
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 추천시스템
- 언어모델
- maang
- llm
- TFX
- 네트워크
- 합격후기
- 메타버스
- MAB
- AWS
- 중국플랫폼
- 머신러닝
- MLOps
- BERT
- 클라우드자격증
- 클라우드
- 플랫폼
- swe취업
- BERT이해
- 미국 개발자 취업
- MSCS
- chatGPT
- docker
- HTTP
- 자연어처리
- 미국석사
- RecSys
- BANDiT
- nlp
- transformer
- Today
- Total
SWE Julie's life
Multi-stage RecSys와 재순위화(re-ranking) 본문
이번 글은 추천시스템의 아키텍쳐로 떠오르는 multi-stage recommendation system 구조에 대해 간단히 살펴본 후, 가장 마지막 stage로 분류되는 're-ranking(재순위화)'에 대해 개괄적으로 다뤄볼 것이다. 본 글은 2022 RecSys의 tutorial에 소개된 survey 논문 중 하나인 neural re-ranking for multi-stage recommender systems를 참조하였다.
추천시스템에서의 아이템과 유저는 굉장히 방대하면서 동시에 sparse하다. 그리고 데이터를 수집하여 사용 가능한 형태로 만들고, 다시 모델로 추론하여 FE에 제공하기까지 상당히 여러 단계를 거쳐야한다. 최근 추천시스템 분야에서는 이를 각 단계로 분리한 multi-stage recommendation system을 추구한다. 그 이유로는 여러 가지가 있는데, 우선 각 단계에서는 maximize/minimize하고자 하는 목표(objective)가 다르기 때문에 각기 목표하는대로 최적화를 할 수 있다. 예를 들자면, 일반적으로 검색엔진에서의 ranking system은 3가지로 나눌 수 있는 것이다:
1) 검색 결과 생성 (recall을 극대화)
2) 연관도 평가에 따른 검색 결과 ordering (relevance를 극대화)
3) 유저의 클릭 결과에 따라 평가 (utility를 극대화)
이렇게 구성할 경우 세 단계에서의 목표함수에 따라 알고리즘이 모두 다르게 설계될 수 있을 뿐더러, 각 단계에서 유지해야하는 latency 수준도 다르게 설정할 수 있다. 일반적으로 1번인 검색 결과를 생성하는 단계에서는 다른 단계에 비해 굉장히 낮은 수준의 latency를 유지해야한다. (유저의 사용성을 위해)
일반적으로 추천시스템의 multi-stage recommendation system은 아래와 같은 구성도를 가지고 있다. 아이템 풀이 생성되면 유저가 선호할 것 같은 candidate 아이템 풀을 다시 생성하고, 이들 간의 순서를 모델로 추론하여 스코어를 매긴 뒤, 유저의 최근 정보(이미 본 영화 제거 혹은 선호가 바뀌었다면 반영)를 반영하여 최종적으로 아웃풋을 생성하는 것이다.
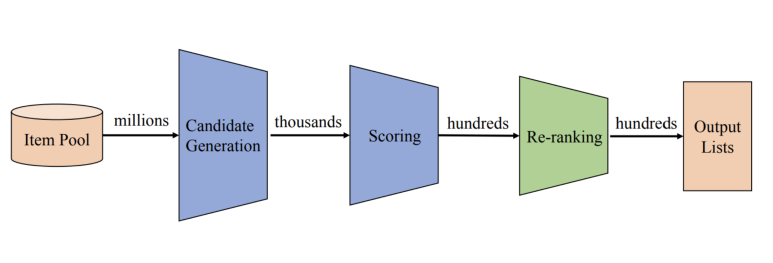
좀 더 세부적으로 구성도를 나눠본다면 아래와 같다.
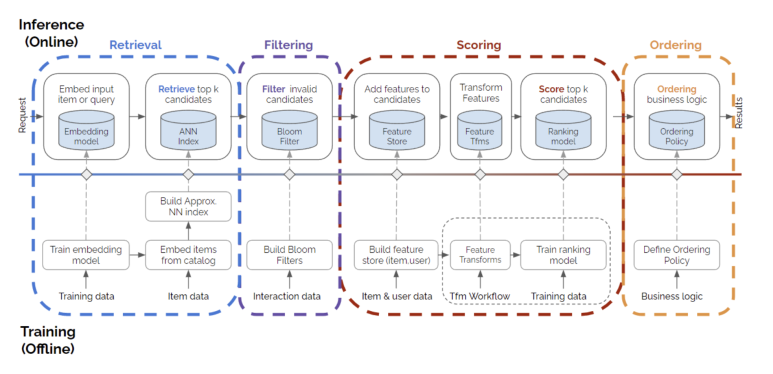
첫 번째 이미지를 다르게 표현하면 아래 구성도인데, 이 구성도에 따른 대표적인 모델들을 간단히 소개하려고 한다.
