

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 미국 개발자 취업
- 머신러닝
- 합격후기
- MLOps
- BANDiT
- BERT
- 메타버스
- 클라우드
- chatGPT
- HTTP
- maang
- 네트워크
- 플랫폼
- AWS
- 자연어처리
- MAB
- BERT이해
- 추천시스템
- MSCS
- 미국석사
- transformer
- docker
- nlp
- swe취업
- RecSys
- 중국플랫폼
- llm
- 언어모델
- TFX
- 클라우드자격증
- Today
- Total
SWE Julie's life
BERT - (2) Transformer 이해하기, 코드 구현 본문
이전 글에서는 기계번역 도메인에서 선두를 이끌었던 NLP 모델들의 역사와 Attention 메커니즘에 대해 간단하게 살펴보았다. 이번 글은 BERT의 근간이 되는 Transformer 아키텍쳐에 대해 서술할 것이다.

논문에서 발췌한 아키텍쳐는 위와 같다. 왼쪽 블록은 인코더이고 오른쪽 블록은 디코더이다. Seq2Seq 모델에서 잠깐 설명했지만, 인코더는 인풋 시퀀스를 요약/학습하고 디코더는 타겟 시퀀스를 생성하는 역할을 한다.
Transformer 모델의 아키텍쳐는 인코더와 디코더가 유사하게 생겼다. 인코더 부분만 먼저 살펴보면, 인코더는 총 6개 동일한 레이어로 구성되어있고 각 레이어는 2개의 sub-layer로 나뉘게 된다. 첫 번째 레이어는 multi-head self-attention layer이고 두 번째 레이어는 fully connected feed-forward layer이다. 두 번째 레이어는 일반적인 NN 모델과 유사하지만 첫 번째 레이어가 Transformer 모델만의 특징이라고 볼 수 있다.
디코더는 인코더와 동일하게 총 6개의 레이어로 구성되어있지만 하나의 레이어는 3개의 sub-layer로 나뉘게 된다. Multi-head self-attention layer가 하나 더 포함이 되어있는데 이 sub-layer가 인코더의 output에 대한 multi-head attention을 수행하는 곳이다.
Embedding matrix
6가지 레이어가 동일한 구성이니 하나의 레이어만 놓고 보자. 아키텍쳐 그림에서 아래에서 위 방향으로 데이터 흐름이 구성된다고 생각하면 된다. 가장 처음에는 인풋 시퀀스를 embedding matrix로 변환하여 positional encoding이라는 벡터와 결합한다. 여기서 embedding matrix란 인풋 시퀀스를 컴퓨터가 알아들을 수 있도록 숫자로 변환한 행렬을 의미한다. 모델링을 하게 되면 본래 텍스트로 구성된 학습데이터를 각 단어에 대해 index로 변환하게 되는데, 이 때 index는 하나의 언어에 대한 distinct한 단어 집합(set)이라고 할 수 있는 Vocabulary에 따라 매핑되어 지정된다. 이 index 숫자들을 embedding matrix로 변환하도록 학습하는데, 이 embedding matrix는 단어별 embedding vector로 구성되어 있고 각 벡터는 연관도가 높은 단어일수록 벡터 공간에서 가깝게 위치하게끔 모델에서 학습된다. 아래 그림에서 볼 수 있듯 유사 단어인 cat과 kitten은 단순화된 벡터 공간에서 가깝게 있다.
Positional encoding
앞선 attention 메커니즘과는 달리 Transformer은 attention is all you need이기에 RNN 혹은 CNN을 사용하지 않고 순전히 attention 테크닉만을 사용한다. 때문에 각 단어의 순서에 대한 정보를 따로 얻을 수 없게 된다. RNN과 CNN처럼 순차적으로 들어오는 input의 순서에 따라서 처리하는 것이 아니라 전체를 통으로 받아 처리하는 것이다. 이 때문에 모델이 학습하는 속도도 굉장히 빨라졌고, Parallelization (병렬처리)도 가능하다고 이야기한다.
