
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- chatGPT
- 클라우드
- HTTP
- 머신러닝
- MLOps
- maang
- 플랫폼
- RecSys
- llm
- swe취업
- 메타버스
- BERT이해
- 자연어처리
- MAB
- nlp
- 합격후기
- docker
- 클라우드자격증
- MSCS
- 미국석사
- 언어모델
- 미국 개발자 취업
- BERT
- transformer
- 추천시스템
- 네트워크
- AWS
- TFX
- BANDiT
- 중국플랫폼
- Today
- Total
SWE Julie's life
Transformers4Rec - 추천시스템과 Transformer 본문
이번 글은 BERT4Rec에 이어서 NLP 모델인 Transformer가 추천시스템에 어떻게 적용될 수 있는지 연구한 논문에 대해 다뤄볼 것이다. 이번 논문은 저번 BERT4Rec이 순차적인(Sequential) 추천시스템에 적용된 것에서 더 나아가 Session-based, 즉 좀 더 짧은 인풋인 세션 단위에서의 추천시스템에 초점을 두고 있다. 요즈음의 이커머스, 뉴스, 혹은 미디어 포털에서의 유저 상호작용은 굉장히 짧은 형태이다. 이 배경에는 쿠키 수집 제한 정책과 같은 법적인 이슈도 있지만 큰 이유로는 유저의 선호가 다이나믹하게 바뀌기 때문이다.
본 논문은 NVIDIA에서 발표하였으며, BERT4Rec과 다르게 방법론을 다룬 논문이 아니라 직접 모델을 학습하여 배포한 오픈소스 라이브러리를 소개하고 있다. NVIDIA에서 발표한 논문 답게 전처리 과정이나 학습 과정에 NVIDIA 라이브러리인 NVTabular을 사용하여 자사의 상품을 광고하고 있다.
사실 모델의 성능이 BERT4Rec 만큼 우수하다고 볼 수 없으나, 세션 위주의 추천시스템에 적합한 새로운 방법을 발굴했다는 점과 추가로 side information (아이템이나 유저의 context feature)을 추가하는 방법론에 대해 연구해봤다는 점에서 본 논문은 가치가 있다.
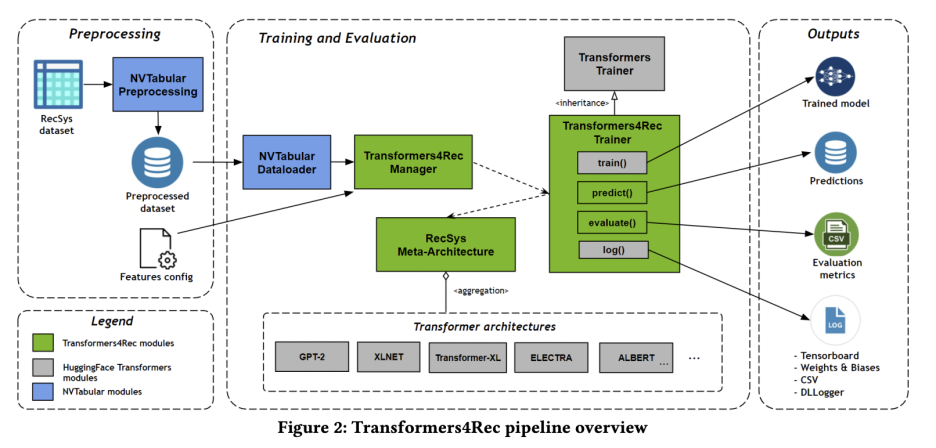
Architecture
모델의 인풋은 웹 세션에서 브라우징된 아이템들이나 장바구니에 담긴 아이템들과 같이 일련의 유저 상호작용(interaction) 시퀀스가 해당된다. Transformer4Rec은 이러한 인풋 데이터를 처리하고 모델링하여 다음 아이템에 대한 더 나은 추천을 예측할 수 있다고 주장하고 있다. 이름에서도 유추 가능하지만 Transformer 모델을 사용하는데, 이 모델은 Hugging Face에 있는 Transformer library이다. HF 라이브러리는 1) Tokenizer, 2) Transformer block, 3) NLP task들의 head로 구성되어있지만 Transformer4Rec은 2)번 Transformer block만을 차용하였다. (= train()과 log() 모듈을 그대로 사용하였다고 한다.)
