모두 BERT 혹은 BERT의 확장판을 기반으로 하고 있다. 실제로 NLP의 여러 Task들에 대한 최신 NLP모델들의 성능을 리더보드로 제공하는 Glue Benchmark(https://gluebenchmark.com/leaderboard)를 살펴보면, 대부분의 모델명에 BERT가 포함되어있는 것을 쉽게 확인할 수 있다. 따라서 NLP에 대한 이해를 하기 위해서는 BERT를 이해하는 것이 매우 중요하다고 할 수 있다.

최근에 화제가 되고있는 GPT와 BERT는 모두 Transformer 아키텍쳐를 채택하고 있다. 그렇기에 우리가 BERT를 이해하기 앞서서 Transformer 아키텍쳐를 살펴볼 필요가 있다.
오늘은 Transformer 을 제안한 논문에 대해 정리해볼 것이다. 논문의 제목이 논문의 모든 내용을 설명하는데, Attention is all you need이다. 즉 Attention만 필요하다 = Attention만 사용했다는 것인데 그럼 우리는 Attention에 대해서도 이해할 필요가 있다.
딥러닝 기반의 기계 번역의 변천사를 보자면, 1986년에 등장했던 RNN부터하여 LSTM, Seq2Seq 모델이 순서대로 2014년까지 메인으로 선두하고 있었다. RNN 모델은 Recurrent Neural Network인데 말 그대로 layer가 순서대로 stacking되는 것과는 다르게 레이어를 재사용하는 구조이다. 그래서 도식화를 보면 아래와 같이 cyclic한 화살표가 존재한다. 이는 RNN 모델이 NLP에서 좋은 성능을 보였던 이유인데, 인간이 글을 쓸 때 왼쪽에서 오른쪽으로 이전 단어에 기반해서 다음 단어를 연관지어 풀어쓰듯이 RNN 역시 이전 예측 결과를 기반으로 다음 단어의 예측결과를 만들어내게 된다.
하지만 RNN은 neural network의 고질적인 문제인 vanishing gradient descent를 안고 있어 번역하고자 하는 원문(input sequence)가 길이가 길 수록 점차 성능이 떨어졌다. 이를 long-term dependency problem이라고도 부른다.
이를 해결하고자 2015년에 Attention 아키텍쳐가 개발되었고, RNN과 결합하여 input sequence의 정보를 지속적으로 hidden layer에 넣어주게 된다. Attention이라는 명칭에서 알 수 있듯 중간 과정에서도 input에 대한 정보를 잊지 않고 주의(= paying attention)하라는 목적이라고 이해하면 쉽다.
2017년 Google이 제안한 Transformer 모델은 RNN없이 attention에만 의존하는 아키텍쳐이다. 이 논문의 출시 이후로 자연어처리 모델 트렌드는 RNN에서 Transformer 아키텍쳐로 대거 이동하게 되었다.
Attention
Attention 메커니즘에 대해 좀 더 살펴보자. Attention이 제안되기 직전까지 인기였던 모델인 Seq2Seq 모델을 이해하면 왜 이 메커니즘이 등장하게 되었는지 알 수 있다.
Seq2Seq은 인코더와 디코더로 구성되어 인코더에서는 원본 문장에 대한 학습을, 디코더는 번역하고자 하는 언어의 문장에 대한 추론/생성을 진행하게 된다.
여기서 인코더는 문장을 단어 단위로 순차적(sequential)이게 학습하게 되는데, 이 때 매 단어마다 hidden state, 은닉 상태가 중간 결과로 산출된다. 이 hidden state를 매번 다음 번의 단어를 학습할 때 input으로 넣어주게 되어 원본 문장의 끝에 다다르게 되면 하나의 context vector를 형성하게 된다. 이 context vector는 어떻게 보면 인코더를 통해 인풋으로 들어온 입력 시퀀스의 모든 정보를 담고 있는 것으로, 임의의 고정된 길이(모델의 입력 파라미터로 들어오는 embed_dim의 값)의 인코딩된 벡터라고 볼 수 있다.
Seq2Seq의 디코더는 RNNLM (RNN Language Model)으로 구성되어 있다. RNNLM이라는 의미는 단어 토큰화가 된 문장을 input으로 받았을 때 순차적으로 다음 단어 토큰이 어떤 것이 될 지를 학습하게 된다.
