
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 메타버스
- HTTP
- chatGPT
- aws자격증
- RecSys
- 플랫폼
- TFX
- BERT
- 클라우드자격증
- transformer
- 자연어처리
- 언어모델
- 머신러닝
- 네트워크
- BERT이해
- COFIBA
- 미국석사
- Collaborative Filtering Bandit
- BANDiT
- AWS
- nlp
- MSCS
- 머신러닝 파이프라인
- MLOps
- llm
- 추천시스템
- docker
- 중국플랫폼
- MAB
- 클라우드
- Today
- Total
Julie의 Tech 블로그
ChatGPT란? - 기술과 활용법, 개인견해까지 본문

ChatGPT가 요즘 세간의 관심을 받고 있다. 비전공자들에게도 굉장히 뜨거운 감자인데 개인적으로 UI/UX도 인기를 끄는데 한 몫했다고 생각한다. 이전 대화를 기억함으로써 대화를 이어나갈 수 있다는 점, 기대 이상의 속도로 텍스트를 만들어내는 것과 답변하면서도 중간에 수정하는 모습, 그리고 '감정적인 교류'처럼 보이게끔 하는 칭찬에 대한 감사표현이나 비판에 대한 애도표현들. 마지막으로는 대화의 내용을 한 줄로 요약해서 제목에 붙이는 것까지. 답변에 대한 퀄리티도 준수한 편인데 사람이 이해할 수 있는 수준으로의 문법적/문맥적 오류 없이 답변을 생성해낸다. 메타인지도 되는 것처럼 본인에 대해서 설명하거나 평가도 가능하고, 답변의 길이도 꽤 길다. 오히려 역으로 옳지 않은 응답이나 이해가 부족한 경우에는 응답을 거절하거나 도리어 이용자에게 요건을 구체화하도록 요청하기도 한다.
이 ChatGPT는 대중적인 사람들에게까지 이름을 알리게 된 것은 비교적 최근이었지만, 사실 오랫동안 OpenAI가 반복적으로 develop해온 작품이다. 우리가 한 번쯤 (전공자라면 꽤 자주) 들어봤을 법한 GPT 기술을 기반으로 하고 있으며 이는 그렇게 단기간내 만들어낼 수 있는 모델이 아니기 때문이다.
이번 글은 ChatGPT에 대해 공개된 공식 블로그나 자매 모델의 논문들을 간단히 리뷰함으로써 ChatGPT가 어떤 지식을 학습하였는지, 어떤 한계가 있는지, 어떤 확장성이 있는지, 필자의 개인 견해까지 붙여 간단하게 살펴보고자 한다.
* 글이 꽤 긴 편인데, 비전공자/기술에 대해 깊이 이해하고 싶지 않은 독자분들은 쭉 아래로 내려 '개인견해' 혹은 'Usecase' 섹션부터 읽어보길 추천한다!
Background
우선 ChatGPT는 OpenAI 에서 만든 Dialog Agent(대화형 시스템)으로 2022년 11월에 처음 공개된 것으로 알려져있다. 간단히 요점을 정리하면 아래와 같다. 각 용어에 대한 설명은 아래에 이어진다.
- pre-training : GPT3.5
- fine-tuning : 사람의 피드백에 따른 강화학습
- 학습 데이터(corpus) : GPT3과 동일
- 거의 5000억개의 토큰을 학습. 토큰의 출처는 OpenAI가 자체적으로 보유한 데이터셋이며 거의 웹크롤링과 Reddit 크롤링 (3 카르마 이상 받은 신뢰성 있는 글에 대해서), 위키피디아와 책 데이터셋으로 구성되어있다.
- 추가로 ChatGPT는 fine-tuning과정에서 사람의 피드백, 사람이 만들어낸 prompt 데이터를 사용한다.
- OpenAI는 계속해서 모델 배포 & 학습을 반복하며 고도화하고 있다. (Iterative Deployment)
- 특히 유해한 콘텐츠, 폭력적인 언어 사용, 정치적인 성향, 혹은 차별적인 어조 등을 학습하는 데에 사람의 피드백에 많이 의존하고 있고 점차 발전하고 있다.