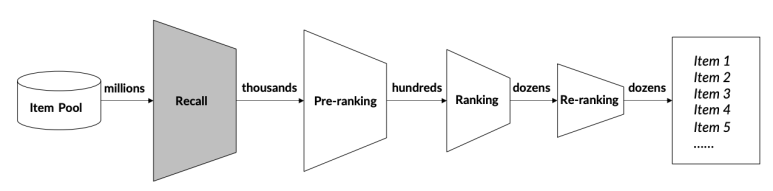
첫 번째 단계는 recall stage이다. 아이템 풀에서 최대한 회수율을 높여 candidate 아이템 풀을 빠르게 생성하는 단계이다. 이는 rule-base로 구성할 수도 있고 모델로 구성할 수도 있다. 이 때 이 단계에서는 여러 종류의 objective를 둘 수 있는데, 연관도(relevance) 혹은 다양성(diversity)가 그 예다.
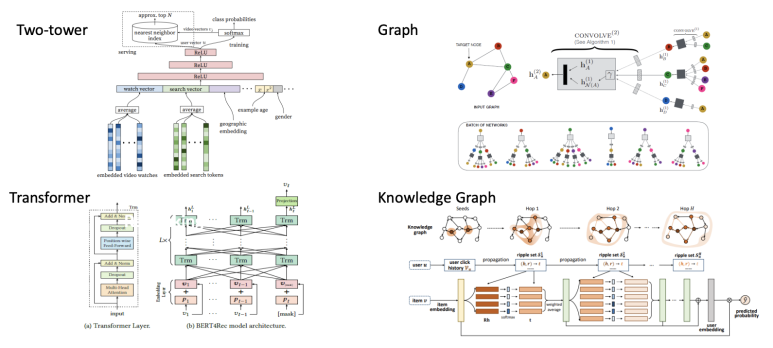
모델로 설계할 경우 위와 같이 4가지 모델들이 대표적으로 사용된다. 이 중에서 BERT4Rec(Transformer기반)은 이 글에서 정리된 바가 있으며, Knowledge Graph는 RippleNet이 소개되었는데 유저의 클릭 히스토리를 기반으로 아이템들에 대해 지식그래프를 형성하게 된다. 이 때 edge로는 아이템의 메타 정보들이 사용되는데, 영화라고 치면 감독, 배우, 장르, 언어, 개봉년도 등이 연관 노드를 형성하게 된다.
이들 모두 특정 유저가 관심이 있을 법한 아이템 풀(candidate items)을 생성하는 모델이라 볼 수 있다.
두 번 째 단계는 pre-ranking stage로 본격적인 랭킹단계에 앞서 관련이 적은 아이템들을 제거하는 목적으로 운영된다. Ranking stage에 비해 적은 feature과 좀 더 간단한 모델로 구성이 가능한데, ranking stage의 효율성(복잡도를 낮춰 속도 개선을 한다는 등)을 위해 이 단계를 포함할 것이냐 여부는 선택적인 것 같아 보인다.
이 단계에서의 대표적인 모델들은 아래와 같이 꼽혔다. 일반적으로 추천 시스템 외에 온라인 광고 시스템에서도 사용되는 모델들도 있었다. 여기서 유저는 아마 광고 구좌일 것이고, 아이템은 광고 캠페인일 것이다.
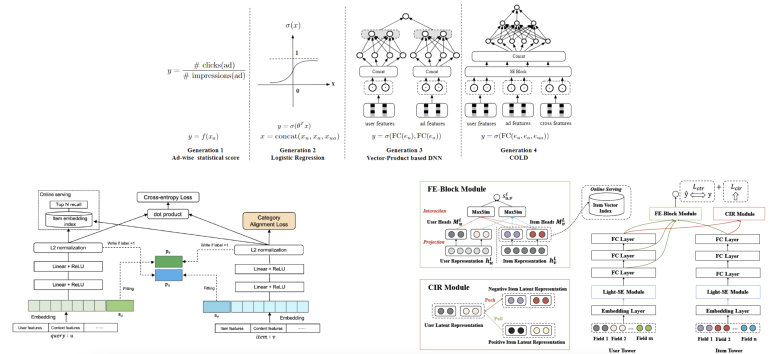
그 다음은 ranking stage로 앞서 살펴본 pre-ranking보다 많은 변수들을 포함하는 좀 더 복잡한 모델로 구성된다. 이 때 주로 사용되는 모델들은 유저의 행동을 모델링한 것들인데, candidate 아이템들에 대해 유저의 선호를 추론하는데 사용되어 좀 더 정확한 ranking을 산출하게끔 한다.
