
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- HTTP
- 네트워크
- llm
- BERT이해
- transformer
- maang
- nlp
- docker
- swe취업
- BANDiT
- MLOps
- 클라우드자격증
- 자연어처리
- 미국 개발자 취업
- 클라우드
- 미국석사
- 중국플랫폼
- RecSys
- TFX
- 합격후기
- 머신러닝
- chatGPT
- BERT
- MAB
- 플랫폼
- 언어모델
- MSCS
- 추천시스템
- 메타버스
- AWS
- Today
- Total
SWE Julie's life
BERT - (3) BERT의 기본 본문
BERT는 Bidirectional Encoder Representations from Transformer로서 기존 Transformer 모델의 인코더만을 채택하여 사용한다. 논문에서는 Transformer의 인코더와 BERT의 인코더가 크게 다르지 않다고 언급하고 있어 BERT의 특징인 'Bidirectionality'에 대해서 중점적으로 이야기해볼 것이다.
BERT는 기존의 NLP 모델들이 'Unidirectional(단방향)'했다는 것과 다르게 양방향성을 띄고 있다.
이를 예시를 들어 설명하면 아래와 같다.
- I can't trust you.
- They have no trust left for their friends.
- He has a trust fund.
여기서 BERT는 다른 모델들과 다르게 각 문장에서의 trust 단어 임베딩 결과를 다르게 뱉게 되는데 그 이유는 해당 단어가 각 문장에서 사용된 의미와 그 주변 context가 모두 다르기 때문이다. 즉 BERT는 input sequence의 순차에 따라 단어를 왼쪽 → 오른쪽 방향으로 읽는 것이 아니라 오른쪽 ← 왼쪽 방향으로도 이해할 수 있기 때문에 특정 단어의 주변 단어들에 대한 정보를 갖고 있게 된다. 양방향에서의 문맥(context) 정보를 합칠 수 있는 것이 BERT의 장점이다.
실제로 논문에 첨부된 GLUE 데이터셋에 대한 성능표를 보면 질의응답(Question-Answering), 요약(Summarization), 감정 분류(Sentiment Detection)와 같은 task에 우수한 성능을 보인다.



BERT의 우수한 성능은 양방향성에서만 기인하는 것은 아니다. 다른 여러 가지 테크닉들이 사용되었는데, 각각에 대해서 하나씩 살펴보자.
우선 input sequence의 표현'(=representation) 형태에 대해 살펴보자면, BERT는 단일 문장과 한 쌍의 문장 모두 하나의 token sequence로 표현이 가능하다. NLP에서 사용하는 문장의 시작 토큰인 [SOS], 끝인 [EOS] 대신 [CLS] 토큰(Special Classification Token)과 [SEP] 토큰(Special Separator Token)을 추가하였다. [SEP] 토큰은 두 개 이상의 문장을 구분하는 용도로 주로 사용되었다. 따라서 논문에서 말하는 'sequence'는 하나 이상의 문장이 될 수 있는 것이다.
'적절하게 번역할 단어가 없다. 인풋 시퀀스를 임베딩한 결과
BERT는 미리 학습된 모델이 제공되고 있어 분석가가 사실상 downstream task (=BERT를 활용하여 풀고자 하는 문제)에 맞게 간단한 fine-tuning만 진행하면 된다. 논문에서는 pre-training step과 GLUE dataset을 통해 테스트한 fine-tuning step 각각의 섹션이 나뉘어 설명되고 있다. BERT의 Pre-training은 큰 규모의 Wikipedia, BooksCorpus의 단어(word) 데이터를 사용하였다.
Pre-training은 정답지가 없는 데이터 (Unlabeled data)를 이용해서 진행했고, fine-tuning 단계에서는 pre-trainining 단계에서 학습한 파라미터 값들로 초기화(initialize)한 뒤 downstream task의 각 정답지 데이터(labeled data)를 이용하여 파라미터 최적화를 진행했다고 한다. 이 두 step은 사실 동일한 아키텍쳐(=unified architecture)를 기반으로 하고 있어 아키텍쳐 차이는 사실 미미하다고 한다. 유일한 차이는 Output layer라고 한다.
이렇게 미리 학습된 BERT는 두 가지 종류로 나뉘어 제공되는데,
1) BERT_BASE : L=12, H=768, A=12, Total Parameters=110M
2) BERT_LARGE : L=24, H=1024, A=16, Total Parameters=340M
이 중 모델 depth가 있는 BERT_LARGE가 좀 더 복잡한 task를 수행하는데 좋은 성능을 보이는 편이다.
아래 첨부된 사진은 BERT의 정보를 한 눈에 볼 수 있도록 쉽게 요약한 도식화 장표이다.
