
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 미국석사
- MSCS
- 미국 개발자 취업
- BERT
- nlp
- 플랫폼
- chatGPT
- 언어모델
- BERT이해
- RecSys
- 추천시스템
- 머신러닝
- TFX
- 중국플랫폼
- BANDiT
- HTTP
- llm
- 자연어처리
- 클라우드자격증
- 합격후기
- 클라우드
- docker
- maang
- 네트워크
- swe취업
- MLOps
- MAB
- 메타버스
- AWS
- transformer
- Today
- Total
SWE Julie's life
BERT4Rec - 추천시스템과 BERT 본문
추천시스템과 자연어처리 모델은 함께 떠올리기 쉽지 않다. 우리가 통상 생각하는 추천시스템은 아이템과 유저를 대상으로 하는데, 자연어처리 모델은 언어를 대상으로 하기 때문이다.
하지만 몇몇 사람들은 자연어처리 모델을 추천시스템에 적용해보기를 시도했다. 그 이유는 유저가 순차적인 이벤트(혹은 activity)를 발생시키는 경우 순차성을 지닌 텍스트 데이터와 유사한 속성을 지닌 데이터로 여길 수 있기 때문이다. 그 외에도 유저의 반응(implicit 혹은 explicit feedback)이 희소(sparse)하다는 것과 one-hot encoding으로 데이터를 임베딩한다는 것이 유사점으로 꼽을 수 있다.
딥러닝 언어 모델이 점차적으로 발전해나가면서 순차적인(Sequential) 추천 모델도 함께 발전해왔다. Vanilla RNN의 인기와 그의 본질적인 문제인 장기 의존성 문제(Long-term dependency problem)를 해결하고자 등장한 LSTM, 그 후 GRU, Seq2Seq, Attention, Transformer까지 발전해올때 순차적 추천 모델도 한 발짝씩 따라서 발전해오고 있었다. 그 예로 GRU4Rec, SASRec, SSE-PT, BERT4Rec, Transformer4Rec이 있다.
각각에 대해 간단하게 특징을 정리하자면 아래와 같다.
- GRU4Rec : GRU를 이용하여 과거 행동을 기억하고 다음번 행동을 예측
- SASRec : 단방향 Self-attention 모듈 사용
- SSE-PT : SASRec과 유사하지만 개인화된 추천을 위해 사용자 벡터를 임베딩하여 추가함
- BERT4Rec : BERT로 RecSys를 빌딩
- Transformer4Rec : BERT4Rec의 등장 이후에 일반적인 Transformer 계열 모델들을 모두 추천 시스템에 적용할 수 있지 않을까 하여 제안된 논문
오늘은 그 중 BERT4Rec 논문에 대해서 간단히 살펴볼 것이다. Alibaba Group에서 2019년 발표한 논문이다.
논문을 이해하려면 BERT, Transformer의 개념에 대한 이해가 필요한데, 다른 글에서 이미 정리해두었기 때문에 이번 글은 추천시스템에 어떻게 BERT가 활용될 수 있는지에 좀 더 초점을 맞춰져있다.
논문의 제목이 전체 내용을 잘 요약하고 있어 인용해왔다:
Sequential Recommendation with Bi-directional Encoder Representations from Transformers
Bidirectionality
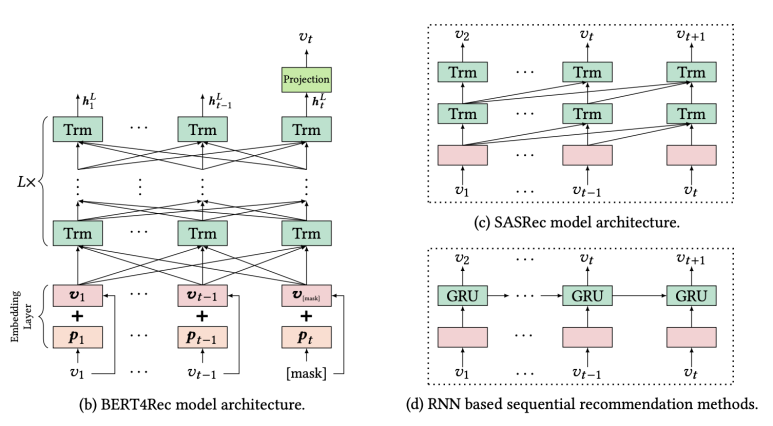
논문에서 제공한 다른 순차적 추천시스템 아키텍쳐와 BERT4Rec이 다른 점은 BERT가 다른 여타 자연어처리 모델과 다른 점인 '양방향성(Bi-directionality)'이다. 과거에는 왼쪽에서 오른쪽 순서로 인풋을 인코딩하여 재표현(representation)했고 이는 최선책이 아니라고 주장한다.