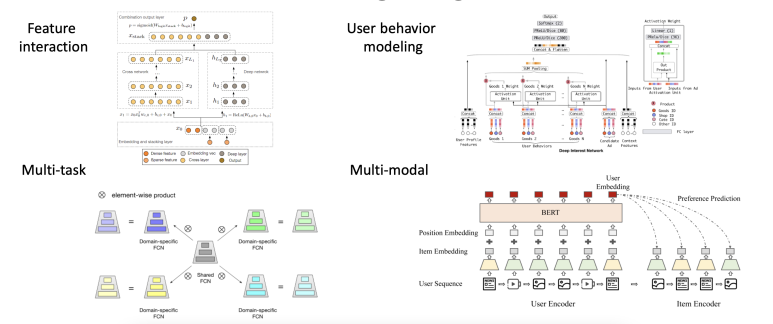
두 번째 아키텍쳐인 user behavior modeling에서는 온라인 광고 추천 도메인을 다루고 있는데, 모델에 시간 관련 context와 유저의 profile (성별과 나이 등 유저의 정보), 아이템 profile (광고에 대한 메타 정보)를 함께 input으로 제공한다. 이러한 여러 종류의 정보를 embedding하여 모델에게 학습시키면 좀 더 유저의 선호에 맞는 아이템을 추천해줄 수 있을거란 아이디어이다. 추가로 유저의 선호가 지속적으로 변화한다는 사실도 반영하기 위해서 attention layer를 사용하여 전체의 유저 클릭 히스토리 중 가장 최근에 선택한 아이템과 가장 연관이 있는 아이템을 학습하기도 한다.
이제 마지막인 re-ranking stage인데, 앞단계인 ranking stage에서 유저의 선호에 좀 더 맞춰진 item들에 대해서 다시 순위를 매기고 필터링을 진행하게 된다. 사실 Ranking시스템이 유저의 선호를 실시간으로 반영할 수 있는 정도라면 re-ranking은 필요하지 않을 수 있지만 지속적으로 운영하고 있는 서비스라서 유저의 feedback이 실시간으로 인입(선호하지 않는다는 feedback을 주거나 잠깐 조회하더라도 이탈한 아이템이 있다는 등)되고 있는 구조라면 re-ranking 단계가 필요할 수 있다.
우리는 이 re-ranking 단계에 대해 좀 더 개괄적으로 살펴볼 것인데, 가장 기본적으로 objective function은 아래와 같이 추상화할 수 있다.
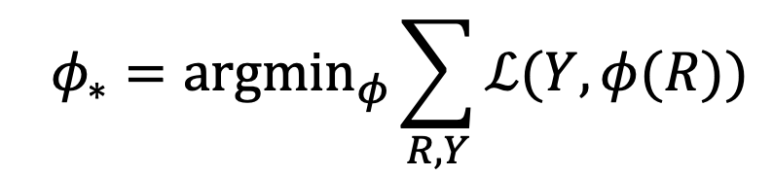
R은 n개의 아이템 리스트로 시스템이 유저에게 리턴한 추천 목록이다. Y는 유저의 feedback을 반영하여 아이템에 대해 옳고 그름을 매긴 값이며, 이 둘간의 차이를 Loss function으로 계산하여 최소화하는 ranking function을 구하게 된다. 파이는 ranking function을 의미한다.