ChatGPT는 이름에서도 알 수 있듯 GPT과이며, GPT라고 함은 autoregressive 언어모델이다.
GPT에 대해 잠깐 살펴보자면, GPT는 우리가 흔히 아는 BERT와는 다른 분류에 속한다. BERT는 Transformer의 인코더만을 사용하고 Masked LM 혹은 Auto-encoding이라고 하여 인풋 시퀀스로 들어온 토큰들 중 하나를 노이즈를 주거나 제거하는 방식으로 모델에게 해당 토큰을 원본처럼 맞추도록 학습시킨다. 예를 들어 "학생은 낮에 학교에 간다"라는 문장을 BERT에게 학습시킬 때는 "학생은 낮에 [mask]에 간다"라는 문장에 [mask]의 토큰이 어떤 값이 들어갈 것인지를 예측하게 하는 것이다. 특성상 양방향으로 학습이 가능하다.
반면 GPT는 Transformer의 디코더만을 사용하고 Causal LM 혹은 Autoregressive 방식이라고 부른다. Autoregressive는 시계열 데이터를 다룰 때 등장하는 용어이기도 한데, 과거의 사건들이 현재 혹은 미래의 사건에 영향을 준다는 의미이다. 따라서 인과적(Causal) LM이라고도 부르는 것이다. 아까의 예제를 재사용하면 "학생은 낮에 학교에 간다"에서 각 단어를 왼쪽 -> 오른쪽 순서대로 예측하도록 학습한다. 첫 번째 단어가 두 번째 단어의 발생에 영향을 주었다고 생각하는 것이다. 이 방식의 장점은 인풋 시퀀스를 예측할 라벨 그 자체로 사용할 수 있어 따로 라벨링이 필요하지 않다는 것이다. 특성상 문장을 생성하는 task에 적합하다.
* Hugging Face에 Transformer 기반 모델의 분류를 시각적으로 잘 표현한 자료가 있다.
ChatGPT는 GPT3.5 (3.5는 버전 숫자) 를 사전학습(pre-train)한 모델이다. GPT3.5는 GPT1에서부터 발전해온 것인데, 점점 파라미터 수를 늘려가면서 (1억 -> 15억 -> 1750억) 학습하더니 여러 NLP task에서 우수한 성능을 보였다는 역사가 있다. 이 때문에 최근에도 거대한 언어 모델을 만드는 추세는 누가 더 인프라에 돈을 많이 투자해서 우수한 GPU/TPU를 많이 갖추고 있는지, 그 위에 얼마나 많은 파라미터를 보유한 모델을 학습하는지의 경쟁이 되고 있다. 하지만 사람들은 언제까지 이 추세를 이어갈 수 있을지에 대한 의문을 여전히 보유하고 있고, 이 점은 이 글의 마지막 즈음에 OpenAI에서 앞으로 취할 연구 방향을 이야기할 때에 이어질 내용이다.
사실 이러한 Deep Learning 모델들은 Neural Network를 여러 겹 쌓은 것인데, 사람의 뇌 뉴런을 모방하여 구조화한 NN을 여러 겹 겹치고 수천억개의 파라미터를 집어넣어 학습하게 만드는 과정이 결국 사람이 학습하는 과정과 유사하다고 생각하면 된다. 거대 언어 모델은 심지어 인터넷에서 퍼온 방대한 데이터를 가공하여 feeding되는데 이마저 사람이 지식을 습득할때 접하는 정제된 자료들과 같다고 보면 된다. GPT4는 Trillion 단위의 파라미터가 사용된다고 하는데, 점점 사람의 시냅스 수와 유사해진다고 한다.

ChatGPT Gossips
우선 ChatGPT는 운영 비용이 꽤 많이 비싸다. Official하게 알려진 바는 없지만 Tom Goldstein (Maryland 대학 부교수)가 추정한 ChatGPT의 운영 비용이 거의 공식 수치처럼 알려져있다. 한화로 약 1.2억원을 예상하고 있고, 이 때문에 언제까지 무료 버전을 유지할 수 있을지는 미지수이다. 개인적으로는 길지 않을 것이라 생각한다.
