
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 중국플랫폼
- 미국 개발자 취업
- 플랫폼
- maang
- nlp
- 네트워크
- chatGPT
- 언어모델
- AWS
- 머신러닝
- BERT
- MAB
- transformer
- HTTP
- BERT이해
- docker
- swe취업
- 자연어처리
- 합격후기
- 클라우드
- 클라우드자격증
- RecSys
- MLOps
- BANDiT
- TFX
- llm
- 미국석사
- MSCS
- 추천시스템
- 메타버스
- Today
- Total
SWE Julie's life
Inductive Bias : ML/DL 모델 디자인에 대하여 본문
우리가 머신러닝 모델을 설계하는 것은 결국 관측 가능한 범위에서 샘플링된 데이터를 활용하여 알고 싶은 데이터의 특성 혹은 분포를 예측하는 모델을 디자인하는 과정이다. 이 역시 통계학에서처럼 사람이 세상의 모든 데이터와 그 분포에 대해 알 수 없듯이, 모델도 제한된 범위에서의 데이터로 최대한 일반성을 지닐 수 있도록 설계한다.
Inductive bias는 모델의 아키텍쳐를 설계할 때/이해할 때 중요하게 고려해야하는 개념이라고 생각한다. Inductive bias란 모델이 학습하지 않은 데이터에 대해 추론할 때 참고하는 어떠한 가정/편향이다. 예를 들어 내가 고양이와 생선 이미지로만 이미지 인식 모델을 학습시켰는데, 전혀 다른 개체의 이미지에 대해 모델에게 라벨링을 하라고 한다면 모델이 기존에 고양이와 생선 이미지들로 학습했던 과정에서 익힌 지식을 활용하게 된다. 이 때 학습과정에서 익힌 지식을 inductive bias라고 한다. 다른 말로 설명하자면, 모델은 목표함수(target function)에 따라 학습데이터와 예측값간의 차이(loss)를 줄이며 최적의 형태(predictor)를 맞춰나가는데, 이 때 학습데이터를 넘어서서 학습하게된 가정(assumption)을 의미한다. 영어 표현 그대로 ‘inductive (귀납적)’ + ‘bias (편향)’이다.
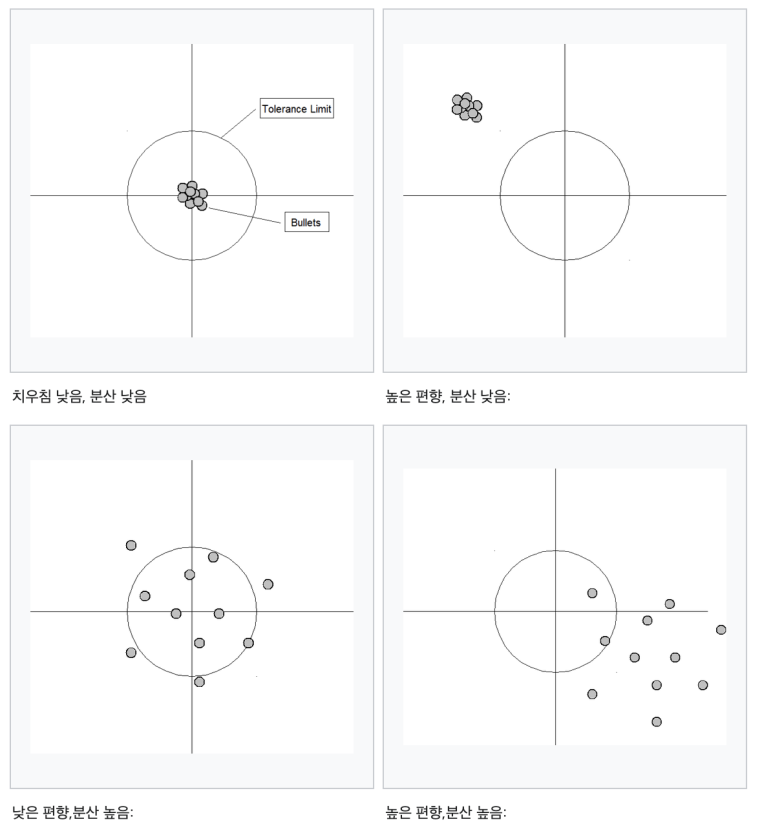
흔히 bias-variance tradeoff 라고 하여 모델이 이상적으론 bias도 낮고 variance도 낮아야하지만 이 둘을 모두 동시에 취하긴 어렵다. Bias가 높은 경우는 모델이 학습 데이터의 특성을 충분히 학습하지 않아 underfitting되었다고 판단하며 variance가 높은 경우는 모델이 학습 데이터의 특성을 너무 세세하게 학습하여 overfitting되었다고 판단한다. Bias는 보통 학습데이터를 교체했을 때 모델의 정확도가 어느 정도 차이나는지를 관측하게 되고, variance는 특정 데이터에 모델이 얼마나 민감하게 반응하냐를 관측하게 된다.
