

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- MAB
- maang
- 메타버스
- BERT
- 클라우드
- 미국 개발자 취업
- 중국플랫폼
- BANDiT
- docker
- 자연어처리
- RecSys
- AWS
- 언어모델
- chatGPT
- transformer
- 플랫폼
- llm
- 네트워크
- HTTP
- 클라우드자격증
- 합격후기
- swe취업
- 추천시스템
- MLOps
- TFX
- nlp
- MSCS
- 미국석사
- 머신러닝
- BERT이해
- Today
- Total
목록BERT (5)
SWE Julie's life
 BERT4Rec - 추천시스템과 BERT
BERT4Rec - 추천시스템과 BERT
추천시스템과 자연어처리 모델은 함께 떠올리기 쉽지 않다. 우리가 통상 생각하는 추천시스템은 아이템과 유저를 대상으로 하는데, 자연어처리 모델은 언어를 대상으로 하기 때문이다. 하지만 몇몇 사람들은 자연어처리 모델을 추천시스템에 적용해보기를 시도했다. 그 이유는 유저가 순차적인 이벤트(혹은 activity)를 발생시키는 경우 순차성을 지닌 텍스트 데이터와 유사한 속성을 지닌 데이터로 여길 수 있기 때문이다. 그 외에도 유저의 반응(implicit 혹은 explicit feedback)이 희소(sparse)하다는 것과 one-hot encoding으로 데이터를 임베딩한다는 것이 유사점으로 꼽을 수 있다. 딥러닝 언어 모델이 점차적으로 발전해나가면서 순차적인(Sequential) 추천 모델도 함께 발전..
 BERT - (4) BERT 이해하기
BERT - (4) BERT 이해하기
BERT는 뛰어난 성능을 보이지만 아이러니하게도 어떤 요소로 인해 그러한 성능이 발휘되는지에 대해서는 정확히 판별할 수 없는 상황이다. 모델이 문맥을 이해하는 듯 하여 언어적인 지식을 습득하는 것 같은데, 파라미터 수와 모델의 depth로 인해 워낙 큰 모델이다보니 어떤 특성을 갖는지 분석하기가 어렵다. 따라서 BERT와 관련하여 연구된 논문 150가지 이상을 리뷰한 또 다른 논문이 등장하게 된다. 그 논문이 BERTology인데, 이 논문은 아래와 같은 내용을 중점적으로 다룬다. BERT 연구가 어떻게 진행되었고, 진행되고 있는지 BERT가 어떻게 동작하는지, 어떤 정보를 학습하는지, input이 어떻게 represent되는지, 파라미터 거대화(overparameterization issue)와 그..
 BERT - (3) BERT의 기본
BERT - (3) BERT의 기본
BERT는 Bidirectional Encoder Representations from Transformer로서 기존 Transformer 모델의 인코더만을 채택하여 사용한다. 논문에서는 Transformer의 인코더와 BERT의 인코더가 크게 다르지 않다고 언급하고 있어 BERT의 특징인 'Bidirectionality'에 대해서 중점적으로 이야기해볼 것이다. BERT는 기존의 NLP 모델들이 'Unidirectional(단방향)'했다는 것과 다르게 양방향성을 띄고 있다. 이를 예시를 들어 설명하면 아래와 같다. I can't trust you. They have no trust left for their friends. He has a trust fund. 여기서 BERT는 다른 모델들과 ..
 BERT - (2) Transformer 이해하기, 코드 구현
BERT - (2) Transformer 이해하기, 코드 구현
이전 글에서는 기계번역 도메인에서 선두를 이끌었던 NLP 모델들의 역사와 Attention 메커니즘에 대해 간단하게 살펴보았다. 이번 글은 BERT의 근간이 되는 Transformer 아키텍쳐에 대해 서술할 것이다. 논문에서 발췌한 아키텍쳐는 위와 같다. 왼쪽 블록은 인코더이고 오른쪽 블록은 디코더이다. Seq2Seq 모델에서 잠깐 설명했지만, 인코더는 인풋 시퀀스를 요약/학습하고 디코더는 타겟 시퀀스를 생성하는 역할을 한다. Transformer 모델의 아키텍쳐는 인코더와 디코더가 유사하게 생겼다. 인코더 부분만 먼저 살펴보면, 인코더는 총 6개 동일한 레이어로 구성되어있고 각 레이어는 2개의 sub-layer로 나뉘게 된다. 첫 번째 레이어는 multi-head self-attention laye..
 BERT - (1) Background, Attention 이해하기
BERT - (1) Background, Attention 이해하기
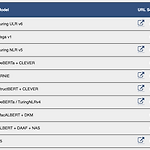
Background 요즈음의 Machine Translation (MT)의 최신 모델들은 모두 BERT 혹은 BERT의 확장판을 기반으로 하고 있다. 실제로 NLP의 여러 Task들에 대한 최신 NLP모델들의 성능을 리더보드로 제공하는 Glue Benchmark(https://gluebenchmark.com/leaderboard)를 살펴보면, 대부분의 모델명에 BERT가 포함되어있는 것을 쉽게 확인할 수 있다. 따라서 NLP에 대한 이해를 하기 위해서는 BERT를 이해하는 것이 매우 중요하다고 할 수 있다. 최근에 화제가 되고있는 GPT와 BERT는 모두 Transformer 아키텍쳐를 채택하고 있다. 그렇기에 우리가 BERT를 이해하기 앞서서 Transformer 아키텍쳐를 살펴볼 필요가 있다. 오..