그 이유는 두 가지인데, 첫 번째로는 단방향성인 아키텍쳐가 재표현력을 떨어뜨린다고 말한다. 쉽게 말해 직전 아이템에 대한 정보로만 인코딩하기 때문에 양방향에 비해 표현력이 떨어진다는 것이다. 두 번째 이유는 순차적인 모델들은 엄격한 순서를 가정하고 있다는 점에서 비현실적이기 때문이라고 말한다. 우리가 쉽게 유저의 선호를 떠올려봐도 관측불가한 다양한 외부 요인들이 존재할텐데 순차적인 아키텍쳐는 이러한 틈없이 순차적으로 정보를 학습하기 때문에 양방향 아키텍쳐에 비해 뒤처진다고 말한다.
따라서 양방향 메커니즘으로 양쪽에서의 context를 학습하여 유저의 시퀀스 데이터를 이해하겠다는 것이 BERT4Rec의 요점이다.
MLM(Masked Language Model) / Cloze Objective
BERT와 동일하게 양방향성으로 인해 발생되는 정보의 유출(즉 미래의 데이터를 볼 수 있다는 것)을 막기 위해 Cloze objective가 적용되었다. 이 기술 역시 BERT 원 논문에도 잘 설명되어있으니 간단히 언급하고 넘어가겠다.

BERT4Rec Architecture
BERT4Rec의 아키텍쳐는 BERT와 동일하다. 인풋 시퀀스가 One-hot encoding된 아이템 행렬이라는 점만 다르다. 그 외 Attention Layer, Transformer Layer, Normalization, Dropout 등 구성과 Multi-head self-attention의 연산 방식 역시 동일하다.
정리하자면 SASRec과 BERT4Rec의 차이는 전자는 sequence에서 각 position의 다음 item을 예측하지만 BERT4Rec은 Cloze Objective를 이용하여 마스킹된 item을 예측한다는 점이 다르다.
BERT와의 차이는 pre-training 여부이다. BERT는 미리 학습된 언어 모델로 도메인간의 배경지식(background knowledge)이 동일하다고 암묵적으로 가정하고 있다. 그래서 분석가들은 BERT를 각자만의 자연어처리 업무(down-stream task)에 활용시 간단한 fine-tuning만 진행하면 쉽게 예측모델을 만든다는 장점이 있다. 하지만 추천에서의 도메인은 task마다 전부 배경이나 상황이 상이하기 때문에 BERT4Rec은 pre-training된 것이 아닌 end-to-end 모델이다.
뿐만 아니라 BERT에서의 NSP(Next Sentence Prediction) objective가 생략되어있다. 이는 추천시스템에서의 유저의 행동 이력은 하나의 시퀀스로 여겨지기 때문이다. 특성상 불필요한 부분이라고 판단되어 생략한 것 같다. 그리고 BERT의 input representation 은 세 가지의 embedding layers인 1) token, 2) position, 3) segment로 구성되는 반면 BERT4Rec은 segment embedding을 적용하지 않은 token, position embedding으로만 구성되어 있다. 이것 역시 추천시스템 특성상 유저의 행동 데이터는 하나의 sequence로 인정하기 위함이다.
Performance
논문은 BERT4Rec의 성능이 우수하다는 점을 여러 데이터셋을 통해 다른 모델들과 비교하였다. 이 때 개선정도는 유의확률이 0.01보다 아래일 정도로 통계적으로 의미있는 수준이라고 한다. 추천시스템 도메인이다보니 성능 Metric으로 Hit Rate 혹은 NDCG가 활용되었다.