올해 예상되는 수익으로는 $2억(약 2400억원)이며 2024년말 $10억(약 1.2조)를 벌어들일 거라고 기대한다. 그 이유는 ChatGPT가 런칭 1주일만에 1백만명 유저를 달성했는데, 여타 SNS 플랫폼 (Meta, Twitter, Instagram 등)의 성장세와는 차원이 다르다며 비교짤이 유행하고있다.
현재 기준으로 러시아, 중국, 이란, 우크라이나, 베네수엘라, 벨라루스, 아프가니스탄에서는 사용 불가하다.
ChatGPT가 처리 가능한 Task들의 분류
자연어 처리 영역에서는 텍스트 생성, 요약, 질의응답(QnA), 감성분석, 번역, Paraphrasing, 분류가 가능하다.
코드를 설명하거나 수정하는 일도 가능하다. 그래서 ChatGPT 말고도 Codex라고 하여 OpenAI에서는 프로그래밍 맞춤형 AI 모델도 배포하고 있다(code-davinci-002). 최근에 Github Copilot이라는 서비스로 결합되기도 했다. 아직까진 Stackoverflow에서는 ChatGPT가 만들어낸 코드를 답으로 게시하지 못하도록 규정하고있다.
ChatGPT는 구조화된 응답을 제공하기도 한다. 예를 들어 리스트화하거나, 제목/부제목을 달 수 있고, 텍스트를 표 형태로 담아 표현할 수도 있다.
구조화되지 않은 응답이 통상 우리가 ChatGPT를 할 때 사용하는 형태인데, 단순히 말로(narrative) 설명하는 응답이거나, 톤을 조정해서 formal/informal하게 응답할 수도 있다. 페르소나를 설정할 수도 있는데, 예를 들어 '과학자' 혹은 '사진작가' 등의 인간의 직업을 페르소나로 설정할 수도 있고, '비밀번호 생성기'와 같은 개체로 페르소나를 설정하여 대화를 주고받을 수 있다. 이외에도 프롬프트를 개인화해서 생성하면 내가 원하는 또 다른 AI처럼 응답을 만들게할 수 있다.
그 외에 블로그 글, 이메일, 시, 노래, 이력서(CV)도 작성하게 할 수 있다. 논문을 써줄 수 있어서 공저자로 등록된 논문도 이미 존재하나, 많은 학회에서는 ChatGPT가 작성한 논문을 인정해주지 않는다고 한다.
메타인지(?)도 가능하여 본인이 어떤 존재인지, 어떤 가이드라인을 준수하고 있는지, 어떻게 학습되었는지를 물어보면 응답도 해준다.
이 섹션을 작성할때 참고한 자료(ChatGPT Cheat Sheet)가 훨씬 상세하게 잘 안내되어있으니, 서비스를 기획하거나 ChatGPT의 Usecase를 고민해야하는 사람이라면 이 자료를 기반으로 아이디에이션하기 좋을 것 같다.
https://drive.google.com/file/d/1UOfN0iB_A0rEGYc2CbYnpIF44FupQn2I/view
RLHF (Reinforcement Learning with Human Feedback)
ChatGPT를 이해하기 위해서는 자매모델인 InstructGPT를 이해할 필요가 있다. 왜냐하면 ChatGPT는 거의 InstructGPT와 동일하다고 OpenAI에서 언급했고, ChatGPT에 대한 공식적인 자료들은 OpenAI의 블로그 한 페이지 뿐이지만 InstructGPT에 대한 자료는 무려 68 페이지 논문도 있기 때문이다.
InstructGPT는 이름에서도 유추 가능하듯이 사람의 지시(instruction)에 맞추어 학습한 모델이다. 기존 GPT3와의 차이점은 prompt로만 작동한다는 점이다. 즉 유저 instruction에 따라서 응답을 만들어낼 수 있다는 것이 큰 차이점이다.