문장의 각 단어에 대한 위치 정보를 제공하기 위해서 Positional Encoding이라는 새로운 개념이 등장하여 인풋 시퀀스의 각 term의 위치 정보에 대해 모델이 학습할 수 있게 해준다. 이 positional encoding은 인코더와 디코더 모두에 사용된다. Positional Encoding을 만드는 식은 아래와 같이 생겼다.
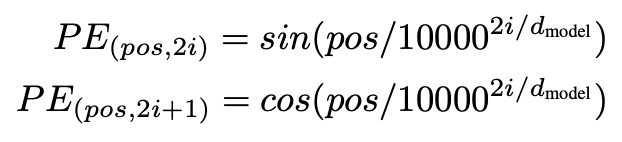
식이 복잡하게 생겼지만 결국 대표적인 주기함수인 sine, cosine 함수를 이용하는 것이다. 주기함수를 사용하는 이유는 Positional Encoding의 결과값이 위치 정보를 정확하게 반영하기 위해 어떤 특성이 있어야하는가를 고민해보면 쉽게 이해할 수 있다. 우선 가장 간단하게 떠올려볼 수 있는 것은 위치값의 차이 정도가 아웃풋 값의 차이 정도와 동일해야한다는 것이다. 만약 1번째 포지션과 2번째 포지션의 인코딩 값의 차이가 2번째 포지션과 3번째 포지션간의 인코딩 값의 차이와 다르게 되면 등간격을 반영하지 못하여 위치 인코딩이 사실상 불가하다. 따라서 간격이 일정하게 유지되는 곡선 형태의 함수를 사용하게 된다. 또한 Positional Encoding 값 그 자체가 너무 큰 값이어서도 안되고 (= input의 임베딩 값과 더해질텐데 위치 값이 크면 원본 데이터의 영향력이 상대적으로 하락한다) 위치가 다르면 각기 다른 값이어야한다.
Transformer 논문의 저자는 주기함수를 이용하여 등간격성을 유지하면서도 위치 값에 따라 다른 값을 지니게하고, 그 값 자체가 너무 크지 않게끔 조절하였다. 주기를 충분히 크게 만들어서 (1/10000) 위치 값에 따라 다른 값을 지니도록 만들었다.
이렇게 최종적으로 인풋 시퀀스의 embedding matrix와 positional encoding을 element-wise로 add하게되면 문장과 위치 정보를 함께 담게 담은 벡터가 생성되게 된다. 이 때 concatenate하는 방법도 있지만 단순하게 덧셈하게 되는 이유는 차원을 동일하게 유지하기 위해서이다. Concat의 방식을 이용하면 차원이 증가하지만 위치정보를 왜곡하지 않고 그대로 모델에 전달할 수 있게 된다. 그럼에도 불구하고 add방식을 채택한 이유는 차원 증가로 인해 발생할 수 있는 메모리 낭비나 런타임 증가를 막기 위해서이다. 만약 예산이 충분하고 GPU 성능도 좋은 경우 concatenate를 하는 것이 정보를 잃지 않는다는 이유로 더 좋다.
def create_positional_embedding(max_len, embed_dim):
'''
Args:
max_len: maximum length of the positional embeddings
embed_dim: embedding size
Returns:
pe: [max_len, 1, embed_dim]
'''
pe = torch.zeros(max_len, embed_dim)
pos = torch.arange(0, max_len).float().unsqueeze(dim=1)
i = torch.arange(0, embed_dim, step=2).float()
pe[:, 0::2] = torch.sin(pos / np.power(10000, i / embed_dim))
pe[:, 1::2] = torch.cos(pos / np.power(10000, i / embed_dim))
return pe.unsqueeze(1)Multi-head attention
Multi-head attention은 single-head attention을 여러 개 사용하는 것으로 하나의 attention value만을 사용하는 것이 아니라 여러 개를 병렬로 계산하여 합하는 접근방식이다. Attention의 원리가 그렇듯, Multi-head attention도 특정 단어가 해당 시퀀스 안에 있는 모든 다른 단어들에 대해 얼마나 focus (= pay attention to) 해야하는지에 대한 점수를 산출하게 된다.