이 모델이 왜 좋은 성능을 보일까? 다른 모델과 다른 점은 Cloze objecive와 양방향성 두 가지이다. 그럼 Gain은 bidirectional self-attention으로부터 기인했을까? 아니면 Cloze objective로부터 기인했을까?

이를 확인하기 위해 논문에서는 Cloze objective 수행 시 각 time step에서 단 하나의 item만을 mask하도록 변경하였고 이 성능과 SASRec과의 차이를 보았다. 하나의 아이템만을 마스킹하게 될 경우 SASRec 모델과의 차이는 양방향성만 있기 때문이다. 그리고 그 결과로 bidirectionality로 인해 SASRec보다 BERT4Rec이 더 성능이 좋다는 것을 알게 되었다.
그리고 attention weight를 시각화함으로서 Attention Head들의 행동 패턴을 히트맵으로 보여주었다.


위 그림에서 (a)와 (b)는 모두 layer 1의 head들이다. (a)는 각 item들이 왼편에 있는 아이템들에 좀 더 attend하고, (b)는 오른편에 attend한다는 것을 볼 수 있다. (= 각각 대각선 기준 좌하단, 대각선기준 우상단일수록 색이 진하다).
그리고 (c)와 (d)는 layer 2에 있는 head들인데 둘 다 layer 1에 비해 attention weight가 좀 더 최근 item에 집중된 것을 볼 수 있다. 이는 layer 2가 output layer로 바로 연결되기 때문에 최근 item의 정보가 예측에 좀 더 중요한 역할을 한다고 학습했다고 이해할 수 있다.
위 그림에서 얻을 수 있는 가장 큰 인사이트는 양방향에서의 Attention이 가능하다는 것이다. BERT의 아키텍쳐는 양방향 Self-attention이 가능하고, 이 양방향성 덕에 단방향 모델보다 좋은 성능을 보일 수 있다.
Parameter Optimization
논문의 마지막에는 파라미터 값 조정에 대한 가이드라인을 간단히 제공하고 있다. latent space차원인 d와 masking 비율값인 p, 시퀀스의 max length N 세 값을 조정하면서 성능이 얼마나 달라지는지를 시각화하여 보여주고 있다. 그 자료는 생략하고 각 값의 변화에 따른 모델의 차이만 간단하게 요약하자면 아래와 같다:
- d : 값을 증가할수록 performance가 converge하는 경향이 있다. 데이터가 희소하다면(sparse) hidden dimensionality가 높다고 해서 성능을 개선될거란 보장이 없다.
- p : 너무 작거나 너무 큰 값만 아니면 된다. 0.3 정도를 추천한다.
- N : 과거의 정보를 몇 개까지 볼 것이냐를 정하는 값이다.
GitHub
마지막으로 논문의 GitHub repo를 첨부하며 글을 마무리하겠다. 논문에서 사용된 테스트 데이터셋별 shell코드와 모델의 python 코드가 있다. 참고로 모델은 Tensorflow로 구현되어있다.
'Tech > RecSys' 카테고리의 다른 글
| Multi-stage RecSys와 재순위화(re-ranking) (0) | 2023.01.19 |
|---|---|
| Transformers4Rec - 추천시스템과 Transformer (0) | 2023.01.05 |
| 추천시스템 - (4) 이커머스 추천 문제 (0) | 2022.01.02 |
| 추천시스템 - (2) One-class Collaborative Filtering (1) | 2021.09.20 |
| 추천시스템 - (1) 개요 (0) | 2021.09.13 |