예를 들어 I am a student가 디코더가 뱉어야할 정답이라고 한다면 문장의 시작을 알리는 <sos> 토큰 이후에 I를 예측할 확률, 그 다음으로는 am을 예측할 확률 등으로 다음에 올 단어를 예측하고, 그 예측한 결과를 다음 시점(step)의 입력 셀에 input으로 넣게 된다. 쉽게 생각하면 우리도 문장을 작성할때 차례대로 쓰는 것과 동일하다고 볼 수 있다. 따라서 Seq2Seq모델은 인코더가 output으로 생성한 context vector와 정답인 번역본 문장(<sos> I am a student)을 입력받았을 때 I am a student <eos>를 내뱉도록 학습하면서 기계번역 모델을 만들게 된다.
이 모델의 단점은 인코더의 컨텍스트 벡터가 디코더의 첫 hidden state에만 사용되는데, 원본 문장의 길이가 길수록 과거 정보가 손실이 발생하게 되면서 성능이 떨어지게 된다. RNN의 고질적인 문제인 Vanishing Gradient가 원인이 되기 때문이다. (Long-term dependency problem이라고도 하는데 문장 내에서 어떤 정보와 관련 있는 다른 정보 간의 거리가 멀 때 해당 정보를 이용하지 못하는 것을 일컫는다.)
이에 따라 디코더의 매 시점(step)마다 인코더의 입력 시퀀스를 재사용하자는 아이디어가 제안된 것이다. 이 때 시퀀스의 각 term을 모두 동일한 weight로 참고하는 것이 아니라 예측하고자 하는 단어와 관련이 있는 term에 좀 더 weight를 가중하게 된다. 예를 들어 I를 뜻하는 je를 예측하는 단계에서는 input sequence의 I와 예측할 값인 je가 연관이 깊기 때문에 I에 대한 weight가 다른 단어에 비해 더 높은 값을 지니는 것이다. 이러한 특성 때문에 Attention이라고 명명하게 되었다.
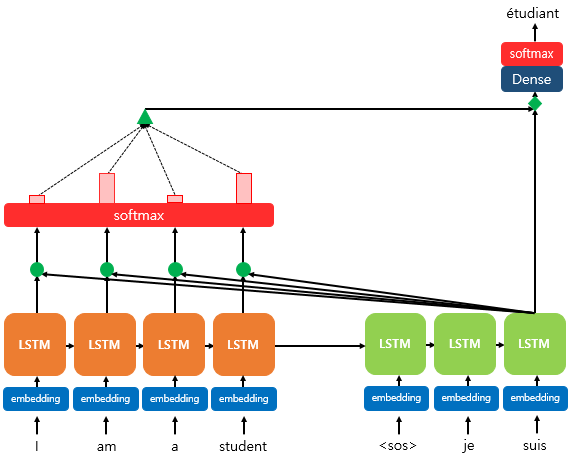
위 이미지에서도 보면 decoder의 이전 hidden state와 입력 벡터의 각 term을 함께 고려하여 softmax를 취해 0과 1사이의 확률값(probability)으로 weight를 계산하여 디코더의 예측에 사용한다.
이 메커니즘의 구현은 최근 대량 메모리와 병렬 처리를 지원하는 GPU의 사용이 확대되면서 가능하게 되었다.
이처럼 Seq2Seq모델의 단점을 Attention 아키텍쳐를 추가함으로써 개선할 수 있지만 Transformer 아키텍쳐는 더 나아가 RNN, CNN 등을 전혀 사용하지 않고 Attention만을 이용하여 인코더, 디코더를 구성한 뒤 기계번역을 우수하게 할 수 있다고 말한다.
다음 글에서는 Transformer 아키텍쳐에 대해 다뤄볼 것이다.
'Tech > ML, DL' 카테고리의 다른 글
| BERT - (3) BERT의 기본 (0) | 2022.12.20 |
|---|---|
| BERT - (2) Transformer 이해하기, 코드 구현 (2) | 2022.12.13 |
| 불균형(imbalanced) 데이터 모델링은 ROC curve를 사용을 추천하지 않는 이유 (0) | 2022.06.24 |
| 이상탐지, Anomaly Detection (0) | 2022.06.12 |
| Catboost 모델에 대하여 - 알고리즘, 구현 코드 (2) | 2022.06.03 |