논문에서는 단일 attention head만을 사용하는 것보다는 병렬로 합쳐 학습하는 것이 더 효과가 좋다고 보았는데, 그 증거가 되는 예시로 아래 그림에 있는 "The animal didn't cross the street because it was too tired." 라는 문장을 들 수 있다. Multi-head attention에서는 단일인 경우와 달리 'it'라는 단어에 대해서는 animal 과 tired 두 토큰 각각에 대해 attention하는 head를 만들 수 있는 것이다. 하나는 지시어로서 it이 가르키는 단어를 중요하다고 보았고, 다른 하나는 주어로서 상태를 표현하는 tired에 높은 값을 준 것이다. 즉 head 마다 문장의 정보를 읽는 시각이 다르다고 볼 수 있기 때문에 Multi-head attention 방식을 취하게 되었다.

논문에서는 디코더에는 레이어마다 2개씩, 인코더에는 1개씩 사용되었는데 좀 더 자세히 살펴보자.
d_model (=d) 차원의 단어 벡터를 h개 multi-head 모듈로 나누어 각 모듈에서 K, Q, V를 계산한 후 weight를 곱하여 다시 concatenate해주면 Multi-head attention의 output이 산출된다. 논문에서는 d가 512, h가 8로 셋팅되었다.

그럼 K, Q, V가 각각 의미하는 바는 무엇일까? 그것은 아래와 같이 Attention Score가 산출되는 과정을 살펴보면 이해할 수 있다. 입력 시퀀스가 "Thinking Machine" 두 단어로 구성되어있다고 치자. 그럼 각 단어에 대해 다른 단어들의 score를 계산해야한다. 첫 번째 포지션에 있는 "The"라는 단어에 대해 score를 연산한다고 가정하면, 시퀀스의 첫번째와 두번째 포지션에 있는 단어와 Self-attention을 계산하게 된다.
1. 첫 번째 score은 q1와 k1을, 두 번째 score은 q1과 k2에 대해 dot product를 구한다.
2. 이 두 score을 각각 key vector의 dimension의 루트값을 나누게 된다. (논문에 따르면 more stable gradient를 만들기 위함이라고 한다.)
3. 이 두 값에 대해 softmax를 계산하게 되면 attention score를 구하게 되는 것이다. 당연하게도 Thinking 단어에 대해서는 Thinking 단어 그 자체에 대한 score가 높다. 하지만 이 점수 외에 특정 단어가 다른 단어들에 비해 상대적으로 높은 점수를 보이면 그 단어가 thinking이라는 단어와 연관이 높다는 정보를 알 수 있게 된다.
4. softmax값을 value vector과 곱하게 된다. 그 이유는 우리가 3에서 구한 focus하고 싶은 단어들에 대해서는 원래의 값을 유지해주고, 관련 없는 것으로 보이는 다른 단어들에 대해서는 아주 작은 값을 곱해 좀 더 focus하고자 하는 단어들에 대해 중점을 둘 수 있도록 하기 위함이다.
5. 4에서 구한 weighted value vector를 모두 더하여 하나의 벡터로 만들어준다. 이 결과물이 첫 번째 포지션인 "Thinking"에 대한 attention layer에서의 output이다.