우리는 모델이 너무 학습 데이터에만 맞춤형으로 학습하지 않기를 바란다. 학습데이터가 전체 데이터를 대표하기에 부족함이 있을 수 밖에 없기 때문이다. 물론 데이터가 풍부하게 많은 상황이라면 모델이 어떠한 inductive bias를 갖고 있더라도 문제가 되지 않는다. 대신 보통의 상황처럼 데이터가 적은 경우 모델이 올바른 inductive bias를 보유하고 있도록하여 일반성(generality)을 갖출 수 있도록 하는 것은 중요하다.
데이터 도메인의 특성에 따라 주류 모델이 다른 이유도 inductive bias의 고려가 있었기 때문이다. 가장 처음에는 단순한 NN, MLP가 주류였지만 이제는 컴퓨터 비전 영역에서는 CNN, NLP에서는 Transformer, 시계열 데이터에서는 RNN 등이 주류를 이루고 있다. 이렇게 변화하게 된 배경은 각 모델의 아키텍쳐가 도메인의 특성에 맞게 inductive bias를 학습할 수 있도록 설계되었기 때문이다.

이미지 데이터는 지역성(locality)이라는 특성을 가지고 있다. 우리가 간단하게 사진을 상상해봐도 컴퓨터는 픽셀 단위로 데이터를 인지하지만 인접한 픽셀끼리는 거의 유사한 값을 지닐 것이다. 고양이 사진이라고 치면 귀 부분에 해당하는 픽셀들은 유사한 모양(shape)과 질감(texture)을 지니고 있기 때문이다. 이러한 특성을 살리기 위해 CNN이 적합한 모델이 된 이유는 conv layer 때문이다. 합성곱 신경망은 필터(혹은 local receptive field)가 이동하면서 윈도우 단위로 특성을 학습하게 된다. 이는 동일한 윈도우간의 weight sharing을 통해 translation invariance라는 inductive bias를 보유하게 해주는 요인이다. Translation invariance(여기서 translation은 translation motion이라고 하여 개체의 모든 점을 같은 방향 혹은 동일한 선 위에서 움직이는 것을 의미한다)란 개체의 위치가 변하더라도 동일한 개체로 인식할 수 있는 특징을 의미한다. CNN과 다르게 MLP에서는 동일한 값을 가진 input이 요소별 위치가 조금이라도 달라지면 벡터값이 아예 달라지기 때문에 translation invariance이 불가능하다. CNN은 그 외에도 연산한 결과의 위치가 윈도우가 참조하는 원본 픽셀들의 위치에 따라 달라지기 때문에 translation equivariance를 학습한다. Translation Equivariance는 개체의 위치가 변하면 연산의 activation 위치가 바뀌는 것을 의미한다.

시계열 데이터는 미래의 데이터가 이전 time step의 영향을 받는다는 특성이 있다. 과거의 데이터가 현재에도 영향을 미친다는 순차적인 특성(Sequential Relation이라고 표현)을 잘 학습하기 위해 이전 layer의 결과를 다음 layer에 활용하는 RNN 구조가 시계열 데이터에서는 유용하게 활용된다. 비슷하게 자연어 도메인에서도 앞선 토큰이 다음 토큰의 결과에 영향을 미친다는 가정(=우리가 왼쪽에서 오른쪽 방향으로 순서대로 말을 써내려가듯)으로 RNN이 유의미하게 활용되었다. 최근에는 인풋 시퀀스의 길이가 늘어난 영향(복잡한 구조의 문장이나 문단을 학습)과 모델이 문장의 context까지 이해하게끔 학습시키고자하는 니즈에 따라 Transformer 모델이 유행하고 있다. Transformer 모델은 인풋 시퀀스의 모든 토큰을 이용하여 연산하는 attention mechanism에 따라 상대적으로 CNN에 비해 inductive bias가 약한 편이다. 따라서 더 많은 데이터를 필요로한다. 실제로 많은 Transformer 기반 모델들은 대규모의 학습 데이터로 pre-training되어 일반성(generality)을 갖춘 덕에 다양한 NLP task에서 준수한 성능을 보이고 있다.