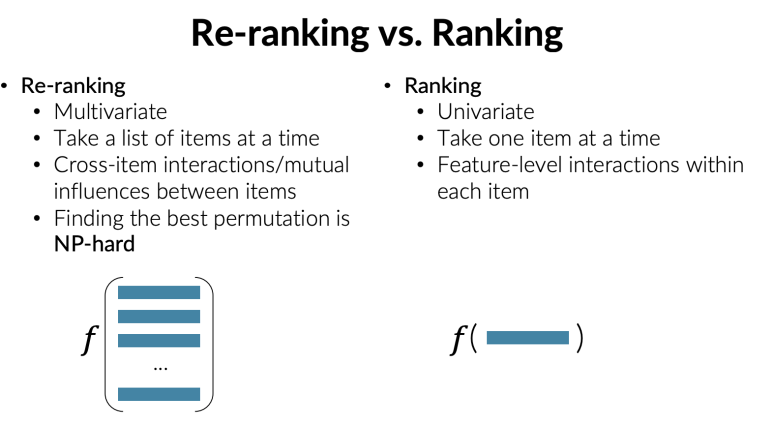
Re-ranking과 ranking의 차이는 위와 같다고 한다. 결론적으로 Ranking은 하나의 아이템에 대해 rank를 산출하는 것이라면, re-ranking은 최종 선택된 아이템들 간의 재정렬을 하는 것이라 아이템 리스트에 대해 rank를 산출한다. 10개의 아이템이 있다고 치면 총 10!만큼의 가지수가 가능하기 때문에 연산 복잡도가 높다.
Re-ranking의 알조리즘을 다룬 논문들은 아래와 같이 사분면으로 표현하여 카테고리화를 할 수 있다고 한다. Re-ranking도 다른 도메인에서의 딥러닝 추세와 마찬가지로 최신 논문일수록 Recurrent → RNN & Self-attention → Self-attention 중심으로 옮겨가고 있다.
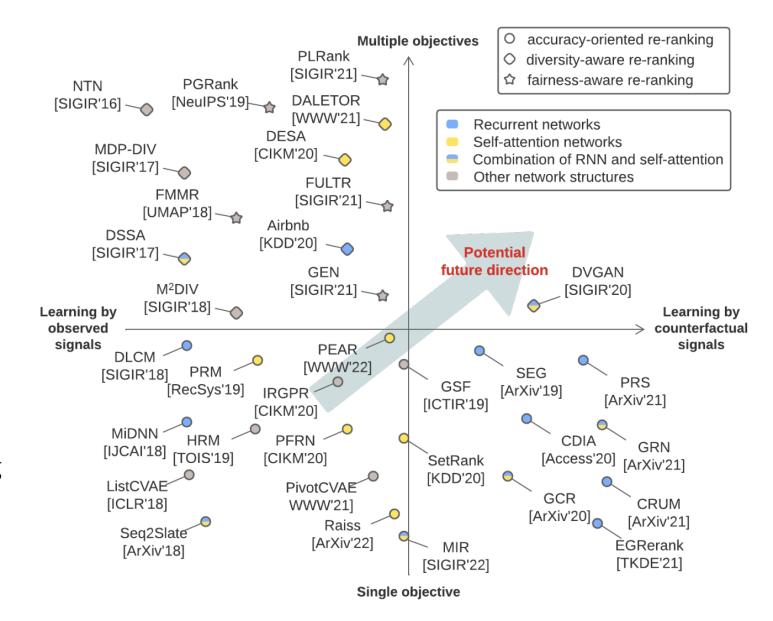
Re-ranking시에는 ranking과 다르게 여러 가지의 objective를 동시에 놓고 고려하는데, 대표적으로 정확도(accuracy), 다양성(diversity), 공평성(fairness)를 사용한다. 일반적으로 기업엥서는 정확도를 기반으로 re-ranking 알고리즘을 설계하지만 학계에서는 다양성과 공평성을 중심으로 연구가 이루어진다고 한다. 다양성과 공평성이 잘 구분이 안갈 수 있는데, 공평성이란 아이템이 일정한 수준의 노출량을 보장받는 것을 말한다. 다양성은 re-ranking된 리스트가 얼마나 다른지 혹은 얼마나 주제를 커버하는지(topic coverage)를 따지게 된다.
동시에 추천 목록이 옳고 그른가에 대한 정의를 내리는 기준은 크게 두 가지로 구분할 수 있다: 관측된 결과(observed signals)와 반사실적 결과(counterfactual signals)이다. 관측된 결과는 우리가 일반적으로 정의하는 정답지 방식과 동일한데, 반사실적 결과는 조금 다르다. 사실과 반대였다면 어떤 결과를 도래했을지를 고민하는 것이다. 노출결과를 실제 노출된 것과 다른 순서로 배치했을때 어떤 결과를 도출했을지를 예상하는 것도 그 예이다. 후자는 사실과 반대의 경우를 생각해야하기 때문에 일반적인 observed signal로 학습하는 것과는 달리 생성기(Generator)가 필요하다. 이 생성기에서는 counterfactual signal을 생성하는 것이다. 아래 그림이 이 내용을 도식화하고 있다. Observed signal로만 학습하는 것은 display된 추천 리스트로만 한정된다는 단점이 있다. 즉 n!-1만큼의 가짓수(permutation 결과)가 학습할 때 고려되지 않는 것이다.