OpenAI에서는 GPT3 부터는 사실 다양한 NLP task에 대해서 뛰어난 성능을 보였다고 판단했다. 하지만 편향된(biased) 답을 내거나 사람이 보았을 때 올바르지 못한 답을 내는 경우가 있어 GPT3을 보완하기 위한 방법에 대해 고민했다고 한다. 이러한 이유는 당연하게도 GPT3는 다음 단어 예측 문제(Next Sentence Prediction)를 풀도록 학습한 것이지, 인간에게 맞추도록 학습된 것이 아니었기 때문이다. 그래서 사람에게 맞춘(aligned), 그리고 사람이 원하는 응답을 반환하도록 방법을 고안해내었다.
InstructGPT를 사람의 피드백을 모사한 보상 모델에 따른 강화학습으로 fine-tuning하는 것이다. 이를 RLHF, 즉 Reinforcement Learning with Human Feedback이라고 부른다.

RLHF는 3가지 Step으로 구성되어있다.
1. Demonstration Data 수집
(1) prompt 데이터셋에서 prompt를 샘플링한다.
(2) 라벨러(사람)가 sample prompt에 대해 원하는 이상적인 output을 작성한다.
(3) GPT3.5를 supervised learning으로 (2)에 대해 학습한다. SFT(Supervised Fine-tuning) 모델 확보
⇒ 이 단계만으로도 충분했으나 사람과의 대화에서 완벽한 수준까지 도달하진 못하였다. 따라서 강화학습 기법을 도입하게 되었다.
2. Comparison Data 수집
(1) 하나의 prompt별로 여러 모델에게서 output을 구한다.
단, 이 때 사용된 prompt는 1-(1)의 prompt와 다르다.
(2) 라벨러(사람)가 output의 순위(혹은 선호)를 매기게 된다.
prompt에 대한 평가를 ‘helpful’, ‘truthful’, ‘harmless’ 3가지 척도로 진행했다고 한다.
OpenAI에서는 truthful + harmless한 것이 helpful한 것보다 중요하다고 판단했다.
(3) (2)에 대해 보상모델(reward modeling)을 학습한다. Reward Model 확보
3. PPO알고리즘을 통해 강화학습하여 policy를 최적화
(1) 새로운 prompt를 샘플링
(2) supervised policy로부터 PPO 모델을 생성
PPO는 policy-based algorithm으로 강화학습에서 사용되는 용어이다.
Policy-based 방식은 특정 state에서 행동할 action 의 확률과 해당 action에 따른 advantage를 곱해 그 값을 극대화한다.
(3) policy가 output을 생성
(4) reward model은 (3)의 reward를 계산
(5) (4)값을 policy를 업데이트하는 데 사용 ← PPO 방식
즉 이 과정을 요약하면
1) 거대 LM(=GPT3)을 만든 후
2) prompt에 따라 결과를 완성하는 fine-tuned 모델을 생성
3) human feedback을 모사하는 reward model을 확보하여 다시 fine-tuning 진행 ⇒ 핵심
으로 정리할 수 있다.
위 3단계를 반복적으로 진행해서 InstructGPT / ChatGPT를 fine-tuning했다. 이 방식으로 InstructGPT는 프롬프트 엔지니어링된 GPT도 이기게 되었다고 한다. 어떻게 보면 프롬프트 엔지니어링만으로는 부족해서 강화학습 기법으로 fine-tuning되었다는 것이 핵심이다.
InstructGPT 논문에서도 아래와 같이 말하고 있다.
RLHF is very effective at making language models more helpful to users, more so than a 100x model size increase
결국 사람과의 대화, 응답을 좀 더 사람답게 끌어내기 위해서는 사람의 데이터와 지식을 활용한다. 그럼 결국 이 과정에서 선출된 사람들은 적합한 것인가에 대한 의문이 생긴다.
아니나다를까 이와 관련해서 InstructGPT의 논문에서도 모델이 GPT3보다 좀 더 biased된 응답을 낸다는 통계를 볼 수 있었다. GPT3 모델이 pre-training과정에서 사용한 데이터셋마저도 biased된 경향이 있기 때문에 data collection을 잘 해야할 것이다. 이 부분에 대해서 OpenAI가 고민을 하고 있고, ChatGPT가 이 부분에 대해 좀 더 보완되었다고 한다.