더 단순하게는 선형회귀(linear regression) 모델이 종속 변수가 독립 변수에 선형으로 의존할 것이라는 가정과 베이지안(Bayesian) 모델은 사전확률분포(prior distribution)이 사후확률분포(posterior distribution)에 영향을 줄 것이라는 가정도 마찬가지로 inductive bias이다. 선형회귀 모델은 구조상 단조성을 가정하고 있는데, 변수 중 어떠한 것도 증가하게 되면 모델의 결과가 감소(가중치가 음이면)하거나 증가(가중치가 양이면)할 것이라고 기대한다. 하지만 우리 사회에서는 단조적인 증감만으로 모든 데이터 패턴을 설명하기 힘들다. 우리의 몸 온도를 예로 보면 37도보다 엄청 높아도, 엄청 낮아도 둘 다 문제이다. 이럴 때는 선형을 가정하고 있는 모델보다는 현재 몸 온도와 정상온도 간의 차이를 고려할 줄 아는 좀 더 복잡한 모델을 설계해야할 것이다.
반면 FCN은 inductive bias가 약한 모델인데, input에서 output으로 전파되는 과정에서 weight가 각각 독립적이며 공유되지 않기 때문이다. 유사하게 Transformer도 attention 메커니즘을 통해 입력 데이터의 모든 요소간의 관계(attention weight)를 계산하므로 CNN보다 inductive Bias가 작다고들 말한다.
이처럼 input과 output간의 관계에 대한 가정/편향은 Relational Inductive Bias로 분류된다. 이 외에도 모델의 hypothesis space에 제한(constraint)을 두는 다른 테크닉들이 있는데, 대표적으로 weight decay, dropout, non-linear activation function이 있다. 이들도 inductive bias의 일종으로 볼 수 있다.
또는 모델 아키텍쳐보다 데이터와 데이터 전처리 과정 혹은 data augmentation이 어떠하냐에 따라 모델이 inductive bias를 다르게 학습할 수 있다는 의견도 있다. 즉 모델 자체의 bias도 있지만 데이터에서의 bias도 생길 수 있다는 관점이다. CNN 모델이 이미지의 모양(shape)에 초점을 두는지, 질감(texture)에 초점을 두는지에 대한 논쟁이 있었는데, 결국 어느 쪽이든 편향되어 학습할 수 있다는 결론이 났다.
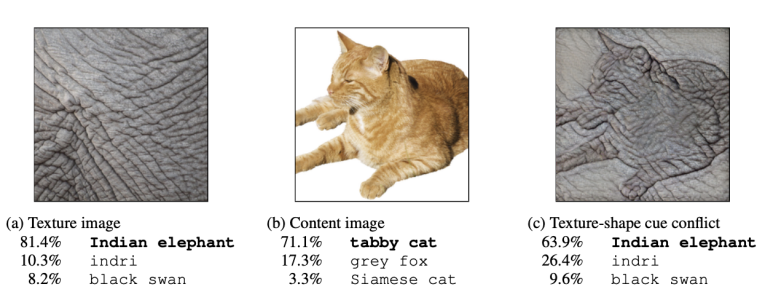
사실 두 모델 다 이미지 판별시 비슷한 정확도를 보일 수는 있으나 모양에 좀 더 편향된 (shape-based) 모델이 이미지의 노이즈로 인한 손실과 왜곡(distortion)에도 강한 성능을 보일 것이라 예측할 수 있다. 즉 색감왜곡(color distortion)이나 블러처리(blur)와 같은 data augmentation이 있었다면 texture bias를 낮췄을 것이고, 랜덤하게 크롭(random-crop)하여 데이터를 augmentation했다면 texture bias를 강화할 수 있는 것이다. 이를 적절히 섞어 모델이 모양과 질감에 변화를 준 집단 각각에서 번갈아가면서 샘플링하여 학습하였다면 최종적으로 shape bias와 texture bias를 모두 갖출 수 있다는 타 논문도 있다.
최근 AI 논문들에 inductive bias라는 용어가 많이 등장한다고 한다. inductive bias는 결국 우리가 원하고자 하는 방향으로 모델을 학습시킬 때 충분히 고려해야할 개념이다. 학습하는 데이터를 어떻게 가공하느냐에 따라 모델이 다른 bias를 가질 수도 있지만, 어떤 구조의 모델을 선택하느냐에 따라 bias를 가질 수도 있게 된다. 그리고 과적합을 방지하기 위해 적용할 수 있는 정규화 테크닉들도 마찬가지이다.
'Tech > ML, DL' 카테고리의 다른 글
| LLM으로 어플리케이션 만들기 - LangChain이란 (0) | 2023.04.09 |
|---|---|
| ChatGPT란? - 기술과 활용법, 개인견해까지 (0) | 2023.02.16 |
| BERT - (4) BERT 이해하기 (0) | 2022.12.20 |
| BERT - (3) BERT의 기본 (0) | 2022.12.20 |
| BERT - (2) Transformer 이해하기, 코드 구현 (2) | 2022.12.13 |