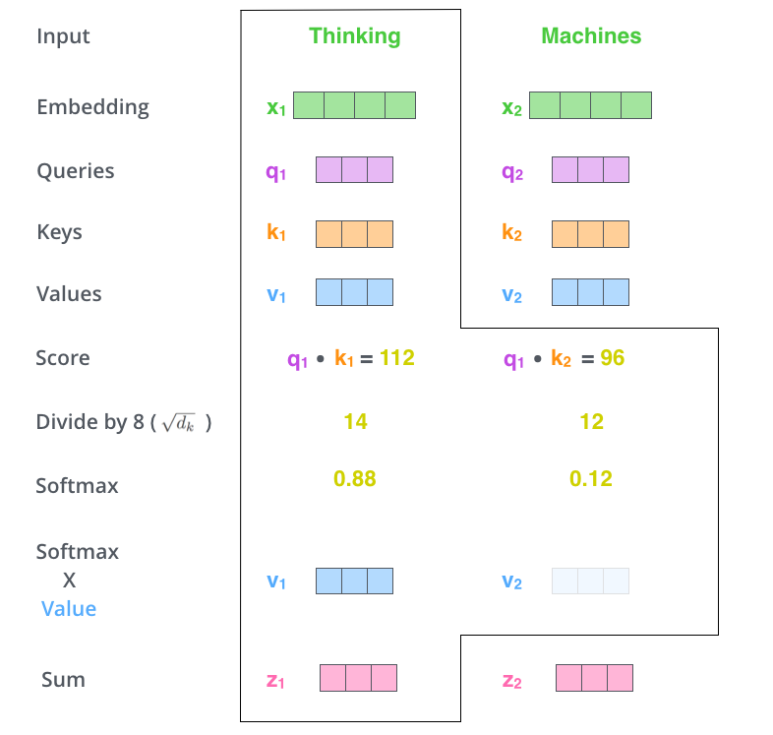
이 과정을 전체 시퀀스 t개에 대해 attention 레이어를 구성요소 단위로 나누어서 도식화하게 되면 아래와 같다.

인코더의 Multi-head attention 레이어는 인풋 시퀀스의 각 토큰이 다른 토큰과 연관성을 지니는 정도를 attention score로 계산하여 모델에게 제공한다. 이 output은 입력 문장의 정보에 대해 모델이 잘 학습할 수 있도록 도움을 준다.
디코더는 지금 시점의 토큰이 전체 Output sequence에서 어떤 토큰과 가장 연관성이 있는지 계산하는 Multi-head attention과, 인코더의 가장 마지막 아웃풋과 지금 시점의 토큰의 연관성을 담은 Multi-head attention 레이어, 이렇게 두 가지 레이어가 존재한다. 후자는 seq2seq with attention 모델처럼 입력 시퀀스에서 어떤 부분에 무게를 두어야하는지를 학습하는 것이다.
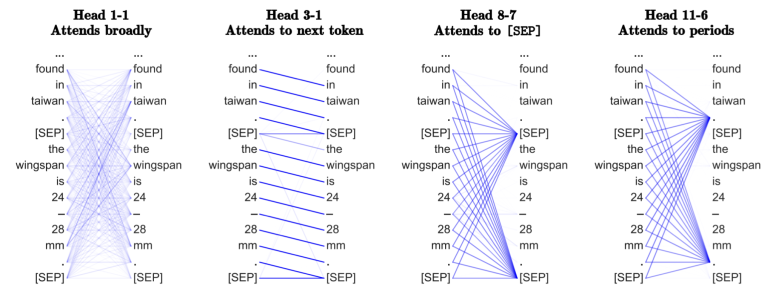
이렇게만 설명하게 된다면 Multi-head attention이 이 모델에서 왜 필요하며, 어떤 정보를 학습하는 것인지 자세히는 알기가 어렵다. 문장 내 연관성이 높은 단어를 학습한다는 용도는 이해하지만, 구체적으로 어떤 정보를 학습하게 되는지에 대해서는 대부분의 article이나 원 논문에도 언급이 없다. 나 역시 BERT 논문에 대해서 여러 가지를 찾다가 접하게 된 하나의 논문이 있는데, 그 논문이 이해를 하는데 큰 도움이 되어 짤막하게 소개하려고 한다. 해당 논문은 저자가 BERT의 Multi-head attention들이 어떤 언어적 지식을 습득하는지에 대해 시각화하여 서술한 내용이 담겨있다. 바로 다음 token에 대해 집중하는 head, 문장을 구분하는 [SEP] 에 집중하는 head (= 아무 토큰도 집중할 것이 없다는), 온점에 집중하는 head, 혹은 직접목적어에 대해 attention하는 head 등이 있다. 이 논문에서는 BERT의 attention head들은 영어의 syntactic structure (단어 단위의 문법적인 구조) 정보를 굉장히 잘 캐치하는 것으로 주장한다.