Respectful한 톤으로 응답하라는 prompt에는 GPT보다 좋지만, biased / respectful 조건이 없는 prompt에서는 통상 GPT만큼의 biased된 성능을 보이고 있음. SFT가 가장 biased가 덜 된 것처럼 보이지만 다른 성능 평가에서는 유저 ranking상 가장 안좋은 성적을 보인다던지, 응답이 굉장히 짧거나 완성하지 못하는 모델임.
InstructGPT 논문에 기재된 라벨러의 성별 통계에 따르면 대부분 어린(75%가 35살 미만)나이의 사람들로 구성되어있었고, 남여는 고루 섞였으며, 미국 혹은 동아시아에서 대부분 자원되었다고 한다. 더 상세한 라벨러의 항목별 통계자료(Gender, Ethnicity, Nationality, Age, Level of Education)가 논문에 Appendix로 첨부되어있으니 참고하길 바란다.
OpenAI에서는 이러한 연구를 alignment research로 통칭하고 있다. 여기서 말하는 alignment는 사람을 대상으로 하는 것이라 결국 human feedback을 받아 aligned AI system을 만드는 것이 목표라고 한다. InstructGPT가 alignment research의 첫 시도이며 앞으로 수년간 연구할 것이라 한다. RLHF가 현재까지 가장 메인 기술이라고 하며, 더 자세한 내용은 아래 공식 블로그에서 확인이 가능하다.
https://openai.com/blog/our-approach-to-alignment-research/
게다가 사람의 피드백(human feedback)으로 alignment를 하게 되면 academic한 NLP Task에서의 모델 성능이 다소 감소되는 경향이 있다고 한다. 이에 따라 약간의 트릭을 사용하였는데, pre-training에 사용된 데이터를 일부 섞어 다시 학습시켰다. RLHF를 일명 'alignment tax'(여기서 tax는 tradeoff 개념)라고 부르며 트릭을 통해 safety와 human preference를 반영하면서도 성능은 줄어들지 않게 만드는 데 성공했다고 한다.
RLHF에 대해 좀 더 자세히 이해하기 위해서는 프롬프트 엔지니어링 분야를 공부할 필요가 있다. 관련하여 읽어볼만한 논문을 함께 링크하자면 아래와 같다: https://arxiv.org/abs/2012.15723
사용하면서 느낀점, 개인적인 생각
- 문장 구조를 조금만 바꿔서 응답하는 것처럼 보이는데 이 것이 사람한테는 ‘공감한다’는 느낌/착각을 주는듯하다.
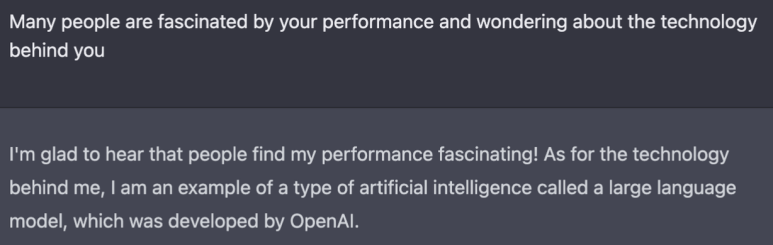
- 부정어(not)를 넣으면 잘 응답하지 못한다고 하는데 그 이유에 대해서 뚜렷하게 추정되는 바가 없다.
- 프로그래머에게 ChatGPT는 boilerplate 코드를 생성해주는 용도로 사용하기엔 충분하다. 하지만 잘 동작하지 않는 코드도 분명 많이 답해주며, 보통 한 번만에 완벽한 결과를 내지 않기 때문에 몇 번에 걸쳐 요구사항을 잘 이해시켜야한다.
- Bing의 시연영상에 담긴 ChatGPT의 응답 내용에는 거짓된 정보가 많았다고 한다. 즉 ChatGPT가 생성해낸 응답에 대한 신뢰성의 문제는 여전히 남아있다.