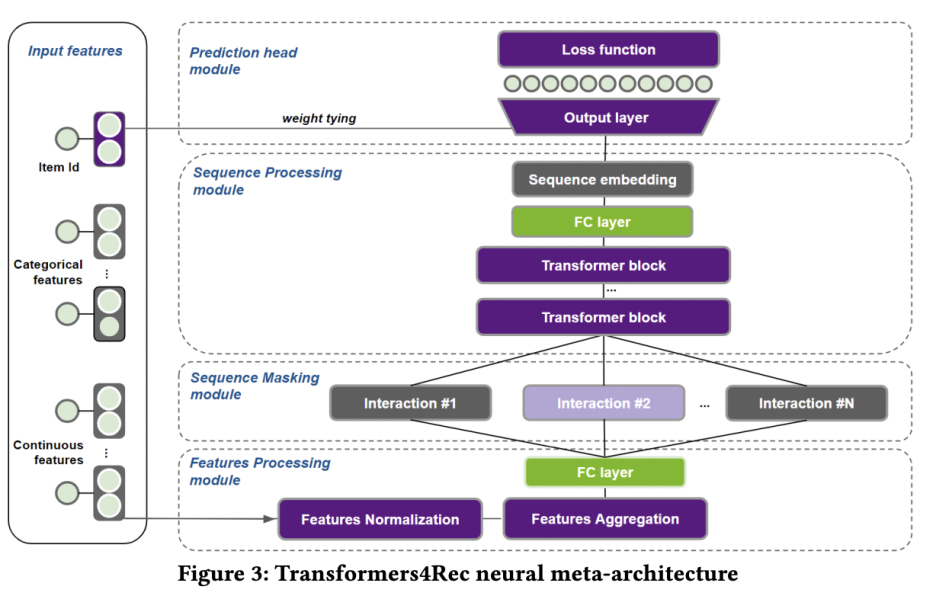
모델의 구조를 단계별로 살펴보자면,
- Input Feature Representation
- 아이템 id와 아이템의 metadata, 유저 context를 재표현(represent)하는 레이어이다.
- 범주형 변수의 embedding, 연속형 변수의 embedding을 나눈다. 연속형 변수는 soft one-hot encoding 방식을 취한다.
- Feature Processing Module
- 아이템 id와 범주형+연속형 feature들을 합치는데, 이 때 element-wise하게 merge하는 방식을 취한다.
- merge하는 방식을 취하는 이유는 논문에 따로 reference 근거가 있다.
- Sequence Masking Module
- Interaction 1~N 에 대해 masking module을 진행하게 된다.
- 세 가지 옵션에 따라 각각 모듈 수행방식이 달라진다.
- Causal Model(Autoregressive)이면 순차적으로 예측
- MLM(Auto-encoding)이면 확률적으로 몇 개를 masking하여 예측 (ex. BERT)
- Permutation LM이면 순서를 섞어 예측 (ex. XLNet)
- Sequence Processing module
- Transformer 블록을 거쳐 Sequence Embedding 결과를 뱉는다.
- Prediction Module
- Loss function에 따라 예측결과와 실제값의 차이를 구한 뒤 모델을 업데이트한다.
전반적으로 모델의 구성은 특이한 부분이 따로 없다. 추가로 자잘한 메커니즘들이 사용되었는데, 예를 들어 tying embedding이라고 하여 parameter sharing 방법 중의 하나로, 인풋 임베딩 레이어와 아웃풋 softmax 레이어의 weight를 공유하는 것이다. 이는 모델 파라미터 수를 줄이고, 정규화하는 것이 목적이다. 또 Loss function을 여러 가지 제공하는데, BPR(Bayesian Personalized Ranking)이라고 하여 올바른 예측값과 올바르지 않은 예측값의 ranking 차이를 loss function에서 활용하여 순서도 맞출 수 있도록 디자인한 것과, 논문의 필자들이 직접 디자인한 연관된 아이템들간의 상대적인 rank 차이를 근사하는 TOP1이라는 loss function도 있다.
