
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 중국플랫폼
- 플랫폼
- RecSys
- 언어모델
- TFX
- 클라우드자격증
- transformer
- BANDiT
- 합격후기
- chatGPT
- llm
- 메타버스
- docker
- BERT
- swe취업
- AWS
- BERT이해
- HTTP
- MAB
- maang
- MSCS
- 네트워크
- 머신러닝
- 추천시스템
- 미국석사
- 미국 개발자 취업
- MLOps
- 클라우드
- nlp
- 자연어처리
- Today
- Total
목록Tech/ML, DL (38)
SWE Julie's life
 BERT - (3) BERT의 기본
BERT - (3) BERT의 기본
BERT는 Bidirectional Encoder Representations from Transformer로서 기존 Transformer 모델의 인코더만을 채택하여 사용한다. 논문에서는 Transformer의 인코더와 BERT의 인코더가 크게 다르지 않다고 언급하고 있어 BERT의 특징인 'Bidirectionality'에 대해서 중점적으로 이야기해볼 것이다. BERT는 기존의 NLP 모델들이 'Unidirectional(단방향)'했다는 것과 다르게 양방향성을 띄고 있다. 이를 예시를 들어 설명하면 아래와 같다. I can't trust you. They have no trust left for their friends. He has a trust fund. 여기서 BERT는 다른 모델들과 ..
 BERT - (2) Transformer 이해하기, 코드 구현
BERT - (2) Transformer 이해하기, 코드 구현
이전 글에서는 기계번역 도메인에서 선두를 이끌었던 NLP 모델들의 역사와 Attention 메커니즘에 대해 간단하게 살펴보았다. 이번 글은 BERT의 근간이 되는 Transformer 아키텍쳐에 대해 서술할 것이다. 논문에서 발췌한 아키텍쳐는 위와 같다. 왼쪽 블록은 인코더이고 오른쪽 블록은 디코더이다. Seq2Seq 모델에서 잠깐 설명했지만, 인코더는 인풋 시퀀스를 요약/학습하고 디코더는 타겟 시퀀스를 생성하는 역할을 한다. Transformer 모델의 아키텍쳐는 인코더와 디코더가 유사하게 생겼다. 인코더 부분만 먼저 살펴보면, 인코더는 총 6개 동일한 레이어로 구성되어있고 각 레이어는 2개의 sub-layer로 나뉘게 된다. 첫 번째 레이어는 multi-head self-attention laye..
 BERT - (1) Background, Attention 이해하기
BERT - (1) Background, Attention 이해하기
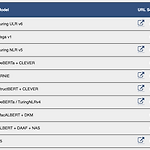
Background 요즈음의 Machine Translation (MT)의 최신 모델들은 모두 BERT 혹은 BERT의 확장판을 기반으로 하고 있다. 실제로 NLP의 여러 Task들에 대한 최신 NLP모델들의 성능을 리더보드로 제공하는 Glue Benchmark(https://gluebenchmark.com/leaderboard)를 살펴보면, 대부분의 모델명에 BERT가 포함되어있는 것을 쉽게 확인할 수 있다. 따라서 NLP에 대한 이해를 하기 위해서는 BERT를 이해하는 것이 매우 중요하다고 할 수 있다. 최근에 화제가 되고있는 GPT와 BERT는 모두 Transformer 아키텍쳐를 채택하고 있다. 그렇기에 우리가 BERT를 이해하기 앞서서 Transformer 아키텍쳐를 살펴볼 필요가 있다. 오..
 불균형(imbalanced) 데이터 모델링은 ROC curve를 사용을 추천하지 않는 이유
불균형(imbalanced) 데이터 모델링은 ROC curve를 사용을 추천하지 않는 이유
이번 글은 모델링 영역 중에서도 모델 성능 고도화를 위한 일종의 팁 같은 글이 될 것 같다. 우리는 데이터 과제를 하다 보면 불균형 데이터셋을 접할 일이 굉장히 많다. 여기서 말하는 불균형이란, 클래스 비중이 다르다는 것이다. 예를 들어 이진 분류 문제일 경우 0인 클래스와 1인 클래스를 분류하게 되는데, 일반적으로 우리가 추론하고자 하는 타겟 클래스인 1 클래스는 0 클래스에 비해 데이터 수가 적다. 단순히 생각하면 모델은 학습 데이터량이 많을 수록 좋은데, 데이터가 적은 경우 우리가 원하고자 하는 정답을 모델이 찾기 어려워지는 것이다. 모델이 Anomaly Detection과 같이 이상치를 분류하는 거라면 상황은 더 심각해진다. 모델을 설계하다보면 늘 '샘플링'의 고민을 마주하게 된다. 학습데..
 이상탐지, Anomaly Detection
이상탐지, Anomaly Detection
우리는 생각보다 빈번히 특정 데이터가 이상 데이터인지를 판단해야한다. 이러한 경우에는 분류 모델로도 접근할 수 있지만, 이상탐지 모델이 더 적합할 때가 있다. 이상탐지 모델은 흔히 공정 과정에서 생산되는 이미지 데이터에 적용하는 경우가 많다. 실제로 대표적인 이상탐지 모델들은 딥러닝계열 모델들이다. 그외엔 시계열 데이터에 적용되는 모델들이 있다. 시계열 데이터도 공정과 같은 일정한 프로세스에서 생산된 데이터를 시간 기반으로 놓고 어떤 부분에서 특이 패턴이 나타나는지를 탐지한다. 좀 더 리서치를 해보면 이 외에도 더 많은 분야에서 이상탐지 모델들을 활용하곤 한다. 실제로 카드사에서도 고객들의 카드결제 내역을 바탕으로 이상탐지를 판단할 때가 있다고 한다. 전통적인 이상감지 방법은 세 가지가 있다...
 Catboost 모델에 대하여 - 알고리즘, 구현 코드
Catboost 모델에 대하여 - 알고리즘, 구현 코드
요즘 흔하게 많이 사용되는 Catboost 모델에 대해서 정리하려고 한다. Catboost는 이름에서도 유추할 수 있듯 boosting 앙상블 기법을 사용하는 모델 중 하나이다. 논문에서는 이렇게 Catboost를 소개한다고 한다. "CatBoost is a high-performance open source library for gradient boosting on decision trees." 이전에 앙상블과 Gradient Boosting 모델에 대해 정리한 글이 있는데 알고 읽으면 좀 더 도움이 된다. https://blog.naver.com/ilovelatale/222320553535 Boosting vs Bagging 다시 간단하게 정리하자면 앙상블의 기법 중에서는 Boosting과 Bag..