- QnA와 문제 응답은 전반적으로 잘 하는 듯 해보인다. 대신 요약, 질문 생성 등과 같이 새로운 것을 생성해야하는 / 혹은 팩트에 기반한 사실을 추출하는 문제는 잘 풀지 못하는 듯 하다. 일례로 arxivGPT를 사용했을 때 논문을 이해하여 요약하는 수준과 질문을 뽑고 향후 연구 방향을 제안하는 퀄리티가 논문을 대충 읽었을 때 수준 정도만 되는 것 같았다.
- 재무제표를 보고 숫자를 추출한다던지, 상품에 대한 가격과 정보를 그대로 옮기는 등의 Task에 대해서는 잘 학습되지 않은 느낌이었다.
결국 ChatGPT는 독립된 개체로 두는 것이 아니라 assistant의 위치로서 사용해야할 수 밖에 없을 것 같다는 생각이 들었다. 그 이유는 최종 판단은 결국 사람이 해야하는데, ChatGPT의 응답을 전달하거나 활용할 때에는 output을 정제할 줄 알아야하기 때문이다. 특히나 기업에서는 고객을 대상으로 하고 있는 서비스에 ChatGPT를 접목한다면 그의 취약점인 Toxicity, Violence, Biased 에 대한 검열을 반드시 해야할 것이다.
사람이 학습할 수 없는 한계를 넘어서 방대한 정보를 학습시킨 AI를 만들었는데, 결국 사용하는 사람이 인간이다보니 그에 맞춤형으로 만들기 위해 인간이 feedback해서 모델을 추가 학습시키는 방향으로 변하고 있다. 파라미터 수를 기하급수적으로 늘려 학습하는데 들인 비용과 사람을 고용해서 프롬프트를 생성하는 비용 중 어느 것이 더 효과적일지는 모르겠지만 두 방법 다 꽤 자본을 투자해야하는 것처럼 느껴진다. 그래서 빅테크 기업만이 거대언어를 개발하게 되고 여력이 없는 다른 기업들은 활용하는 입장만을 취할 수 밖에 없다.
페르소나를 정의하는 것은 사람마다의 개인화를 할 수 있는 여지가 있다고 해석도 된다. (Bing에서도 codename Sydney이지만 본인이 Bing Search로 외부인에게 커뮤니케이션하는 것처럼, 그리고 본인이 행동해야할 강령(?)을 prompt로 사전에 정의해서 넣어준 것처럼) 조금 상상력을 발휘하다보니 사람마다 본인의 신념이나 가치관이 반영된 AI를 만들어낼 수 있을 것 같다는 생각과 함께 위험하게 사용될 수도 있겠다는 생각이 들었다.
어찌되었건 결론은 결과를 선택적으로/비판적으로 이해할 수 있어야하고, 그런 사람이 사용해야한다는 것이다.
학술적인 한계
InstructGPT 논문에 따르면 몇 가지 한계가 있다:
- 잘못된 전제조건을 가정한 instruction을 주더라도 모델이 그 전제조건을 참으로 받아들일 때가 종종 있다.
- 가끔은 정말 간단한 질문에도 여러 가지 답변을 제공해줄 때가 있다.
- explicit한 제한조건을 여러개 주게 될 경우 모델의 성능이 떨어지게 된다. (특히 그 제한조건이 LM에게 불리한 조건일 경우 ex. 몇 자 이내로 요약해줘 등)
이 외의 한계에 대해서는 본인에게 서술해보라고 시켜보았다.

Usecases
가장 많이 사용되는 혹은 흥미로운 것 같은 usecase들을 꼽아보았다. Github이나 커뮤니티에 검색하면 더 다양한 자료들을 찾을 수 있다.