세션화 과정
테스트 데이터셋을 전처리하는 과정도 짧게 설명되어있는데, 세션화를 어떻게 진행했는지에 대한 아이디어를 구할 수 있다. E-commerce 분야의 데이터셋은 하루 단위로 나누어 세션화하였고, 뉴스는 1시간 단위로 interaction의 길이를 제한하여 세션화 하였다. 즉 T 타임기간의 session동안의 상호작용을 기반으로 다음 T 타임의 세션에 대한 아이템을 예측하는 것이다. 모델의 성능에 대해 간단히 먼저 언급하자면 REES46 eCommerce, YOOCHOOSE eCommerce라는 두 이커머스 데이터셋에서는 좋은 지표를 보이고, 뉴스 데이터셋에서는 baseline 모델과 큰 차이 없는 성능을 보인다.
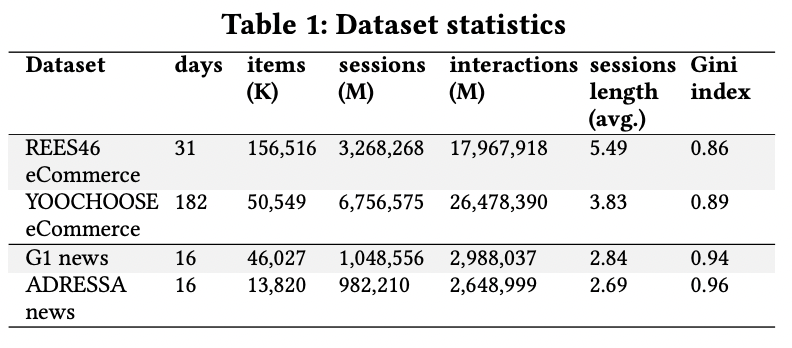
세션 길이는 위 표에서도 볼 수 있듯이 평균 길이가 2~6이라서 굉장히 짧은 세션의 예측에 집중하고 있다는 것을 다시 확인할 수 있다. 논문 전반적으로 세션 길이가 길지 않은 데이터에 대해 추천 성능이 좋다는 것을 강조한다는 점에서 Transformers4Rec은 짧은 시퀀스의 인풋 데이터에 좋은 성능을 보이는 모델이라고 할 수 있다. 일반적으로 NLP 문장의 시퀀스 길이는 이러한 세션 길이보다 길기 때문에 이 논문은 NLP 모델을 RecSys에 맞추고자 노력했다는 걸 알 수 있다.
Performance
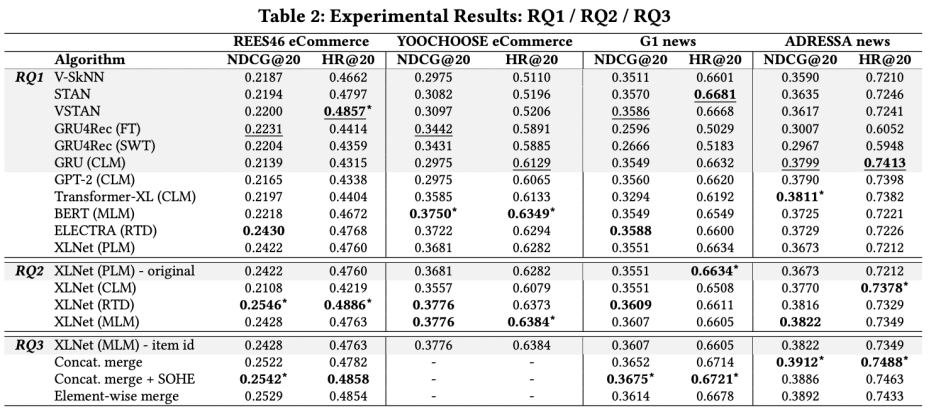
실제로 첫 번째 Research Question(RQ)이 "Transformer-based architecture가 짧은 유저 sequence를 특징으로 하는 session-based recommendation task에 좋은 성능을 보일까?"이다. 그에 대한 답은 몇 가지 데이터셋에서는 Transformer 기반 아키텍쳐가 좋은 성능을 보이나 전반적으로 하나의 우월한 모델은 보기가 어렵다는 것이다. 그럼에도 불구하고 논문이 제안하는 모델이 전반적으로 평타 이상은 성능을 보인다는 애매한 결론을 내릴 수 있다. 물론 메트릭이 @20 까지만 고려했다는 점도 생각해야한다.