Add + norm
마지막은 Add + norm인데, 이 sub layer은 화살표가 두 가지이다. 이전 결과를 그대로 사용하는 것 같아 보이는 화살표가 있는데, 이는 잔여 학습 (residual learning)이라 부른다. 인코더의 가장 첫 Add + norm 레이어만 보아도 앞에서 계산된 임베딩 메트릭스와 positional encoding이 결합된 값을 그대로 multi-head attention을 건너 뛰어 인풋으로 넣게 된다.
Residual Learning / Skip Connection은 컴퓨터 비전 영역에서 레이어 개수가 많아질수록 모델의 깊이가 깊어지면서 gradient vanishing을 막기 위해(=정보 손실을 막기 위해) 이전 레이어의 결과를 그대로 사용하는 테크닉이다.
Normalization은 말 그대로 정규화 과정을 통해 output을 안정화하기 위함이다. 이 normalization 방법에도 여러가지가 있는데 대표적으로는 batch normalization 과 layer normalization이 있다. 전자는 여러 개의 sample(=batch)을 참고하여 정규화하는 방식이고, 후자는 하나의 layer내에서 정규화하는 방식이다. 이 방식들에 대해서는 깊이 있게 다루지 않고 간단히 언급하고 넘어가겠다.
Training
RNN기반 과거 모델들이 인풋 시퀀스를 순차적으로 받아 학습하던 것과는 달리 Transformer은 인풋 시퀀스를 통으로 입력받아 학습하게 된다. (그래서 parallelization이 가능하다고 말한다.) 따라서 디코더는 <eos> (=end of sentence) 토큰이 나올 때 까지 output을 출력하게 된다. 그리고 일반적으로 인코더와 디코더의 레이어 수를 동일하게 셋팅한다고 한다. 실제로 논문에서도 인코더와 디코더의 레이어는 6개로 설정되어있다.
아래는 PyTorch의 TransformerEncoder라는 클래스를 상속받아 좀 더 구체화하여 구현한 코드이다.
코드는 UIUC의 MCS-DS과정 CS447 NLP 강의(Prof. Hockenmaier)의 과제를 참조하여 조금 수정되었다.