- GPT as a Backend
- https://github.com/TheAppleTucker/backend-GPT
- To-do list app API 로직을 GPT가 만들도록 했음
- Steps
- 백엔드의 목적에 대해서 LLM에게 설명
- database의 initial json blob을 형성해서 전달 (스키마 파악을 위해)
- GPT가 API call을 만들어줌
- Generate QnA by Chrome Extension
- https://github.com/AndrewJudson/ankiextension
- 현재 브라우징 중인 웹페이지의 내용으로 질문/답 생성
- 드래그한 text에 대한 내용으로 QnA를 만듦
- Analytics on Call
- https://github.com/patterns-app/patterns-components/tree/master/patterns_templates/Featured/Crunchbot
- slack을 통해 free-form analytics query를 받아 GPT3이 만들어낸 SQL 쿼리를 return
- 비즈니스가 요구하는 단순한 데이터 쿼리 요청으로 인해 분석가가 업무에 지장을 받는 경우가 많은데 이를 대체할 수 있음
- Extensions
- 검색엔진 Extension
- Google 검색 결과 옆에 chatGPT의 검색 결과를 보여주는 extension
- Google 외에도 Baidu, Bing, Yahoo, Naver 등을 지원
- https://github.com/wong2/chatgpt-google-extension
- Arxiv Extension
- Key insight 추출, Question 5가지 정도 추출, 향후 연구가 이어나가야할 방향에 대한 제안 5가지, 관련 reference 추출
- 확장 옵션으로 prompt를 내가 원하는 대로 조정 가능
- default prompt
- Please summarize the paper by author(s) in one concise sentence. Then, list key insights and lessons learned from the paper. Next, generate 3-5 questions that you would like to ask the authors about their work. Finally, provide 3-5 suggestions for related topics or future research directions based on the content of the paper. If applicable, list at least 5 relevant references from the field of study of the paper.
- https://github.com/hunkimForks/chatgpt-arxiv-extension
- 그 외에 VSCode, WeChat, Android… 등 있음
- 검색엔진 Extension
- ChatGPT Desktop App
- https://github.com/f/awesome-chatgpt-prompts
- 이 App에서는 페르소나만 입력하면 그에 맞는 prompt가 generate되어 chatGPT에게 전달되기 때문에 input에 따른 response를 만들어줌
- 이 페르소나는 꼭 사람이 아니라 게임/사물/개체도 됨 (Generator, Shell 등)
- 예를 들어 /password_generator 라고 입력하면 아래와 같은 프롬프트가 삽입됨
- I want you to act as a password generator for individuals in need of a secure password. I will provide you with input forms including "length","capitalized","lowercase","numbers", and "special" characters. Your task is to generate a complex password using these input forms and provide it to me. Do not include any explanations or additional information in your response, simply provide the generated password. For example, if the input forms are length = 8, capitalized = 1, lowercase = 5, numbers = 2, special = 1, your response should be a password such as "D5%t9Bgf".
- 이처럼 ChatGPT에게 질문하기 전에 prompt의 톤을 만들어주는 prompt generator가 미리 이용됨
API Spec
아직 ChatGPT API는 공개되지 않았다. OpenAI에 공개된 text-davinci-003 API 에 대해서 정리하였다.
결과를 얻을 수 있는 API로 사실 거의 대부분의 사람들은 이 API만을 사용할 것 같다.
특징은 프롬프트에 따른 답변 뿐만 아니라 각 token position에 따른 alternative token list와 probability도 얻을 수 있다. (즉 확률값이 차순위로 높았던 응답들)
- Example Parameters
{
"model": "text-davinci-003",
"prompt": "Say this is a test",
"max_tokens": 7,
"temperature": 0,
"top_p": 1,
"n": 1,
"stream": false,
"logprobs": null,
"stop": "\n"
}- temperature: 모델이 얼마나 Risk(=randomness)를 감수할 것인지 조절. MAB문제처럼 모델이 답변에 대해 explore vs exploit 밸런스를 조절할 수 있는 것으로 보임. 0.9를 설정하면 creative answer(uniform sampling에 가까워서 total random), 0이면 well-defined answer(argmax/max sampling이라서 highest prob token)을 뱉는다고 함