두 번째 질의는 "Causal LM, Masked LM, Permutation LM, Replacement Token Detection 중에서 어떤 것이 session-based 추천에 좋을까?"이다. 앞서 살펴보았던 Sequence Masking Module에서 현재 NLP 모델의 여러 masking 방법론들을 옵션으로 제공하는데, 그들간의 성능 비교를 해본 것이다. 결론은 Replacement Token Detection 방식이 가장 좋다는 건데, 첫 번째 질문과 마찬가지로 애매한 결론이었다.
마지막 질문은 "Feature Processing Module에서 여러 feature를 통합할 때 어떤 방식이 가장 좋은가?"이다. 아이템 id만, 혹은 concatenate merge, 또는 element-wise하게 merge, 마지막으로는 concatenate merge와 soft one-hot encoding을 진행한 결과를 비교해봤을 때 가장 마지막 방법이 우수한 성능을 보인다고 결론내렸다.
Strength
Transformers4Rec은 모듈화된 block들을 제공한다. 라이브러리 사용 시에 각 블록마다 사용자가 직접 튜닝할 수 있고 PyTorch 모듈과 호환이 되기 때문에 각자의 니즈에 따라 유연성 높게 모델을 optimize할 수 있다는 장점이 있다. 그리고 Hugging Face 라이브러리를 사용하기 때문에 64개 이상의 다양한 Transformer 아키텍쳐를 선택해서 모델을 만들 수 있다. 그래서 현업의 데이터 특성에 적합한 아키텍쳐를 쉽게 탐색해볼 수 있다. 그리고 input sequence가 여러 유형이어도 된다는 장점도 있는데, NLP로 디자인된 Hugging Face 모델은 token ID만을 받지만 Transformers4Rec은 추천시스템의 다양한 데이터셋에 맞추어 sequential하면서 tabular한 데이터셋도 input으로 받아들일 수 있다. Transformers4Rec이 알아서 스키마를 읽어 input feature의 타입에 따라 필요한 embedding layer나 projection layer을 생성하기 때문이다.
Sample Code
일반적으로 모델 설계는 아래와 같은 단계로 진행하면 된다고 한다:
- 스키마를 제공하여 input 모듈을 구성한다. 이 때 Transformers4Rec의 전처리는 NVTabular 라이브러리를 사용하고 있기 때문에 그 라이브러리의 Schema class 형태를 따른다.
- Prediction Task를 정의한다. Regression, Classification, Next Item Prediction 등이 있다.
- Transformer Body를 정의하고 Transformers4Rec 모델에 반영한다.
from transformers4rec import torch as tr
# Create a schema or read one from disk: tr.Schema().from_json(SCHEMA_PATH).
schema: tr.Schema = tr.data.tabular_sequence_testing_data.schema
max_sequence_length, d_model = 20, 64
# Define the input module to process the tabular input-features.
input_module = tr.TabularSequenceFeatures.from_schema(
schema,
max_sequence_length=max_sequence_length,
continuous_projection=d_model,
aggregation="concat",
masking="causal",
)
# Define one or more prediction-tasks.
prediction_tasks = tr.NextItemPredictionTask()
# Define a transformer-config like the XLNet architecture.
transformer_config = tr.XLNetConfig.build(
d_model=d_model, n_head=4, n_layer=2, total_seq_length=max_sequence_length
)
model: tr.Model = transformer_config.to_torch_model(input_module, prediction_tasks)
마지막으로 본 글은 가장 중요한 학습 모듈인 trainer.py 파일의 경로를 언급하고서 마무리하겠다.
https://github.com/NVIDIA-Merlin/Transformers4Rec/blob/main/transformers4rec/torch/trainer.py
추가로 참고할만한 자료
'Tech > RecSys' 카테고리의 다른 글
| Multi-stage RecSys와 재순위화(re-ranking) (0) | 2023.01.19 |
|---|---|
| BERT4Rec - 추천시스템과 BERT (0) | 2023.01.03 |
| 추천시스템 - (4) 이커머스 추천 문제 (0) | 2022.01.02 |
| 추천시스템 - (2) One-class Collaborative Filtering (1) | 2021.09.20 |
| 추천시스템 - (1) 개요 (0) | 2021.09.13 |