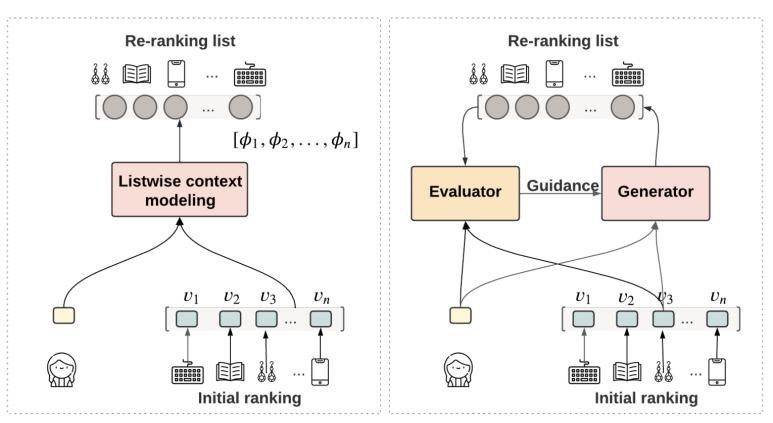
아래 그림에서도 보이지만 re-ranking stage가 필요한 이유는 유저의 유용성(utility)을 극대화하고자함이다.

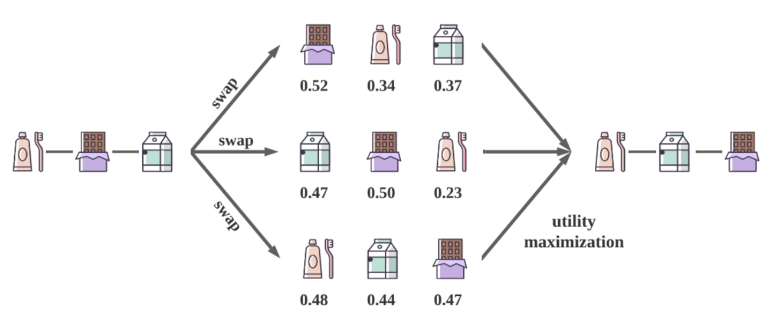
이처럼 Counterfactual Context를 고려하여 학습할 때 여러 경우의 수에서 가장 최선의 결과물을 뽑기 위해 유저의 utility 함수도 함께 설계하는 논문(Xi, Yunjia, Weiwen Liu, Xinyi Dai, Ruiming Tang, Weinan Zhang, Qing Liu, Xiuqiang He, and Yong Yu. "Utility-oriented re-ranking with counterfactual context.")도 있는 반면, 유저의 히스토리를 embedding하여 유저의 profile과 candidate 아이템 리스트간의 연산을 통해 유저의 단기 선호(interest)와 장기 선호를 반영한 re-ranking 접근법도 있다.
이처럼 NN 기반의 re-ranking 알고리즘들이 트렌드가 되고 있다. 여러 논문들이 있지만 이들을 2가지의 기준으로 분류할 수 있으며, 앞으로는 단일 objective가 아닌 여러 개의 objective를 동시에 충족하면서, counterfactual signal로 학습된 모델이 인기를 끌어나갈 것이라고한다. 좀 더 개인화된 추천결과를 제공하기 위한 방향으로 발전해나가고 있는 것이다.
그 외에도 요즘의 추세에 맞추어 multimodal 방향에 맞는 integrated re-ranking이나 federated learning을 결부한 edge re-ranking방식도 점차 발생하고 있다고 한다.
소개한 논문이 요약이지만 꽤 정보를 많이 담고 있어 추천시스템 관련 업무/공부를 하고 있는 분이라면 시간을 들여 읽어보는 것을 추천한다.
'Tech > RecSys' 카테고리의 다른 글
| Transformers4Rec - 추천시스템과 Transformer (0) | 2023.01.05 |
|---|---|
| BERT4Rec - 추천시스템과 BERT (0) | 2023.01.03 |
| 추천시스템 - (4) 이커머스 추천 문제 (0) | 2022.01.02 |
| 추천시스템 - (2) One-class Collaborative Filtering (1) | 2021.09.20 |
| 추천시스템 - (1) 개요 (0) | 2021.09.13 |