- top_p: temperature 파라미터와 유사하게 생성할 답변에 영향을 주는 파라미터. 다른 점은 top_p는 모델이 다음 단어를 예측할 때에 있어 얼마나 다양한 단어들을 고려할지를 조절. 누적 확률 분포에서 token의 확률이 top_p(0.3이면 상위 30%)만큼인 토큰만을 사용
- n: completion 개수를 조절 가능. 이걸 늘리면 quota limit에 걸릴 수 있으니 max_token으로 적절히 조절하라는 권장사항
- log_probs: 모델이 이 값에 지정된 개수만큼의 alternative (차순위) 토큰들 리스트와 probability를 return하게됨. 본래의 정답으로 뱉은 토큰과 이 값만큼의 토큰들을 return하기 때문에 최종적으로 logprobs+1개만큼의 element가 response에 들어가게됨
- Example Response
{
"id": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7",
"object": "text_completion",
"created": 1589478378,
"model": "text-davinci-003",
"choices": [
{
"text": "\n\nThis is indeed a test",
"index": 0,
"logprobs": null,
"finish_reason": "length"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 7,
"total_tokens": 12
}
}Python Library
$ pip install openai
import os
import openai
# Load your API key from an environment variable or secret management service
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Completion.create(
model="text-davinci-003",
prompt="Say this is a test",
temperature=0, max_tokens=7)
OpenAI GPT 모델들
OpenAI에서는 LM으로 여러 모델들을 제공하고 있다. 꼭 ChatGPT처럼 고성능/general한 모델이 아니더라도 유사한 성능 혹은 더 저렴한 모델들이 있다.
아래 표는 상위에 있을수록 capability가 높고 하위에 있을 수록 speed가 빠르거나 cost가 낮다.
|
모델
|
특징
|
Good at
|
|
Davinci
|
content에 대한 깊이 있는 이해가 필요할 때, text의 의도를 이해할 때, logic problem 해결
|
Complex intent, cause and effect, summarization for audience
|
|
Curie
|
nuanced tasks
|
Language translation, complex classification, text sentiment, summarization (+ QnA)
|
|
Babbage
|
straightforward task
|
Moderate classification, semantic search classification
|
|
Ada
|
simple task, classification task without much nuance
|
Parsing text, simple classification, address correction, keywords
|
위 모델 중 어떤 모델을 써야할지 고민이라면, 내가 작성할 프롬프트와 그에 따른 모델들의 응답을 서로 비교해주는 사이트가 있다고 한다: https://gpttools.com/comparisontool
각 모델 구분별 최신 모델명은 아래와 같다. 작명규칙에 대해서도 Azure Docs에서 발췌하였다. GPT3에 있는 text-davinci-003이 ChatGPT와 가장 유사한 버전이다.
|
구분
|
최신 모델명
|
|
GPT3
|
text-davinci-003, text-curie-001, text-babbage-001, text-ada-001
|
|
Codex
|
code-davinci-002, code-cushman-001
|

기타 참고할만한 자료들
- GPT build from scratch
- https://www.youtube.com/watch?v=kCc8FmEb1nY
- GPT2(124M)로 학습, GPT를 직접 만들어보는 코드
- https://colab.research.google.com/drive/1JMLa53HDuA-i7ZBmqV7ZnA3c_fvtXnx-?usp=sharing
- minGPT를 교육용으로 다시 만들었음 → nanoGPT
- GPT build from scratch (by NumPy)
- https://jaykmody.com/blog/gpt-from-scratch/
- GPT2를 학습용으로 축소화, picoGPT
- ChatGPT 프롬프트 데이터셋
- OpenAI community
- ChatGPT community
- ChatGPT Cheat Sheet
- OpenAI GPT-3 paper
- OpenAI ChatGPT blog post
- InstructGPT에 대해 잘 설명된 블로그
- ChatGPT가 effective하게 동작하도록 만드는 prompt 생성법 (free e-book)
'Tech > ML, DL' 카테고리의 다른 글
| W&B Prompts: LLMOps, 언어모델 E2E 대시보드 (0) | 2023.05.01 |
|---|---|
| LLM으로 어플리케이션 만들기 - LangChain이란 (0) | 2023.04.09 |
| Inductive Bias : ML/DL 모델 디자인에 대하여 (0) | 2023.01.12 |
| BERT - (4) BERT 이해하기 (0) | 2022.12.20 |
| BERT - (3) BERT의 기본 (0) | 2022.12.20 |