class TransformerEncoder(nn.Module):
def __init__(self, src_vocab, embedding_dim, num_heads,
num_layers, dim_feedforward, max_len_src, device):
super(TransformerEncoder, self).__init__()
self.device = device
"""
Args:
src_vocab: vocab
embedding_dim: The size of the embedding
num_heads: The number of attention heads
num_layers: The number of Transformer Encoder layers
dim_feedforward: The dimension of the feedforward network
max_len_src: maximum length of the source sentences
"""
self.src_vocab = src_vocab
src_vocab_size = len(src_vocab)
# Positional embedding
self.position_embedding = create_positional_embedding(max_len_src, embedding_dim).to(device)
self.register_buffer('positional_embedding', self.position_embedding)
# 모델에게 position_embedding 이 학습하는 변수가 아님을 알려줌
# Embedding layer
self.embedding = nn.Embedding(src_vocab_size, embedding_dim).to(device)
# Dropout layer
self.dropout = nn.Dropout().to(device)
# Encoder layer
encoder_layer = nn.TransformerEncoderLayer(embedding_dim, num_heads, dim_feedforward).to(device)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers).to(device)
def make_src_mask(self, src):
"""
Args:
src: [max_len, batch_size]
Returns:
[batch_size, max_len] 크기의 matrix, Boolean값이 들어가있음 (1 = masking, 0 = nothing)
"""
assert len(src.shape) == 2,
src_mask = src.transpose(0, 1) == 0 # padding index
return src_mask.to(self.device) # [batch_size, max_src_len]
def forward(self, x):
"""
Args:
x: [max_len, batch_size]
Returns:
output: [max_len, batch_size, embed_dim]
"""
embed = self.embedding(x.to(self.device)).to(self.device)
dropout = self.dropout(embed + self.position_embedding[:embed.shape[0], :, :])
src_mask = self.make_src_mask(x)
output = self.transformer_encoder(dropout, src_key_padding_mask = src_mask)
return outputclass TransformerDecoder(nn.Module):
def __init__(self, trg_vocab, embedding_dim, num_heads,
num_layers, dim_feedforward, max_len_trg, device):
super(TransformerDecoder, self).__init__()
self.device = device
"""
Args:
trg_vocab: vocab
embedding_dim: The size of the embedding
num_heads: The number of attention heads
num_layers: The number of decoder layers
dim_feedforward: The dimension of the feedforward network
max_len_trg: maximum length of the target sentences
"""
self.trg_vocab = trg_vocab
trg_vocab_size = len(trg_vocab)
# Positional embedding
self.position_embedding = create_positional_embedding(max_len_trg, embedding_dim).to(device)
self.register_buffer('positional_embedding', self.position_embedding)
# Embedding layer
self.embedding = nn.Embedding(trg_vocab_size, embedding_dim).to(device)
# Dropout layer
self.dropout = nn.Dropout().to(device)
# Decoder layer
decoder_layer = nn.TransformerDecoderLayer(embedding_dim, num_heads, dim_feedforward).to(device)
self.transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers).to(device)
# Fully connected layer
self.fc = nn.Linear(embedding_dim, trg_vocab_size).to(device)
def generate_square_subsequent_mask(self, sz):
"""Generate a square mask for the sequence. The masked positions are filled with float('-inf').
Unmasked positions are filled with float(0.0).
"""
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0)).to(self.device)
return mask
def forward(self, dec_in, enc_out):
"""
Args:
dec_in: [sequence length, batch_size]
enc_out: [max_len, batch_size, embed_dim]
Returns:
output: [sequence length, batch_size, trg_vocab_size]
embed = self.embedding(dec_in.to(self.device)).to(self.device)
dropout = self.dropout(embed+self.position_embedding[:embed.shape[0],:,:].to(self.device)).to(self.device)
trg_mask = self.generate_square_subsequent_mask(dec_in.shape[0]).to(self.device)
output = self.transformer_decoder(dropout, enc_out.to(self.device), tgt_mask = trg_mask).to(self.device)
output = self.fc(output).to(self.device)
return output이번 글은 Transformer의 아키텍쳐를 하나씩 살펴보며 BERT의 근간에 대해 조금 이해해볼 수 있었다. 다음 글은 BERT에 대해 본격적으로 다루면서 그의 변천사(Variant) 중 하나인 ALBERT에 대해 간단히 살펴볼 것이다.
추가로 아래 블로그가 시각적으로 Transformer을 쉽게 이해할 수 있도록 설명해두었다.
'Tech > ML, DL' 카테고리의 다른 글
| BERT - (4) BERT 이해하기 (0) | 2022.12.20 |
|---|---|
| BERT - (3) BERT의 기본 (0) | 2022.12.20 |
| BERT - (1) Background, Attention 이해하기 (4) | 2022.12.13 |
| 불균형(imbalanced) 데이터 모델링은 ROC curve를 사용을 추천하지 않는 이유 (0) | 2022.06.24 |
| 이상탐지, Anomaly Detection (0) | 2022.06.12 |