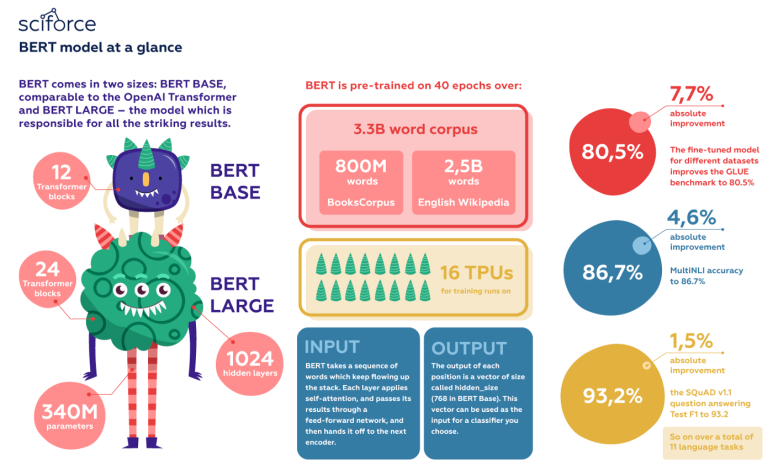
BERT의 Pre-training단계에서는 두 가지 테크닉이 활용되었다: Masked Language Model (MLM), Next Sentence Prediction (NSP). 그리고 이 두 가지 테크닉을 이해하는 것은 BERT가 어떠한 언어적 지식을 캐치할 수 있는지를 이해하는 데 큰 역할을 한다.
Masked Language Model (MLM)
모델이 학습 데이터 중 sequence에 있는 단어들을 특정 퍼센티지만큼 masking하여 학습하는 것이다. 예를 들어 "I am a student"에서 랜덤하게 하나의 단어만을 masking한다고 했을 때 "student"라는 단어가 선택되었다면 "I am a [mask]"로 sequence를 대체한 후에 BERT에게 [mask] 토큰에 들어갈 원래의 단어가 무엇인지를 예측하도록 학습시킨다. 논문에서는 15%로 퍼센티지를 잡았다고 되어있다.
MLM의 핵심은 시퀀스내에 존재하는 다른 단어들을 기반으로 특정 단어를 예측하도록 하기 때문에 모델이 학습 회차를 거듭하면서 context를 이해하게 된다고 한다. 이렇듯 장점은 있지만 조금만 더 생각해보면 두 가지 단점이 떠오를 수 있다.
첫째는 학습데이터에서 [mask] 토큰을 임의로 생성하여 학습시켰지만, 추론시에는 [mask] 토큰을 예측하는 것이 목적이 아니기 때문에 학습과 추론 과정에서의 불일치(mismatch)가 발생할 수 있다는 것이다. 이에 대응하기 위해 masking할 단어를 모든 step에서 [mask] 토큰으로 대체하지는 않았다. i번째 토큰을 masking하기로 결정되었다면 80%의 시간동안에만 [mask]토큰으로 변경하고 나머지 10%는 아예 랜덤 단어, 또 나머지 10%는 원래 단어로 설정하여 학습시켰다 (이마저도 15%의 확률로 마스킹하는 것이니 각각 1.5%, 1.5%, 12%인 것이다). 이 과정에서 원래의 토큰과의 cross entropy loss를 줄이는 방향으로 모델이 학습하게 된다.
두 번째는 논문에서 등장하진 않지만 이후 BERT를 개선하고자 제안된 논문들에서 제시하는 문제점으로, 꼭 유용한 단어가 masking되는 것은 아니라는 점이다. 대부분의 무의미한 (a, the, I, you 등) 단어들이 [mask] 대상으로 선택되기 때문에 MLM의 주요 목적인 컨텍스트를 이해하게끔 학습한다는 방향성이 달성되기 어렵다는 문제제기이다. 이를 해결하기 위한 여러 다른 대안이 제안되기도 한다.
Next Sentence Prediction (NSP)
모델이 한 쌍의 문장이 연속적(sequential)한지 아닌지에 대해 판별하도록 학습하는 것이다. 예를 들어 아래와 같은 한 쌍이 있다고 치자.
(1) “She’s a star in her field.
(2) Everyone wants to work with her, are subsequential, as the second sentence follows the first.
이 때 NSP는 (2)번 문장을 말뭉치(corpus)에 있는 아예 다른 랜덤한 문장으로 바꾼 뒤 모델에게 흐름상 연결이 되는지 안되는지를 물어본다. 논문에서는 랜덤한 문장으로 바꿀 확률은 50%로 설정되었다. 만약 연속적인 문장들로 구성되었다면 "IsNext"로 라벨링하고, 그렇지 않을 경우 "NotNext"로 라벨링하여 two-class classification 문제를 풀도록 모델이 학습되었다.
다음 글에서는 BERT를 좀 더 이해하기 위해 BERT 자체를 연구한 논문들을 간략하게 리뷰한 내용이 담길 예정이다.
'Tech > ML, DL' 카테고리의 다른 글
| Inductive Bias : ML/DL 모델 디자인에 대하여 (0) | 2023.01.12 |
|---|---|
| BERT - (4) BERT 이해하기 (0) | 2022.12.20 |
| BERT - (2) Transformer 이해하기, 코드 구현 (2) | 2022.12.13 |
| BERT - (1) Background, Attention 이해하기 (4) | 2022.12.13 |
| 불균형(imbalanced) 데이터 모델링은 ROC curve를 사용을 추천하지 않는 이유 (0) | 2022.06.24 |



